 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskForge: Structure-Aware Adaptive Attacks for Jailbreaking Diffusion Large Language Models
Jun 01, 2026Diffusion large language models (dLLMs) generate text by iteratively denoising partially masked sequences under bidirectional context, exposing a safety surface distinct from autoregressive LLMs. Because mask tokens are native inputs and tokens are committed by confidence rather than position, harmful content can be induced through infilling and outside the monitored prefix. Existing jailbreaks either miss this native infill capability or rely on low-diversity mask-bearing templates applied uniformly across goals, with little structural adaptation or accumulated attack experience. We propose MaskForge, a fully black-box adaptive attack that casts dLLM red-teaming as optimized search over a growing library of structural patterns. MaskForge abstracts successful attempts into reusable schemas, selects goal-compatible patterns with a UCB bandit, and invokes a scorer-guided fallback when the current library fails. Successful attempts are distilled back into the pattern library, enabling experience to accumulate across goals. Across five public dLLMs and three benchmarks, MaskForge achieves an average attack success rate of 79.3%, a 17.6% relative improvement over the strongest competing dLLM baseline. The matured pattern library further transfers to AdvBench without any updates, achieving a 88.2% attack success rate and a 67% relative improvement over the strongest competing baseline.
SoK: Unlearnability and Unlearning for Model Dememorization
May 12, 2026Advanced model dememorization methods, including availability poisoning (unlearnability) and machine unlearning, are emerging as key safeguards against data misuse in machine learning (ML). At the training stage, unlearnability embeds imperceptible perturbations into data before release to reduce learnability. At the post-training stage, unlearning removes previously acquired information from models to prevent unauthorized disclosure or use. While both defenses aim to preserve the right to withhold knowledge, their vulnerabilities and shared foundations remain unclear. Specifically, both unlearnability and unlearning suffer from issues such as shallow dememorization, leading to falsely claimed data learnability reduction or forgetting in the presence of weight perturbations. Moreover, input perturbations may affect the effectiveness of downstream unlearning, while unlearning may inadvertently recover domain knowledge hidden by unlearnability. This interplay calls for deeper investigation. Finally, there is a lack of formal guarantees to provide theoretical insights into current defenses against shallow dememorization. In this Systematization of Knowledge, we present the first integrated analysis of model dememorization approaches leveraging unlearnability and unlearning. Our contributions are threefold: (i) a unified taxonomy of unlearnability and scalable unlearning methods; (ii) an empirical evaluation revealing the robustness, interplay, and shallow dememorization of leading methods; and (iii) the first theoretical guarantee on dememorization depth for models processed through certified unlearning. These results lay the foundation for unifying dememorization mechanisms across the ML lifecycle to achieve a deeper immemor state for sensitive knowledge.
Uncertainty Propagation in LLM-Based Systems
Apr 26, 2026Uncertainty in large language model (LLM)-based systems is often studied at the level of a single model output, yet deployed LLM applications are compound systems in which uncertainty is transformed and reused across model internals, workflow stages, component boundaries, persistent state, and human or organisational processes. Without principled treatment of how uncertainty is carried and reused across these boundaries, early errors can propagate and compound in ways that are difficult to detect and govern. This paper develops a systems-level account of uncertainty propagation. It introduces a conceptual framing for characterising propagated uncertainty signals, presents a structured taxonomy spanning intra-model (P1), system-level (P2), and socio-technical (P3) propagation mechanisms, synthesises cross-cutting engineering insights, and identifies five open research challenges.
If you're waiting for a sign... that might not be it! Mitigating Trust Boundary Confusion from Visual Injections on Vision-Language Agentic Systems
Apr 21, 2026Recent advances in embodied Vision-Language Agentic Systems (VLAS), powered by large vision-language models (LVLMs), enable AI systems to perceive and reason over real-world scenes. Within this context, environmental signals such as traffic lights are essential in-band signals that can and should influence agent behavior. However, similar signals could also be crafted to operate as misleading visual injections, overriding user intent and posing security risks. This duality creates a fundamental challenge: agents must respond to legitimate environmental cues while remaining robust to misleading ones. We refer to this tension as trust boundary confusion. To study this behavior, we design a dual-intent dataset and evaluation framework, through which we show that current LVLM-based agents fail to reliably balance this trade-off, either ignoring useful signals or following harmful ones. We systematically evaluate 7 LVLM agents across multiple embodied settings under both structure-based and noise-based visual injections. To address these vulnerabilities, we propose a multi-agent defense framework that separates perception from decision-making to dynamically assess the reliability of visual inputs. Our approach significantly reduces misleading behaviors while preserving correct responses and provides robustness guarantees under adversarial perturbations. The code of the evaluation framework and artifacts are made available at https://anonymous.4open.science/r/Visual-Prompt-Inject.
