 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Low-Rank: Low-Rank Sparse Prompting via Spiking Neural Network and Prompt Factorization
Jun 01, 2026Visual Prompting (VP) has emerged as an efficient paradigm for adapting large-scale pre-trained vision models to downstream tasks by incorporating learnable prompts at the input level. However, existing VP methods typically employ dense pixel-level prompts, which often suffer from redundant perturbations, limited generalization and energy inefficiency. To overcome these limitations, we propose to integrate brain-inspired spiking learning into visual prompt learning tasks. As we know that spiking neuron can perform inexpensive information processing by transmitting the input data into discrete spike trains and return sparse outputs. Inspired by this, we propose \textbf{Lo}w-\textbf{R}ank visual \textbf{S}pike \textbf{P}rompting (LoRSP), a novel framework that learns dynamic low-rank sparse visual prompts naturally via a Spiking neuron learning mechanism. The core idea of LoRSP is to exploit the brain-inspired sparse firing mechanism of spiking neurons to generate pixel-level sparse prompt for each instance. To be specific, we first construct a series of prompt factors via low-rank factorization to capture distinct prompt subspaces. These prompt factors are then fed into an SNN architecture, which performs the integrate-and-fire process to emit spikes. As a result, our LoRSP generates a \emph{sparse} visual prompt while maintaining the low-rank constraint. This design enables instance-specific selective prompting, leading to more compact and robust adaptation across diverse downstream tasks. Extensive experiments on five heterogeneous vision backbones and multiple benchmarks demonstrate that LoRSP achieves competitive performance while requiring fewer tunable parameters compared to existing VP methods.
SRUG: Shadow-Guided Relightable Urban Scene with Generation Model
May 28, 2026Creating relightable urban scenes from images or videos is widely useful but highly ill-posed. Urban environments are typically unbounded and extend beyond the visible regions. As a result, many portions of the scene remain unobserved, yet these invisible regions can cast shadows onto visible areas. Reasonably modeling shadows cast by such invisible regions is challenging and poses a significant obstacle to creating relightable urban scenes. At the same time, sparse input views and complex illumination conditions further complicate relighting, as they introduce severe ambiguities in material decomposition. In this paper, we propose Shadow-guided Relightable Urban Scene with Generation model (SRUG), a novel framework designed to address relighting challenges in urban scenes. SRUG leverages shadows to guide a 3D completion model for recovering the geometry of invisible regions, promoting the synthesis of physically reasonable shadows. In addition, SRUG employs an iterative material decomposition scheme that applies the large material model (LMM) to provide material supervision and iteratively decompose the scene's material properties, enabling robust material decomposition. Building upon these components, we introduce a physically-based lighting model that captures the complex illumination of urban scenes and supports reliable relighting. Extensive quantitative evaluations and visual comparisons demonstrate that our method outperforms existing approaches in both novel view synthesis and relighting tasks.
F-RNG: Feed-Forward Relightable Neural Gaussians
May 28, 2026Capturing relightable 3D assets from real-world objects is a widely researched problem. Several per-scene optimization-based methods, based on 3D Gaussian splatting (3DGS), support relighting; however, they usually require dense input views, and their overfitting nature makes it difficult to generalize across scenes. Unlike per-scene optimization methods, generalized feed-forward models can directly reconstruct Gaussians from sparse input views. However, the resulting assets have baked-in illumination and cannot be easily used for relighting. In this paper, we present F-RNG, a feed-forward framework that directly generates relightable 3DGS assets from sparse-view inputs. Training such a model from scratch can require massive data and computing resources, and it is especially challenging to generate relightable assets in a feed-forward manner with acceptable cost. We develop F-RNG upon an existing large reconstruction model (LRM) to extract relightable representations, while also utilizing priors from an intrinsic decomposition model (IDM). Specifically, we first introduce a latent-interpolated fine-grained geometry synthesis to enhance the LRM's geometry representation. Second, we propose a prior-guided relightable appearance distillation to extract relightable neural representations by incorporating IDM priors. Finally, a universal neural renderer enables flexible and high-fidelity relighting. F-RNG requires neither re-training nor fine-tuning of the underlying LRMs, thus can automatically benefit from better LRMs and IDMs in the future. With only small networks that can be trained with affordable data and computational resources, F-RNG avoids the repetitive inference of large models under different light conditions. By comparison to the state-of-the-art LRM-based relighting method, F-RNG achieves ~25x faster relighting, as well as superior quality (~+2.0 dB).
