 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Dense States: Elevating Sparse Transcoders to Active Operators for Latent Reasoning
Feb 02, 2026Latent reasoning compresses the chain-of-thought (CoT) into continuous hidden states, yet existing methods rely on dense latent transitions that remain difficult to interpret and control. Meanwhile, sparse representation models uncover human-interpretable semantic features but remain largely confined to post-hoc analysis. We reconcile this tension by proposing LSTR (Latent Sparse Transcoder Reasoning), a latent reasoning framework that elevates functional sparse transcoders into active reasoning operators to perform multi-step computation through sparse semantic transitions. At its core, LSTR employs a Latent Transition Transcoder (LTT) with a residual skip architecture that decouples linear manifold transport from sparse semantic updates, enabling controllable semantic resolution via explicit sparsity constraints. Extensive experiments show that LSTR preserves reasoning accuracy and compression efficiency while substantially improving interpretability over dense latent baselines. Causal interventions and trajectory analyses further demonstrate that these sparse features act as both interpretable and causally effective operators in the reasoning process.
SafeThinker: Reasoning about Risk to Deepen Safety Beyond Shallow Alignment
Jan 23, 2026Despite the intrinsic risk-awareness of Large Language Models (LLMs), current defenses often result in shallow safety alignment, rendering models vulnerable to disguised attacks (e.g., prefilling) while degrading utility. To bridge this gap, we propose SafeThinker, an adaptive framework that dynamically allocates defensive resources via a lightweight gateway classifier. Based on the gateway's risk assessment, inputs are routed through three distinct mechanisms: (i) a Standardized Refusal Mechanism for explicit threats to maximize efficiency; (ii) a Safety-Aware Twin Expert (SATE) module to intercept deceptive attacks masquerading as benign queries; and (iii) a Distribution-Guided Think (DDGT) component that adaptively intervenes during uncertain generation. Experiments show that SafeThinker significantly lowers attack success rates across diverse jailbreak strategies without compromising utility, demonstrating that coordinating intrinsic judgment throughout the generation process effectively balances robustness and practicality.
MultiMedEdit: A Scenario-Aware Benchmark for Evaluating Knowledge Editing in Medical VQA
Aug 09, 2025Knowledge editing (KE) provides a scalable approach for updating factual knowledge in large language models without full retraining. While previous studies have demonstrated effectiveness in general domains and medical QA tasks, little attention has been paid to KE in multimodal medical scenarios. Unlike text-only settings, medical KE demands integrating updated knowledge with visual reasoning to support safe and interpretable clinical decisions. To address this gap, we propose MultiMedEdit, the first benchmark tailored to evaluating KE in clinical multimodal tasks. Our framework spans both understanding and reasoning task types, defines a three-dimensional metric suite (reliability, generality, and locality), and supports cross-paradigm comparisons across general and domain-specific models. We conduct extensive experiments under single-editing and lifelong-editing settings. Results suggest that current methods struggle with generalization and long-tail reasoning, particularly in complex clinical workflows. We further present an efficiency analysis (e.g., edit latency, memory footprint), revealing practical trade-offs in real-world deployment across KE paradigms. Overall, MultiMedEdit not only reveals the limitations of current approaches but also provides a solid foundation for developing clinically robust knowledge editing techniques in the future.
MSNGO: multi-species protein function annotation based on 3D protein structure and network propagation
Mar 29, 2025Motivation: In recent years, protein function prediction has broken through the bottleneck of sequence features, significantly improving prediction accuracy using high-precision protein structures predicted by AlphaFold2. While single-species protein function prediction methods have achieved remarkable success, multi-species protein function prediction methods are still in the stage of using PPI networks and sequence features. Providing effective cross-species label propagation for species with sparse protein annotations remains a challenging issue. To address this problem, we propose the MSNGO model, which integrates structural features and network propagation methods. Our validation shows that using structural features can significantly improve the accuracy of multi-species protein function prediction. Results: We employ graph representation learning techniques to extract amino acid representations from protein structure contact maps and train a structural model using a graph convolution pooling module to derive protein-level structural features. After incorporating the sequence features from ESM-2, we apply a network propagation algorithm to aggregate information and update node representations within a heterogeneous network. The results demonstrate that MSNGO outperforms previous multi-species protein function prediction methods that rely on sequence features and PPI networks. Availability: https://github.com/blingbell/MSNGO.