AgentRAE: Remote Action Execution through Notification-based Visual Backdoors against Screenshots-based Mobile GUI Agents
Mar 24, 2026The rapid adoption of mobile graphical user interface (GUI) agents, which autonomously control applications and operating systems (OS), exposes new system-level attack surfaces. Existing backdoors against web GUI agents and general GenAI models rely on environmental injection or deceptive pop-ups to mislead the agent operation. However, these techniques do not work on screenshots-based mobile GUI agents due to the challenges of restricted trigger design spaces, OS background interference, and conflicts in multiple trigger-action mappings. We propose AgentRAE, a novel backdoor attack capable of inducing Remote Action Execution in mobile GUI agents using visually natural triggers (e.g., benign app icons in notifications). To address the underfitting caused by natural triggers and achieve accurate multi-target action redirection, we design a novel two-stage pipeline that first enhances the agent's sensitivity to subtle iconographic differences via contrastive learning, and then associates each trigger with a specific mobile GUI agent action through a backdoor post-training. Our extensive evaluation reveals that the proposed backdoor preserves clean performance with an attack success rate of over 90% across ten mobile operations. Furthermore, it is hard to visibly detect the benign-looking triggers and circumvents eight representative state-of-the-art defenses. These results expose an overlooked backdoor vector in mobile GUI agents, underscoring the need for defenses that scrutinize notification-conditioned behaviors and internal agent representations.
AI Model Modulation with Logits Redistribution
Mar 13, 2026Large-scale models are typically adapted to meet the diverse requirements of model owners and users. However, maintaining multiple specialized versions of the model is inefficient. In response, we propose AIM, a novel model modulation paradigm that enables a single model to exhibit diverse behaviors to meet the specific end requirements. AIM enables two key modulation modes: utility and focus modulations. The former provides model owners with dynamic control over output quality to deliver varying utility levels, and the latter offers users precise control to shift model's focused input features. AIM introduces a logits redistribution strategy that operates in a training data-agnostic and retraining-free manner. We establish a formal foundation to ensure AIM's regulation capability, based on the statistical properties of logits ordering via joint probability distributions. Our evaluation confirms AIM's practicality and versatility for Al model modulation, with tasks spanning image classification, semantic segmentation and text generation, and prevalent architectures including ResNet, SegFormer and Llama.
WinFLoRA: Incentivizing Client-Adaptive Aggregation in Federated LoRA under Privacy Heterogeneity
Feb 01, 2026Large Language Models (LLMs) increasingly underpin intelligent web applications, from chatbots to search and recommendation, where efficient specialization is essential. Low-Rank Adaptation (LoRA) enables such adaptation with minimal overhead, while federated LoRA allows web service providers to fine-tune shared models without data sharing. However, in privacy-sensitive deployments, clients inject varying levels of differential privacy (DP) noise, creating privacy heterogeneity that misaligns individual incentives and global performance. In this paper, we propose WinFLoRA, a privacy-heterogeneous federated LoRA that utilizes aggregation weights as incentives with noise awareness. Specifically, the noises from clients are estimated based on the uploaded LoRA adapters. A larger weight indicates greater influence on the global model and better downstream task performance, rewarding lower-noise contributions. By up-weighting low-noise updates, WinFLoRA improves global accuracy while accommodating clients' heterogeneous privacy requirements. Consequently, WinFLoRA aligns heterogeneous client utility in terms of privacy and downstream performance with global model objectives without third-party involvement. Extensive evaluations demonstrate that across multiple LLMs and datasets, WinFLoRA achieves up to 52.58% higher global accuracy and up to 2.56x client utility than state-of-the-art benchmarks. Source code is publicly available at https://github.com/koums24/WinFLoRA.git.
