 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR2: Attention-Guided Repair for the Robustness of CNNs Against Common Corruptions
Jul 08, 2025Deep neural networks suffer from significant performance degradation when exposed to common corruptions such as noise, blur, weather, and digital distortions, limiting their reliability in real-world applications. In this paper, we propose AR2 (Attention-Guided Repair for Robustness), a simple yet effective method to enhance the corruption robustness of pretrained CNNs. AR2 operates by explicitly aligning the class activation maps (CAMs) between clean and corrupted images, encouraging the model to maintain consistent attention even under input perturbations. Our approach follows an iterative repair strategy that alternates between CAM-guided refinement and standard fine-tuning, without requiring architectural changes. Extensive experiments show that AR2 consistently outperforms existing state-of-the-art methods in restoring robustness on standard corruption benchmarks (CIFAR-10-C, CIFAR-100-C and ImageNet-C), achieving a favorable balance between accuracy on clean data and corruption robustness. These results demonstrate that AR2 provides a robust and scalable solution for enhancing model reliability in real-world environments with diverse corruptions.
LeCov: Multi-level Testing Criteria for Large Language Models
Aug 20, 2024



Large Language Models (LLMs) are widely used in many different domains, but because of their limited interpretability, there are questions about how trustworthy they are in various perspectives, e.g., truthfulness and toxicity. Recent research has started developing testing methods for LLMs, aiming to uncover untrustworthy issues, i.e., defects, before deployment. However, systematic and formalized testing criteria are lacking, which hinders a comprehensive assessment of the extent and adequacy of testing exploration. To mitigate this threat, we propose a set of multi-level testing criteria, LeCov, for LLMs. The criteria consider three crucial LLM internal components, i.e., the attention mechanism, feed-forward neurons, and uncertainty, and contain nine types of testing criteria in total. We apply the criteria in two scenarios: test prioritization and coverage-guided testing. The experiment evaluation, on three models and four datasets, demonstrates the usefulness and effectiveness of LeCov.
DeepSearch: Simple and Effective Blackbox Fuzzing of Deep Neural Networks
Oct 14, 2019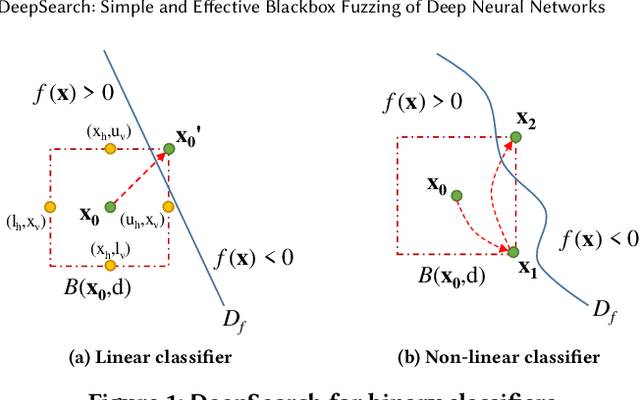
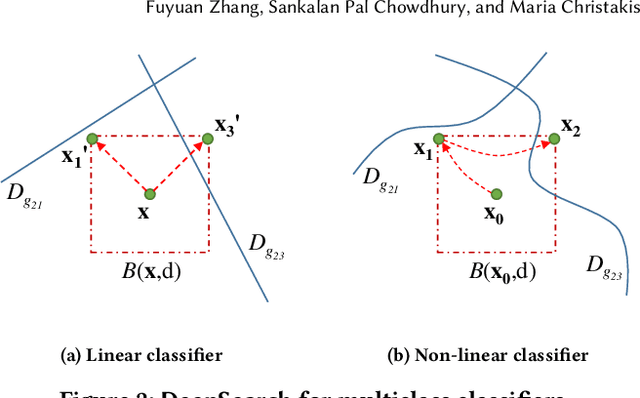
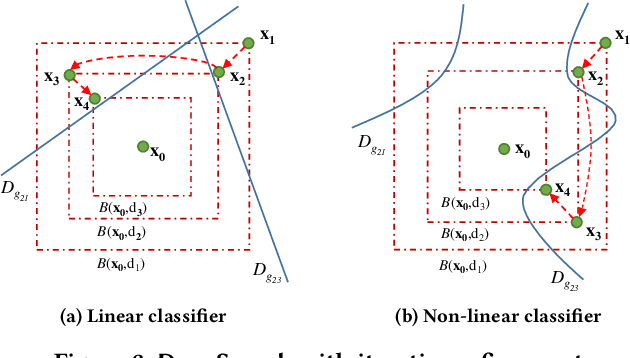
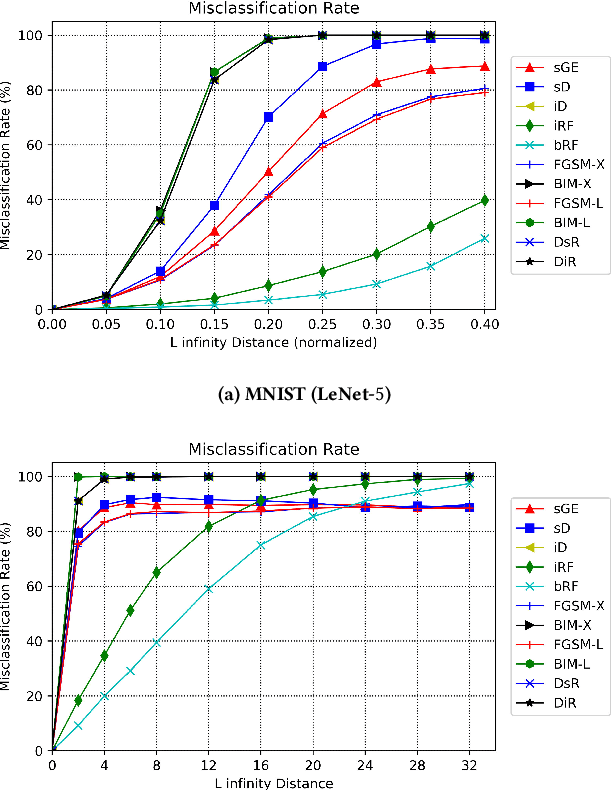
Although deep neural networks have been successful in image classification, they are prone to adversarial attacks. To generate misclassified inputs, there has emerged a wide variety of techniques, such as black- and whitebox testing of neural networks. In this paper, we present DeepSearch, a novel blackbox-fuzzing technique for image classifiers. Despite its simplicity, DeepSearch is shown to be more effective in finding adversarial examples than closely related black- and whitebox approaches. DeepSearch is additionally able to generate the most subtle adversarial examples in comparison to these approaches.