Wide & deep learning for spatial & intensity adaptive image restoration
May 30, 2023Most existing deep learning-based image restoration methods usually aim to remove degradation with uniform spatial distribution and constant intensity, making insufficient use of degradation prior knowledge. Here we bootstrap the deep neural networks to suppress complex image degradation whose intensity is spatially variable, through utilizing prior knowledge from degraded images. Specifically, we propose an ingenious and efficient multi-frame image restoration network (DparNet) with wide & deep architecture, which integrates degraded images and prior knowledge of degradation to reconstruct images with ideal clarity and stability. The degradation prior is directly learned from degraded images in form of key degradation parameter matrix, with no requirement of any off-site knowledge. The wide & deep architecture in DparNet enables the learned parameters to directly modulate the final restoring results, boosting spatial & intensity adaptive image restoration. We demonstrate the proposed method on two representative image restoration applications: image denoising and suppression of atmospheric turbulence effects in images. Two large datasets, containing 109,536 and 49,744 images respectively, were constructed to support our experiments. The experimental results show that our DparNet significantly outperform SoTA methods in restoration performance and network efficiency. More importantly, by utilizing the learned degradation parameters via wide & deep learning, we can improve the PSNR of image restoration by 0.6~1.1 dB with less than 2% increasing in model parameter numbers and computational complexity. Our work suggests that degraded images may hide key information of the degradation process, which can be utilized to boost spatial & intensity adaptive image restoration.
Community Question Answering Entity Linking via Leveraging Auxiliary Data
May 24, 2022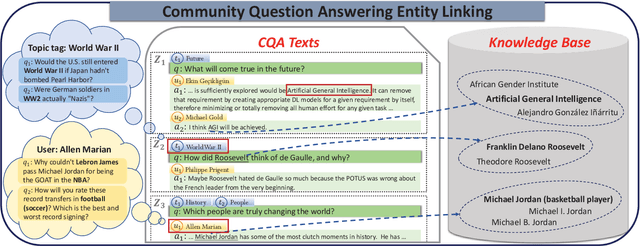
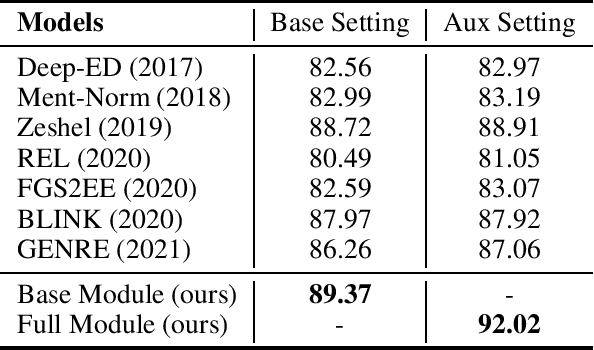

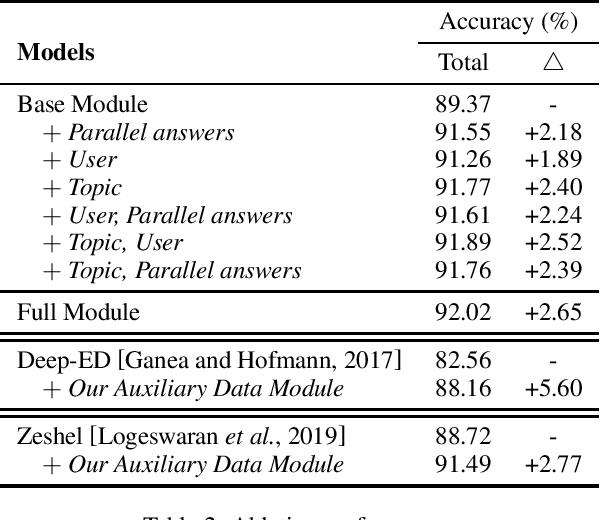
Community Question Answering (CQA) platforms contain plenty of CQA texts (i.e., questions and answers corresponding to the question) where named entities appear ubiquitously. In this paper, we define a new task of CQA entity linking (CQAEL) as linking the textual entity mentions detected from CQA texts with their corresponding entities in a knowledge base. This task can facilitate many downstream applications including expert finding and knowledge base enrichment. Traditional entity linking methods mainly focus on linking entities in news documents, and are suboptimal over this new task of CQAEL since they cannot effectively leverage various informative auxiliary data involved in the CQA platform to aid entity linking, such as parallel answers and two types of meta-data (i.e., topic tags and users). To remedy this crucial issue, we propose a novel transformer-based framework to effectively harness the knowledge delivered by different kinds of auxiliary data to promote the linking performance. We validate the superiority of our framework through extensive experiments over a newly released CQAEL data set against state-of-the-art entity linking methods.
