 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecover Cell Tensor: Diffusion-Equivalent Tensor Completion for Fluorescence Microscopy Imaging
Jan 27, 2026Fluorescence microscopy (FM) imaging is a fundamental technique for observing live cell division, one of the most essential processes in the cycle of life and death. Observing 3D live cells requires scanning through the cell volume while minimizing lethal phototoxicity. That limits acquisition time and results in sparsely sampled volumes with anisotropic resolution and high noise. Existing image restoration methods, primarily based on inverse problem modeling, assume known and stable degradation processes and struggle under such conditions, especially in the absence of high-quality reference volumes. In this paper, from a new perspective, we propose a novel tensor completion framework tailored to the nature of FM imaging, which inherently involves nonlinear signal degradation and incomplete observations. Specifically, FM imaging with equidistant Z-axis sampling is essentially a tensor completion task under a uniformly random sampling condition. On one hand, we derive the theoretical lower bound for exact cell tensor completion, validating the feasibility of accurately recovering 3D cell tensor. On the other hand, we reformulate the tensor completion problem as a mathematically equivalent score-based generative model. By incorporating structural consistency priors, the generative trajectory is effectively guided toward denoised and geometrically coherent reconstructions. Our method demonstrates state-of-the-art performance on SR-CACO-2 and three real \textit{in vivo} cellular datasets, showing substantial improvements in both signal-to-noise ratio and structural fidelity.
SoS1: O1 and R1-Like Reasoning LLMs are Sum-of-Square Solvers
Feb 27, 2025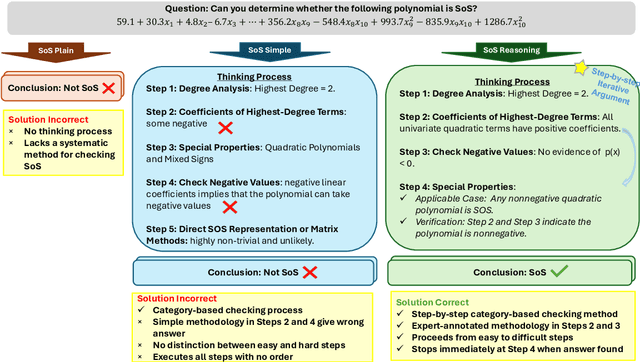
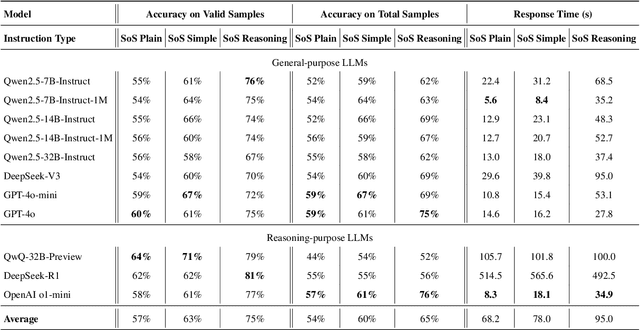
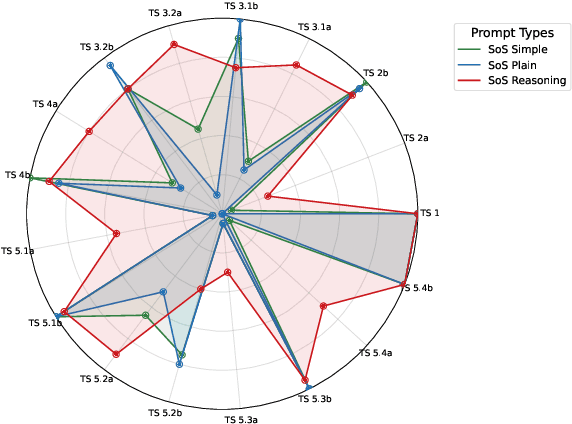
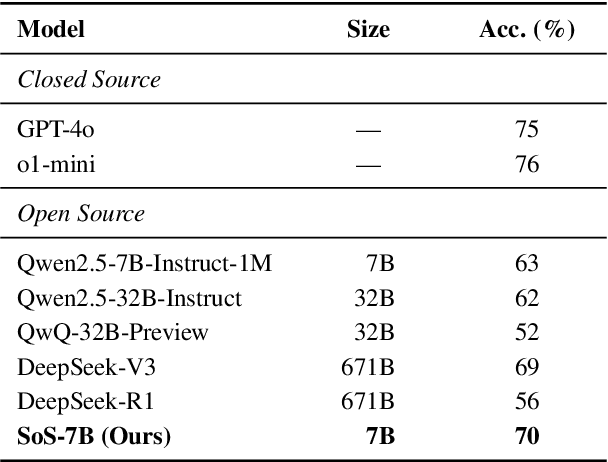
Large Language Models (LLMs) have achieved human-level proficiency across diverse tasks, but their ability to perform rigorous mathematical problem solving remains an open challenge. In this work, we investigate a fundamental yet computationally intractable problem: determining whether a given multivariate polynomial is nonnegative. This problem, closely related to Hilbert's Seventeenth Problem, plays a crucial role in global polynomial optimization and has applications in various fields. First, we introduce SoS-1K, a meticulously curated dataset of approximately 1,000 polynomials, along with expert-designed reasoning instructions based on five progressively challenging criteria. Evaluating multiple state-of-the-art LLMs, we find that without structured guidance, all models perform only slightly above the random guess baseline 50%. However, high-quality reasoning instructions significantly improve accuracy, boosting performance up to 81%. Furthermore, our 7B model, SoS-7B, fine-tuned on SoS-1K for just 4 hours, outperforms the 671B DeepSeek-V3 and GPT-4o-mini in accuracy while only requiring 1.8% and 5% of the computation time needed for letters, respectively. Our findings highlight the potential of LLMs to push the boundaries of mathematical reasoning and tackle NP-hard problems.
