 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV3DIS: Multi-View Mask Matching via 3D Guides for Zero-Shot 3D Instance Segmentation
Apr 10, 2026Conventional 3D instance segmentation methods rely on labor-intensive 3D annotations for supervised training, which limits their scalability and generalization to novel objects. Recent approaches leverage multi-view 2D masks from the Segment Anything Model (SAM) to guide the merging of 3D geometric primitives, thereby enabling zero-shot 3D instance segmentation. However, these methods typically process each frame independently and rely solely on 2D metrics, such as SAM prediction scores, to produce segmentation maps. This design overlooks multi-view correlations and inherent 3D priors, leading to inconsistent 2D masks across views and ultimately fragmented 3D segmentation. In this paper, we propose MV3DIS, a coarse-to-fine framework for zero-shot 3D instance segmentation that explicitly incorporates 3D priors. Specifically, we introduce a 3D-guided mask matching strategy that uses coarse 3D segments as a common reference to match 2D masks across views and consolidates multi-view mask consistency via 3D coverage distributions. Guided by these view-consistent 2D masks, the coarse 3D segments are further refined into precise 3D instances. Additionally, we introduce a depth consistency weighting scheme that quantifies projection reliability to suppress ambiguities from inter-object occlusions, thereby improving the robustness of 3D-to-2D correspondence. Extensive experiments on the ScanNetV2, ScanNet200, ScanNet++, Replica, and Matterport3D datasets demonstrate the effectiveness of MV3DIS, which achieves superior performance over previous methods
Few-Shot Incremental 3D Object Detection in Dynamic Indoor Environments
Apr 09, 2026Incremental 3D object perception is a critical step toward embodied intelligence in dynamic indoor environments. However, existing incremental 3D detection methods rely on extensive annotations of novel classes for satisfactory performance. To address this limitation, we propose FI3Det, a Few-shot Incremental 3D Detection framework that enables efficient 3D perception with only a few novel samples by leveraging vision-language models (VLMs) to learn knowledge of unseen categories. FI3Det introduces a VLM-guided unknown object learning module in the base stage to enhance perception of unseen categories. Specifically, it employs VLMs to mine unknown objects and extract comprehensive representations, including 2D semantic features and class-agnostic 3D bounding boxes. To mitigate noise in these representations, a weighting mechanism is further designed to re-weight the contributions of point- and box-level features based on their spatial locations and feature consistency within each box. Moreover, FI3Det proposes a gated multimodal prototype imprinting module, where category prototypes are constructed from aligned 2D semantic and 3D geometric features to compute classification scores, which are then fused via a multimodal gating mechanism for novel object detection. As the first framework for few-shot incremental 3D object detection, we establish both batch and sequential evaluation settings on two datasets, ScanNet V2 and SUN RGB-D, where FI3Det achieves strong and consistent improvements over baseline methods. Code is available at https://github.com/zyrant/FI3Det.
* Accepted by CVPR 2026
STDec: Spatio-Temporal Stability Guided Decoding for dLLMs
Apr 07, 2026Diffusion Large Language Models (dLLMs) have achieved rapid progress, viewed as a promising alternative to the autoregressive paradigm. However, most dLLM decoders still adopt a global confidence threshold, and do not explicitly model local context from neighboring decoded states or temporal consistency of predicted token IDs across steps. To address this issue, we propose a simple spatio-temporal stability guided decoding approach, named STDec. We observe strong spatio-temporal stability in dLLM decoding: newly decoded tokens tend to lie near decoded neighbors, and their predicted IDs often remain consistent across several denoising steps. Inspired by this stability, our STDec includes spatial-aware decoding and temporal-aware decoding. The spatial-aware decoding dynamically generates the token-adaptive threshold by aggregating the decoded states of nearby tokens. The temporal-aware decoding relaxes the decoding thresholds for tokens whose predicted token IDs remain consistent over denoising steps. Our STDec is training-free and remains compatible with cache-based acceleration methods. Across textual reasoning and multimodal understanding benchmarks, STDec substantially improves throughput while maintaining comparable task performance score. Notably, on MBPP with LLaDA, STDec achieves up to 14.17x speedup with a comparable score. Homepage: https://yzchen02.github.io/STDec.