DeepGauge: Multi-Granularity Testing Criteria for Deep Learning Systems
Aug 14, 2018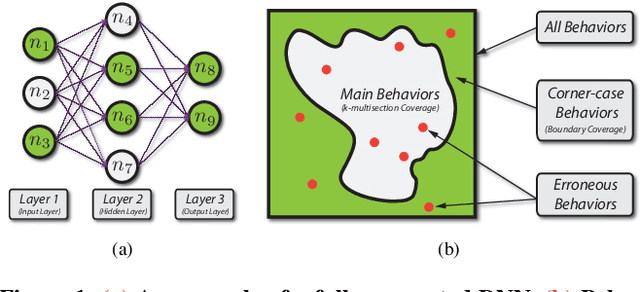
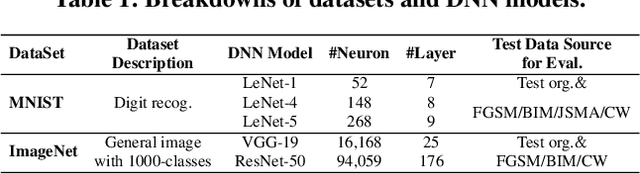

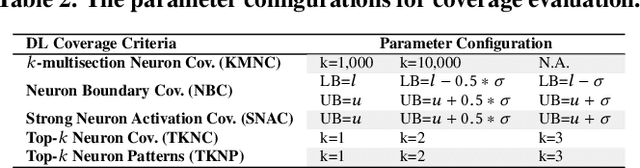
Deep learning (DL) defines a new data-driven programming paradigm that constructs the internal system logic of a crafted neuron network through a set of training data. We have seen wide adoption of DL in many safety-critical scenarios. However, a plethora of studies have shown that the state-of-the-art DL systems suffer from various vulnerabilities which can lead to severe consequences when applied to real-world applications. Currently, the testing adequacy of a DL system is usually measured by the accuracy of test data. Considering the limitation of accessible high quality test data, good accuracy performance on test data can hardly provide confidence to the testing adequacy and generality of DL systems. Unlike traditional software systems that have clear and controllable logic and functionality, the lack of interpretability in a DL system makes system analysis and defect detection difficult, which could potentially hinder its real-world deployment. In this paper, we propose DeepGauge, a set of multi-granularity testing criteria for DL systems, which aims at rendering a multi-faceted portrayal of the testbed. The in-depth evaluation of our proposed testing criteria is demonstrated on two well-known datasets, five DL systems, and with four state-of-the-art adversarial attack techniques against DL. The potential usefulness of DeepGauge sheds light on the construction of more generic and robust DL systems.
* The 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE 2018)
Combinatorial Testing for Deep Learning Systems
Jun 20, 2018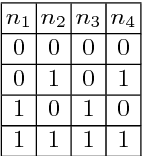
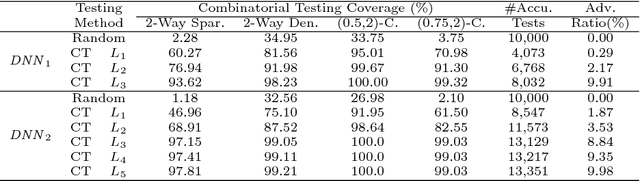
Deep learning (DL) has achieved remarkable progress over the past decade and been widely applied to many safety-critical applications. However, the robustness of DL systems recently receives great concerns, such as adversarial examples against computer vision systems, which could potentially result in severe consequences. Adopting testing techniques could help to evaluate the robustness of a DL system and therefore detect vulnerabilities at an early stage. The main challenge of testing such systems is that its runtime state space is too large: if we view each neuron as a runtime state for DL, then a DL system often contains massive states, rendering testing each state almost impossible. For traditional software, combinatorial testing (CT) is an effective testing technique to reduce the testing space while obtaining relatively high defect detection abilities. In this paper, we perform an exploratory study of CT on DL systems. We adapt the concept in CT and propose a set of coverage criteria for DL systems, as well as a CT coverage guided test generation technique. Our evaluation demonstrates that CT provides a promising avenue for testing DL systems. We further pose several open questions and interesting directions for combinatorial testing of DL systems.