VideoGLaMM: A Large Multimodal Model for Pixel-Level Visual Grounding in Videos
Nov 07, 2024



Fine-grained alignment between videos and text is challenging due to complex spatial and temporal dynamics in videos. Existing video-based Large Multimodal Models (LMMs) handle basic conversations but struggle with precise pixel-level grounding in videos. To address this, we introduce VideoGLaMM, a LMM designed for fine-grained pixel-level grounding in videos based on user-provided textual inputs. Our design seamlessly connects three key components: a Large Language Model, a dual vision encoder that emphasizes both spatial and temporal details, and a spatio-temporal decoder for accurate mask generation. This connection is facilitated via tunable V-L and L-V adapters that enable close Vision-Language (VL) alignment. The architecture is trained to synchronize both spatial and temporal elements of video content with textual instructions. To enable fine-grained grounding, we curate a multimodal dataset featuring detailed visually-grounded conversations using a semiautomatic annotation pipeline, resulting in a diverse set of 38k video-QA triplets along with 83k objects and 671k masks. We evaluate VideoGLaMM on three challenging tasks: Grounded Conversation Generation, Visual Grounding, and Referring Video Segmentation. Experimental results show that our model consistently outperforms existing approaches across all three tasks.
MLC-GCN: Multi-Level Generated Connectome Based GCN for AD Analysis
Aug 06, 2024Alzheimer's Disease (AD) is a currently incurable neurodegeneartive disease. Accurately detecting AD, especially in the early stage, represents a high research priority. AD is characterized by progressive cognitive impairments that are related to alterations in brain functional connectivity (FC). Based on this association, many studies have been published over the decades using FC and machine learning to differentiate AD from healthy aging. The most recent development in this detection method highlights the use of graph neural network (GNN) as the brain functionality analysis. In this paper, we proposed a stack of spatio-temporal feature extraction and graph generation based AD classification model using resting state fMRI. The proposed multi-level generated connectome (MLC) based graph convolutional network (GCN) (MLC-GCN) contains a multi-graph generation block and a GCN prediction block. The multi-graph generation block consists of a hierarchy of spatio-temporal feature extraction layers for extracting spatio-temporal rsfMRI features at different depths and building the corresponding connectomes. The GCN prediction block takes the learned multi-level connectomes to build and optimize GCNs at each level and concatenates the learned graphical features as the final predicting features for AD classification. Through independent cohort validations, MLC-GCN shows better performance for differentiating MCI, AD, and normal aging than state-of-art GCN and rsfMRI based AD classifiers. The proposed MLC-GCN also showed high explainability in terms of learning clinically reasonable connectome node and connectivity features from two independent datasets. While we only tested MLC-GCN on AD, the basic rsfMRI-based multi-level learned GCN based outcome prediction strategy is valid for other diseases or clinical outcomes.