Relit-LiVE: Relight Video by Jointly Learning Environment Video
May 07, 2026Recent advances have shown that large-scale video diffusion models can be repurposed as neural renderers by first decomposing videos into intrinsic scene representations and then performing forward rendering under novel illumination. While promising, this paradigm fundamentally relies on accurate intrinsic decomposition, which remains highly unreliable for real-world videos and often leads to distorted appearances, broken materials, and accumulated temporal artifacts during relighting. In this work, we present Relit-LiVE, a novel video relighting framework that produces physically consistent, temporally stable results without requiring prior knowledge of camera pose. Our key insight is to explicitly introduce raw reference images into the rendering process, enabling the model to recover critical scene cues that are inevitably lost or corrupted in intrinsic representations. Furthermore, we propose a novel environment video prediction formulation that simultaneously generates relit videos and per-frame environment maps aligned with each camera viewpoint in a single diffusion process. This joint prediction enforces strong geometric-illumination alignment and naturally supports dynamic lighting and camera motion, significantly improving physical consistency in video relighting while easing the requirement of known per-frame camera pose. Extensive experiments demonstrate that Relit-LiVE consistently outperforms state-of-the-art video relighting and neural rendering methods across synthetic and real-world benchmarks. Beyond relighting, our framework naturally supports a wide range of downstream applications, including scene-level rendering, material editing, object insertion, and streaming video relighting. The Project is available at https://github.com/zhuxing0/Relit-LiVE.
Toward Visually Realistic Simulation: A Benchmark for Evaluating Robot Manipulation in Simulation
May 07, 2026Reliable simulation evaluation of robot manipulation policies serves as a high-fidelity proxy for real-world performance. Although existing benchmarks cover a wide range of task categories, they lack visual realism, creating a large domain gap between simulation and reality. This undermines the reliability of simulation-based evaluation in predicting real-world performance. To mitigate the sim-to-real visual gap, we conduct a systematic analysis to isolate the effects of lighting and material. Our results show that these factors play a critical role in geometric reasoning and spatial grounding, yet are largely overlooked in existing benchmarks. Motivated by the analysis, we propose VISER, a visually realistic benchmark for evaluating robot manipulation in simulation. VISER features a high-fidelity dataset of over 1,000 3D assets with physically-based rendering (PBR) materials, along with 3D scenes created from these assets through curated layouts or generation. To this end, we propose an automated pipeline leveraging Multi-modal Large Language Models (MLLMs) for material-aware part segmentation and material retrieval, enabling scalable generation of physically plausible assets. Building on the high-fidelity 3D asset dataset, we construct diverse evaluation tasks, such as grasping, placing, and long-horizon tasks, enabling scalable and reproducible assessment of Vision-Language-Action (VLA) models. Our benchmark shows a strong correlation between simulation and real-world performance, achieving an average Pearson correlation coefficient of 0.92 across different policies.
Unified Graph Prompt Learning via Low-Rank Graph Message Prompting
Apr 13, 2026Graph Data Prompt (GDP), which introduces specific prompts in graph data for efficiently adapting pre-trained GNNs, has become a mainstream approach to graph fine-tuning learning problem. However, existing GDPs have been respectively designed for distinct graph component (e.g., node features, edge features, edge weights) and thus operate within limited prompt spaces for graph data. To the best of our knowledge, it still lacks a unified prompter suitable for targeting all graph components simultaneously. To address this challenge, in this paper, we first propose to reinterpret a wide range of existing GDPs from an aspect of Graph Message Prompt (GMP) paradigm. Based on GMP, we then introduce a novel graph prompt learning approach, termed Low-Rank GMP (LR-GMP), which leverages low-rank prompt representation to achieve an effective and compact graph prompt learning. Unlike traditional GDPs that target distinct graph components separately, LR-GMP concurrently performs prompting on all graph components in a unified manner, thereby achieving significantly superior generalization and robustness on diverse downstream tasks. Extensive experiments on several graph benchmark datasets demonstrate the effectiveness and advantages of our proposed LR-GMP.