Comparison among dimensionality reduction techniques based on Random Projection for cancer classification
Jun 17, 2017
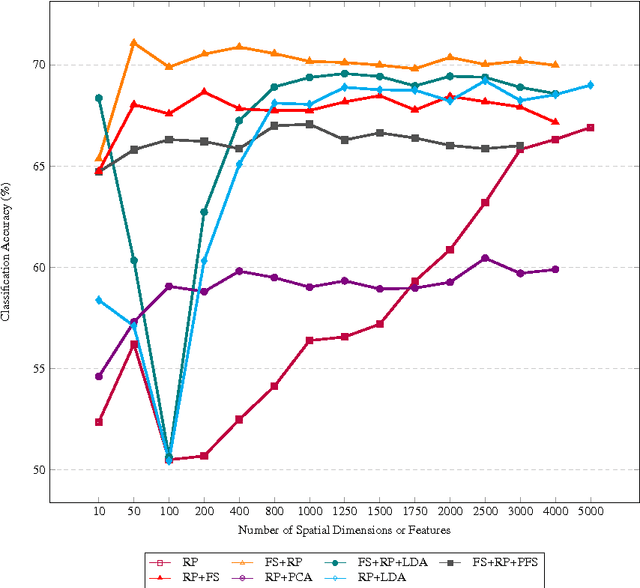
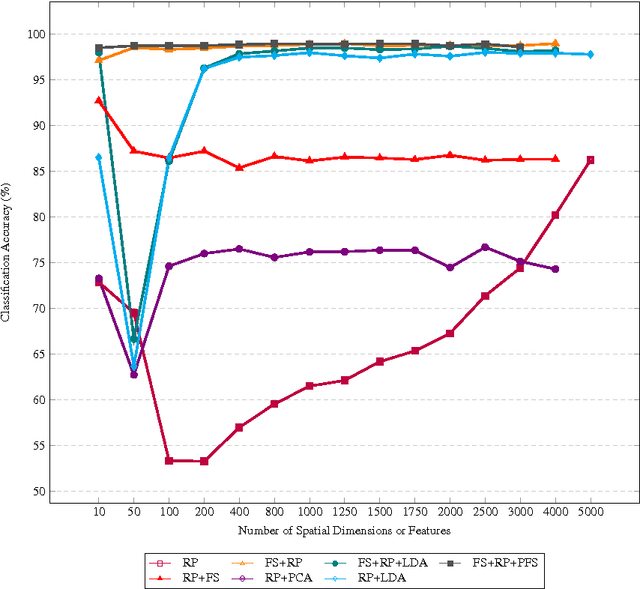

Random Projection (RP) technique has been widely applied in many scenarios because it can reduce high-dimensional features into low-dimensional space within short time and meet the need of real-time analysis of massive data. There is an urgent need of dimensionality reduction with fast increase of big genomics data. However, the performance of RP is usually lower. We attempt to improve classification accuracy of RP through combining other reduction dimension methods such as Principle Component Analysis (PCA), Linear Discriminant Analysis (LDA), and Feature Selection (FS). We compared classification accuracy and running time of different combination methods on three microarray datasets and a simulation dataset. Experimental results show a remarkable improvement of 14.77% in classification accuracy of FS followed by RP compared to RP on BC-TCGA dataset. LDA followed by RP also helps RP to yield a more discriminative subspace with an increase of 13.65% on classification accuracy on the same dataset. FS followed by RP outperforms other combination methods in classification accuracy on most of the datasets.