CLIP-VIS: Adapting CLIP for Open-Vocabulary Video Instance Segmentation
Mar 19, 2024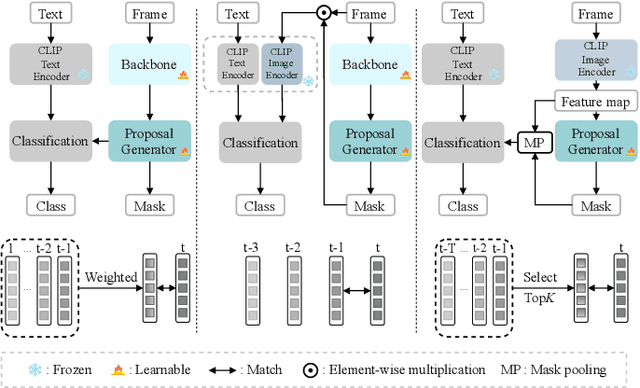
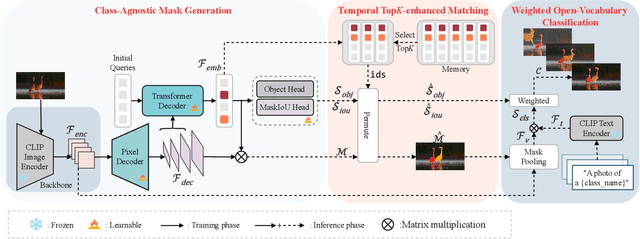
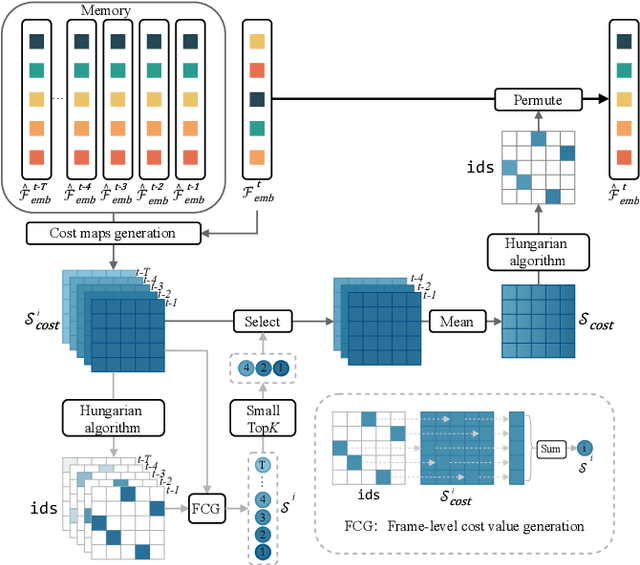

Open-vocabulary video instance segmentation strives to segment and track instances belonging to an open set of categories in a video. The vision-language model Contrastive Language-Image Pre-training (CLIP) has shown strong zero-shot classification ability in image-level open-vocabulary task. In this paper, we propose a simple encoder-decoder network, called CLIP-VIS, to adapt CLIP for open-vocabulary video instance segmentation. Our CLIP-VIS adopts frozen CLIP image encoder and introduces three modules, including class-agnostic mask generation, temporal topK-enhanced matching, and weighted open-vocabulary classification. Given a set of initial queries, class-agnostic mask generation employs a transformer decoder to predict query masks and corresponding object scores and mask IoU scores. Then, temporal topK-enhanced matching performs query matching across frames by using K mostly matched frames. Finally, weighted open-vocabulary classification first generates query visual features with mask pooling, and second performs weighted classification using object scores and mask IoU scores. Our CLIP-VIS does not require the annotations of instance categories and identities. The experiments are performed on various video instance segmentation datasets, which demonstrate the effectiveness of our proposed method, especially on novel categories. When using ConvNeXt-B as backbone, our CLIP-VIS achieves the AP and APn scores of 32.1% and 40.3% on validation set of LV-VIS dataset, which outperforms OV2Seg by 11.0% and 24.0% respectively. We will release the source code and models at https://github.com/zwq456/CLIP-VIS.git.