Recovering 3D Shapes from Ultra-Fast Motion-Blurred Images
Feb 08, 2026We consider the problem of 3D shape recovery from ultra-fast motion-blurred images. While 3D reconstruction from static images has been extensively studied, recovering geometry from extreme motion-blurred images remains challenging. Such scenarios frequently occur in both natural and industrial settings, such as fast-moving objects in sports (e.g., balls) or rotating machinery, where rapid motion distorts object appearance and makes traditional 3D reconstruction techniques like Multi-View Stereo (MVS) ineffective. In this paper, we propose a novel inverse rendering approach for shape recovery from ultra-fast motion-blurred images. While conventional rendering techniques typically synthesize blur by averaging across multiple frames, we identify a major computational bottleneck in the repeated computation of barycentric weights. To address this, we propose a fast barycentric coordinate solver, which significantly reduces computational overhead and achieves a speedup of up to 4.57x, enabling efficient and photorealistic simulation of high-speed motion. Crucially, our method is fully differentiable, allowing gradients to propagate from rendered images to the underlying 3D shape, thereby facilitating shape recovery through inverse rendering. We validate our approach on two representative motion types: rapid translation and rotation. Experimental results demonstrate that our method enables efficient and realistic modeling of ultra-fast moving objects in the forward simulation. Moreover, it successfully recovers 3D shapes from 2D imagery of objects undergoing extreme translational and rotational motion, advancing the boundaries of vision-based 3D reconstruction. Project page: https://maxmilite.github.io/rec-from-ultrafast-blur/
Language as Prior, Vision as Calibration: Metric Scale Recovery for Monocular Depth Estimation
Jan 07, 2026Relative-depth foundation models transfer well, yet monocular metric depth remains ill-posed due to unidentifiable global scale and heightened domain-shift sensitivity. Under a frozen-backbone calibration setting, we recover metric depth via an image-specific affine transform in inverse depth and train only lightweight calibration heads while keeping the relative-depth backbone and the CLIP text encoder fixed. Since captions provide coarse but noisy scale cues that vary with phrasing and missing objects, we use language to predict an uncertainty-aware envelope that bounds feasible calibration parameters in an unconstrained space, rather than committing to a text-only point estimate. We then use pooled multi-scale frozen visual features to select an image-specific calibration within this envelope. During training, a closed-form least-squares oracle in inverse depth provides per-image supervision for learning the envelope and the selected calibration. Experiments on NYUv2 and KITTI improve in-domain accuracy, while zero-shot transfer to SUN-RGBD and DDAD demonstrates improved robustness over strong language-only baselines.
When Prompting Meets Spiking: Graph Sparse Prompting via Spiking Graph Prompt Learning
Jan 06, 2026Graph Prompt Feature (GPF) learning has been widely used in adapting pre-trained GNN model on the downstream task. GPFs first introduce some prompt atoms and then learns the optimal prompt vector for each graph node using the linear combination of prompt atoms. However, existing GPFs generally conduct prompting over node's all feature dimensions which is obviously redundant and also be sensitive to node feature noise. To overcome this issue, for the first time, this paper proposes learning sparse graph prompts by leveraging the spiking neuron mechanism, termed Spiking Graph Prompt Feature (SpikingGPF). Our approach is motivated by the observation that spiking neuron can perform inexpensive information processing and produce sparse outputs which naturally fits the task of our graph sparse prompting. Specifically, SpikingGPF has two main aspects. First, it learns a sparse prompt vector for each node by exploiting a spiking neuron architecture, enabling prompting on selective node features. This yields a more compact and lightweight prompting design while also improving robustness against node noise. Second, SpikingGPF introduces a novel prompt representation learning model based on sparse representation theory, i.e., it represents each node prompt as a sparse combination of prompt atoms. This encourages a more compact representation and also facilitates efficient computation. Extensive experiments on several benchmarks demonstrate the effectiveness and robustness of SpikingGPF.
HiMat: DiT-based Ultra-High Resolution SVBRDF Generation
Aug 12, 2025
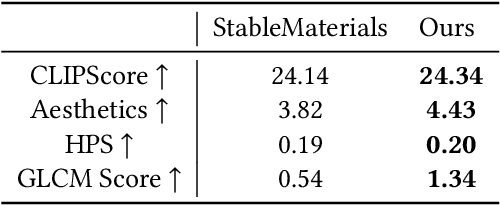

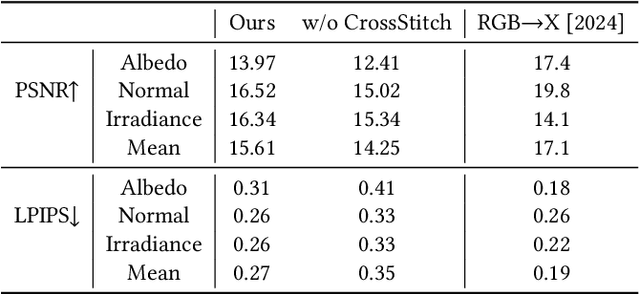
Creating highly detailed SVBRDFs is essential for 3D content creation. The rise of high-resolution text-to-image generative models, based on diffusion transformers (DiT), suggests an opportunity to finetune them for this task. However, retargeting the models to produce multiple aligned SVBRDF maps instead of just RGB images, while achieving high efficiency and ensuring consistency across different maps, remains a challenge. In this paper, we introduce HiMat: a memory- and computation-efficient diffusion-based framework capable of generating native 4K-resolution SVBRDFs. A key challenge we address is maintaining consistency across different maps in a lightweight manner, without relying on training new VAEs or significantly altering the DiT backbone (which would damage its prior capabilities). To tackle this, we introduce the CrossStitch module, a lightweight convolutional module that captures inter-map dependencies through localized operations. Its weights are initialized such that the DiT backbone operation is unchanged before finetuning starts. HiMat enables generation with strong structural coherence and high-frequency details. Results with a large set of text prompts demonstrate the effectiveness of our approach for 4K SVBRDF generation. Further experiments suggest generalization to tasks such as intrinsic decomposition.