3D-Fixer: Coarse-to-Fine In-place Completion for 3D Scenes from a Single Image
Apr 06, 2026Compositional 3D scene generation from a single view requires the simultaneous recovery of scene layout and 3D assets. Existing approaches mainly fall into two categories: feed-forward generation methods and per-instance generation methods. The former directly predict 3D assets with explicit 6DoF poses through efficient network inference, but they generalize poorly to complex scenes. The latter improve generalization through a divide-and-conquer strategy, but suffer from time-consuming pose optimization. To bridge this gap, we introduce 3D-Fixer, a novel in-place completion paradigm. Specifically, 3D-Fixer extends 3D object generative priors to generate complete 3D assets conditioned on the partially visible point cloud at the original locations, which are cropped from the fragmented geometry obtained from the geometry estimation methods. Unlike prior works that require explicit pose alignment, 3D-Fixer uses fragmented geometry as a spatial anchor to preserve layout fidelity. At its core, we propose a coarse-to-fine generation scheme to resolve boundary ambiguity under occlusion, supported by a dual-branch conditioning network and an Occlusion-Robust Feature Alignment (ORFA) strategy for stable training. Furthermore, to address the data scarcity bottleneck, we present ARSG-110K, the largest scene-level dataset to date, comprising over 110K diverse scenes and 3M annotated images with high-fidelity 3D ground truth. Extensive experiments show that 3D-Fixer achieves state-of-the-art geometric accuracy, which significantly outperforms baselines such as MIDI and Gen3DSR, while maintaining the efficiency of the diffusion process. Code and data will be publicly available at https://zx-yin.github.io/3dfixer.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Generative Point Cloud Registration
Dec 10, 2025In this paper, we propose a novel 3D registration paradigm, Generative Point Cloud Registration, which bridges advanced 2D generative models with 3D matching tasks to enhance registration performance. Our key idea is to generate cross-view consistent image pairs that are well-aligned with the source and target point clouds, enabling geometry-color feature fusion to facilitate robust matching. To ensure high-quality matching, the generated image pair should feature both 2D-3D geometric consistency and cross-view texture consistency. To achieve this, we introduce Match-ControlNet, a matching-specific, controllable 2D generative model. Specifically, it leverages the depth-conditioned generation capability of ControlNet to produce images that are geometrically aligned with depth maps derived from point clouds, ensuring 2D-3D geometric consistency. Additionally, by incorporating a coupled conditional denoising scheme and coupled prompt guidance, Match-ControlNet further promotes cross-view feature interaction, guiding texture consistency generation. Our generative 3D registration paradigm is general and could be seamlessly integrated into various registration methods to enhance their performance. Extensive experiments on 3DMatch and ScanNet datasets verify the effectiveness of our approach.
FUSER: Feed-Forward MUltiview 3D Registration Transformer and SE(3)$^N$ Diffusion Refinement
Dec 10, 2025Registration of multiview point clouds conventionally relies on extensive pairwise matching to build a pose graph for global synchronization, which is computationally expensive and inherently ill-posed without holistic geometric constraints. This paper proposes FUSER, the first feed-forward multiview registration transformer that jointly processes all scans in a unified, compact latent space to directly predict global poses without any pairwise estimation. To maintain tractability, FUSER encodes each scan into low-resolution superpoint features via a sparse 3D CNN that preserves absolute translation cues, and performs efficient intra- and inter-scan reasoning through a Geometric Alternating Attention module. Particularly, we transfer 2D attention priors from off-the-shelf foundation models to enhance 3D feature interaction and geometric consistency. Building upon FUSER, we further introduce FUSER-DF, an SE(3)$^N$ diffusion refinement framework to correct FUSER's estimates via denoising in the joint SE(3)$^N$ space. FUSER acts as a surrogate multiview registration model to construct the denoiser, and a prior-conditioned SE(3)$^N$ variational lower bound is derived for denoising supervision. Extensive experiments on 3DMatch, ScanNet and ArkitScenes demonstrate that our approach achieves the superior registration accuracy and outstanding computational efficiency.