Sparse-Dense Subspace Clustering
Oct 20, 2019



Subspace clustering refers to the problem of clustering high-dimensional data into a union of low-dimensional subspaces. Current subspace clustering approaches are usually based on a two-stage framework. In the first stage, an affinity matrix is generated from data. In the second one, spectral clustering is applied on the affinity matrix. However, the affinity matrix produced by two-stage methods cannot fully reveal the similarity between data points from the same subspace (intra-subspace similarity), resulting in inaccurate clustering. Besides, most approaches fail to solve large-scale clustering problems due to poor efficiency. In this paper, we first propose a new scalable sparse method called Iterative Maximum Correlation (IMC) to learn the affinity matrix from data. Then we develop Piecewise Correlation Estimation (PCE) to densify the intra-subspace similarity produced by IMC. Finally we extend our work into a Sparse-Dense Subspace Clustering (SDSC) framework with a dense stage to optimize the affinity matrix for two-stage methods. We show that IMC is efficient when clustering large-scale data, and PCE ensures better performance for IMC. We show the universality of our SDSC framework as well. Experiments on several data sets demonstrate the effectiveness of our approaches. Moreover, we are the first one to apply densification on affinity matrix before spectral clustering, and SDSC constitutes the first attempt to build a universal three-stage subspace clustering framework.
Residual Encoder-Decoder Network for Deep Subspace Clustering
Oct 12, 2019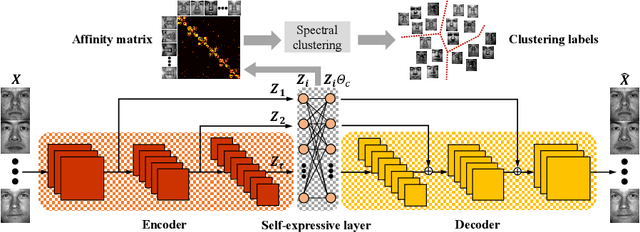



Subspace clustering aims to cluster unlabeled data that lies in a union of low-dimensional linear subspaces. Deep subspace clustering approaches based on auto-encoders have become very popular to solve subspace clustering problems. However, the training of current deep methods converges slowly, which is much less efficient than traditional approaches. We propose a Residual Encoder-Decoder network for deep Subspace Clustering (RED-SC), which symmetrically links convolutional and deconvolutional layers with skip-layer connections, with which the training converges much faster. We use a self-expressive layer to generate more accurate linear representation coefficients through different latent representations from multiple latent spaces. Experiments show the superiority of RED-SC in training efficiency and clustering accuracy. Moreover, we are the first one to apply residual encoder-decoder on unsupervised learning tasks.
Three-Stage Subspace Clustering Framework with Graph-Based Transformation and Optimization
May 02, 2019



Subspace clustering (SC) refers to the problem of clustering high-dimensional data into a union of low-dimensional subspaces. Based on spectral clustering, state-of-the-art approaches solve SC problem within a two-stage framework. In the first stage, data representation techniques are applied to draw an affinity matrix from the original data. In the second stage, spectral clustering is directly applied to the affinity matrix so that data can be grouped into different subspaces. However, the affinity matrix obtained in the first stage usually fails to reveal the authentic relationship between data points, which leads to inaccurate clustering results. In this paper, we propose a universal Three-Stage Subspace Clustering framework (3S-SC). Graph-Based Transformation and Optimization (GBTO) is added between data representation and spectral clustering. The affinity matrix is obtained in the first stage, then it goes through the second stage, where the proposed GBTO is applied to generate a reconstructed affinity matrix with more authentic similarity between data points. Spectral clustering is applied after GBTO, which is the third stage. We verify our 3S-SC framework with GBTO through theoretical analysis. Experiments on both synthetic data and the real-world data sets of handwritten digits and human faces demonstrate the universality of the proposed 3S-SC framework in improving the connectivity and accuracy of SC methods based on $\ell_0$, $\ell_1$, $\ell_2$ or nuclear norm regularization.