DeepGauge: Multi-Granularity Testing Criteria for Deep Learning Systems
Aug 14, 2018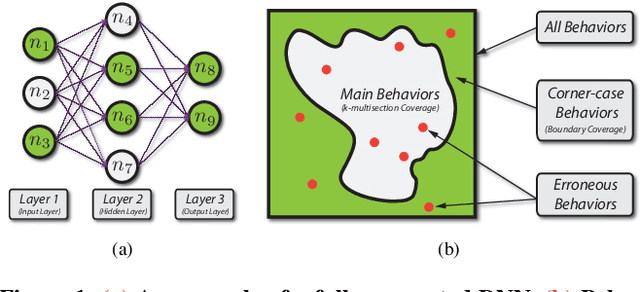
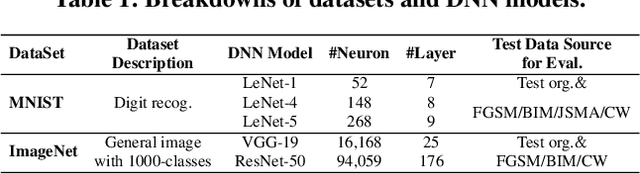

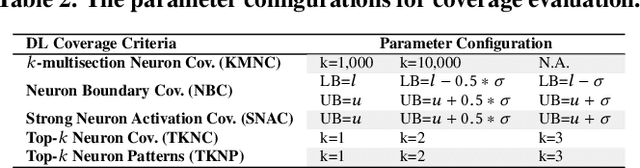
Deep learning (DL) defines a new data-driven programming paradigm that constructs the internal system logic of a crafted neuron network through a set of training data. We have seen wide adoption of DL in many safety-critical scenarios. However, a plethora of studies have shown that the state-of-the-art DL systems suffer from various vulnerabilities which can lead to severe consequences when applied to real-world applications. Currently, the testing adequacy of a DL system is usually measured by the accuracy of test data. Considering the limitation of accessible high quality test data, good accuracy performance on test data can hardly provide confidence to the testing adequacy and generality of DL systems. Unlike traditional software systems that have clear and controllable logic and functionality, the lack of interpretability in a DL system makes system analysis and defect detection difficult, which could potentially hinder its real-world deployment. In this paper, we propose DeepGauge, a set of multi-granularity testing criteria for DL systems, which aims at rendering a multi-faceted portrayal of the testbed. The in-depth evaluation of our proposed testing criteria is demonstrated on two well-known datasets, five DL systems, and with four state-of-the-art adversarial attack techniques against DL. The potential usefulness of DeepGauge sheds light on the construction of more generic and robust DL systems.
* The 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE 2018)
Combinatorial Testing for Deep Learning Systems
Jun 20, 2018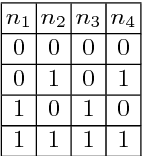
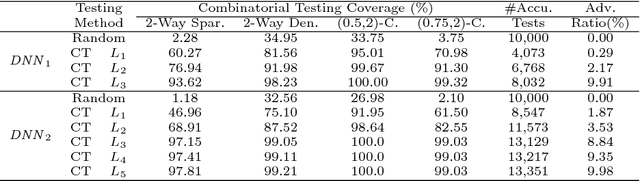
Deep learning (DL) has achieved remarkable progress over the past decade and been widely applied to many safety-critical applications. However, the robustness of DL systems recently receives great concerns, such as adversarial examples against computer vision systems, which could potentially result in severe consequences. Adopting testing techniques could help to evaluate the robustness of a DL system and therefore detect vulnerabilities at an early stage. The main challenge of testing such systems is that its runtime state space is too large: if we view each neuron as a runtime state for DL, then a DL system often contains massive states, rendering testing each state almost impossible. For traditional software, combinatorial testing (CT) is an effective testing technique to reduce the testing space while obtaining relatively high defect detection abilities. In this paper, we perform an exploratory study of CT on DL systems. We adapt the concept in CT and propose a set of coverage criteria for DL systems, as well as a CT coverage guided test generation technique. Our evaluation demonstrates that CT provides a promising avenue for testing DL systems. We further pose several open questions and interesting directions for combinatorial testing of DL systems.