DreamLifting: A Plug-in Module Lifting MV Diffusion Models for 3D Asset Generation
Sep 09, 2025

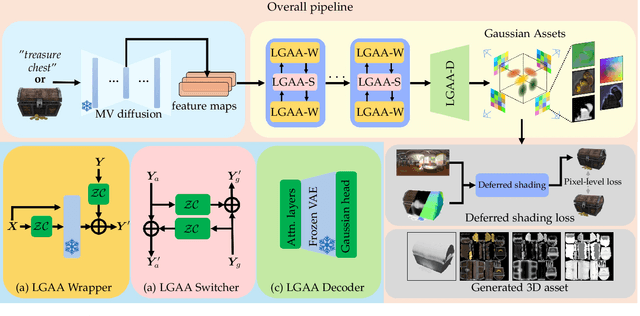

The labor- and experience-intensive creation of 3D assets with physically based rendering (PBR) materials demands an autonomous 3D asset creation pipeline. However, most existing 3D generation methods focus on geometry modeling, either baking textures into simple vertex colors or leaving texture synthesis to post-processing with image diffusion models. To achieve end-to-end PBR-ready 3D asset generation, we present Lightweight Gaussian Asset Adapter (LGAA), a novel framework that unifies the modeling of geometry and PBR materials by exploiting multi-view (MV) diffusion priors from a novel perspective. The LGAA features a modular design with three components. Specifically, the LGAA Wrapper reuses and adapts network layers from MV diffusion models, which encapsulate knowledge acquired from billions of images, enabling better convergence in a data-efficient manner. To incorporate multiple diffusion priors for geometry and PBR synthesis, the LGAA Switcher aligns multiple LGAA Wrapper layers encapsulating different knowledge. Then, a tamed variational autoencoder (VAE), termed LGAA Decoder, is designed to predict 2D Gaussian Splatting (2DGS) with PBR channels. Finally, we introduce a dedicated post-processing procedure to effectively extract high-quality, relightable mesh assets from the resulting 2DGS. Extensive quantitative and qualitative experiments demonstrate the superior performance of LGAA with both text-and image-conditioned MV diffusion models. Additionally, the modular design enables flexible incorporation of multiple diffusion priors, and the knowledge-preserving scheme leads to efficient convergence trained on merely 69k multi-view instances. Our code, pre-trained weights, and the dataset used will be publicly available via our project page: https://zx-yin.github.io/dreamlifting/.
SNNSIR: A Simple Spiking Neural Network for Stereo Image Restoration
Aug 17, 2025Spiking Neural Networks (SNNs), characterized by discrete binary activations, offer high computational efficiency and low energy consumption, making them well-suited for computation-intensive tasks such as stereo image restoration. In this work, we propose SNNSIR, a simple yet effective Spiking Neural Network for Stereo Image Restoration, specifically designed under the spike-driven paradigm where neurons transmit information through sparse, event-based binary spikes. In contrast to existing hybrid SNN-ANN models that still rely on operations such as floating-point matrix division or exponentiation, which are incompatible with the binary and event-driven nature of SNNs, our proposed SNNSIR adopts a fully spike-driven architecture to achieve low-power and hardware-friendly computation. To address the expressiveness limitations of binary spiking neurons, we first introduce a lightweight Spike Residual Basic Block (SRBB) to enhance information flow via spike-compatible residual learning. Building on this, the Spike Stereo Convolutional Modulation (SSCM) module introduces simplified nonlinearity through element-wise multiplication and highlights noise-sensitive regions via cross-view-aware modulation. Complementing this, the Spike Stereo Cross-Attention (SSCA) module further improves stereo correspondence by enabling efficient bidirectional feature interaction across views within a spike-compatible framework. Extensive experiments on diverse stereo image restoration tasks, including rain streak removal, raindrop removal, low-light enhancement, and super-resolution demonstrate that our model achieves competitive restoration performance while significantly reducing computational overhead. These results highlight the potential for real-time, low-power stereo vision applications. The code will be available after the article is accepted.
WeatherDiffusion: Weather-Guided Diffusion Model for Forward and Inverse Rendering
Aug 09, 2025Forward and inverse rendering have emerged as key techniques for enabling understanding and reconstruction in the context of autonomous driving (AD). However, complex weather and illumination pose great challenges to this task. The emergence of large diffusion models has shown promise in achieving reasonable results through learning from 2D priors, but these models are difficult to control and lack robustness. In this paper, we introduce WeatherDiffusion, a diffusion-based framework for forward and inverse rendering on AD scenes with various weather and lighting conditions. Our method enables authentic estimation of material properties, scene geometry, and lighting, and further supports controllable weather and illumination editing through the use of predicted intrinsic maps guided by text descriptions. We observe that different intrinsic maps should correspond to different regions of the original image. Based on this observation, we propose Intrinsic map-aware attention (MAA) to enable high-quality inverse rendering. Additionally, we introduce a synthetic dataset (\ie WeatherSynthetic) and a real-world dataset (\ie WeatherReal) for forward and inverse rendering on AD scenes with diverse weather and lighting. Extensive experiments show that our WeatherDiffusion outperforms state-of-the-art methods on several benchmarks. Moreover, our method demonstrates significant value in downstream tasks for AD, enhancing the robustness of object detection and image segmentation in challenging weather scenarios.