Restricted Connection Orthogonal Matching Pursuit For Sparse Subspace Clustering
May 01, 2019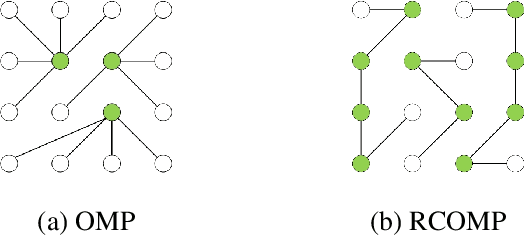
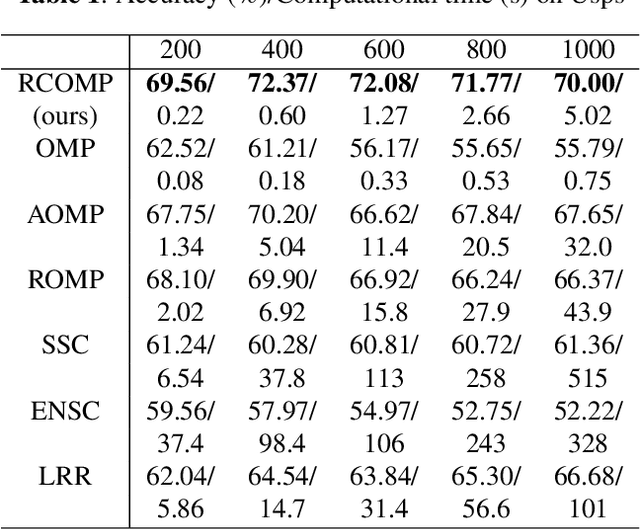
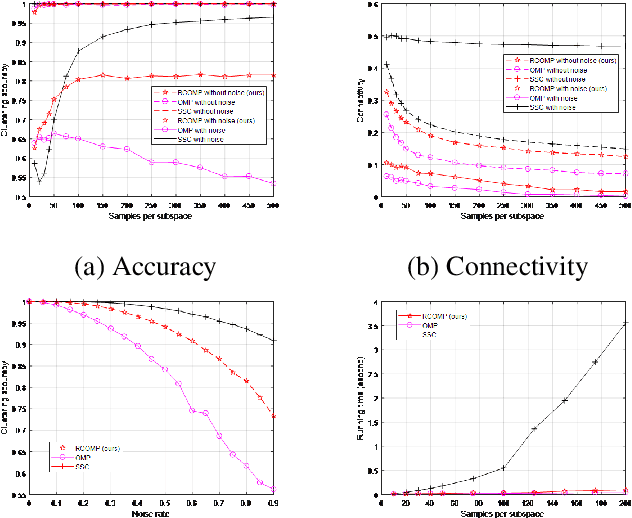
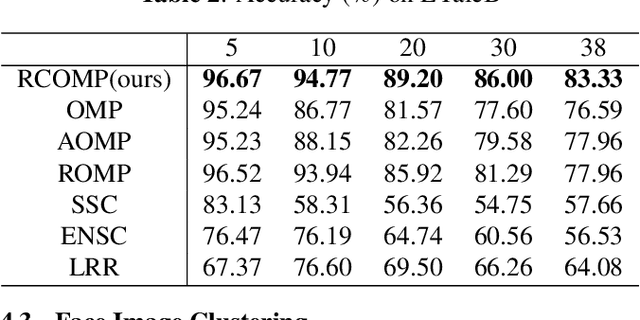
Sparse Subspace Clustering (SSC) is one of the most popular methods for clustering data points into their underlying subspaces. However, SSC may suffer from heavy computational burden. Orthogonal Matching Pursuit applied on SSC accelerates the computation but the trade-off is the loss of clustering accuracy. In this paper, we propose a noise-robust algorithm, Restricted Connection Orthogonal Matching Pursuit for Sparse Subspace Clustering (RCOMP-SSC), to improve the clustering accuracy and maintain the low computational time by restricting the number of connections of each data point during the iteration of OMP. Also, we develop a framework of control matrix to realize RCOMP-SCC. And the framework is scalable for other data point selection strategies. Our analysis and experiments on synthetic data and two real-world databases (EYaleB & Usps) demonstrate the superiority of our algorithm compared with other clustering methods in terms of accuracy and computational time.