Keep the Lights On, Keep the Lengths in Check: Plug-In Adversarial Detection for Time-Series LLMs in Energy Forecasting
Dec 13, 2025Accurate time-series forecasting is increasingly critical for planning and operations in low-carbon power systems. Emerging time-series large language models (TS-LLMs) now deliver this capability at scale, requiring no task-specific retraining, and are quickly becoming essential components within the Internet-of-Energy (IoE) ecosystem. However, their real-world deployment is complicated by a critical vulnerability: adversarial examples (AEs). Detecting these AEs is challenging because (i) adversarial perturbations are optimized across the entire input sequence and exploit global temporal dependencies, which renders local detection methods ineffective, and (ii) unlike traditional forecasting models with fixed input dimensions, TS-LLMs accept sequences of variable length, increasing variability that complicates detection. To address these challenges, we propose a plug-in detection framework that capitalizes on the TS-LLM's own variable-length input capability. Our method uses sampling-induced divergence as a detection signal. Given an input sequence, we generate multiple shortened variants and detect AEs by measuring the consistency of their forecasts: Benign sequences tend to produce stable predictions under sampling, whereas adversarial sequences show low forecast similarity, because perturbations optimized for a full-length sequence do not transfer reliably to shorter, differently-structured subsamples. We evaluate our approach on three representative TS-LLMs (TimeGPT, TimesFM, and TimeLLM) across three energy datasets: ETTh2 (Electricity Transformer Temperature), NI (Hourly Energy Consumption), and Consumption (Hourly Electricity Consumption and Production). Empirical results confirm strong and robust detection performance across both black-box and white-box attack scenarios, highlighting its practicality as a reliable safeguard for TS-LLM forecasting in real-world energy systems.
E2E-VGuard: Adversarial Prevention for Production LLM-based End-To-End Speech Synthesis
Nov 10, 2025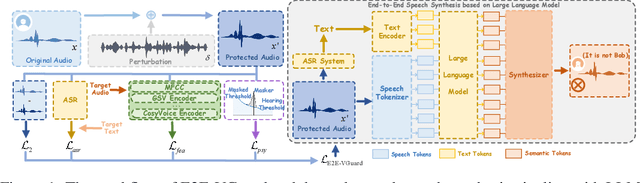
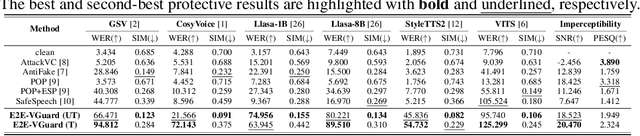

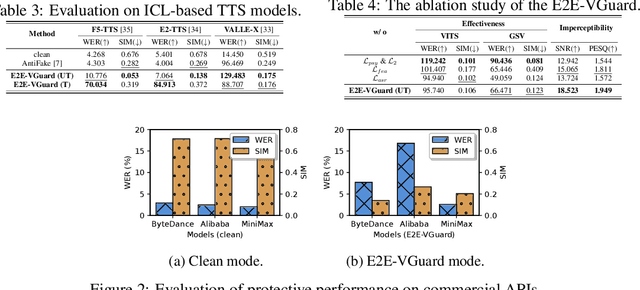
Recent advancements in speech synthesis technology have enriched our daily lives, with high-quality and human-like audio widely adopted across real-world applications. However, malicious exploitation like voice-cloning fraud poses severe security risks. Existing defense techniques struggle to address the production large language model (LLM)-based speech synthesis. While previous studies have considered the protection for fine-tuning synthesizers, they assume manually annotated transcripts. Given the labor intensity of manual annotation, end-to-end (E2E) systems leveraging automatic speech recognition (ASR) to generate transcripts are becoming increasingly prevalent, e.g., voice cloning via commercial APIs. Therefore, this E2E speech synthesis also requires new security mechanisms. To tackle these challenges, we propose E2E-VGuard, a proactive defense framework for two emerging threats: (1) production LLM-based speech synthesis, and (2) the novel attack arising from ASR-driven E2E scenarios. Specifically, we employ the encoder ensemble with a feature extractor to protect timbre, while ASR-targeted adversarial examples disrupt pronunciation. Moreover, we incorporate the psychoacoustic model to ensure perturbative imperceptibility. For a comprehensive evaluation, we test 16 open-source synthesizers and 3 commercial APIs across Chinese and English datasets, confirming E2E-VGuard's effectiveness in timbre and pronunciation protection. Real-world deployment validation is also conducted. Our code and demo page are available at https://wxzyd123.github.io/e2e-vguard/.
ALMGuard: Safety Shortcuts and Where to Find Them as Guardrails for Audio-Language Models
Oct 30, 2025Recent advances in Audio-Language Models (ALMs) have significantly improved multimodal understanding capabilities. However, the introduction of the audio modality also brings new and unique vulnerability vectors. Previous studies have proposed jailbreak attacks that specifically target ALMs, revealing that defenses directly transferred from traditional audio adversarial attacks or text-based Large Language Model (LLM) jailbreaks are largely ineffective against these ALM-specific threats. To address this issue, we propose ALMGuard, the first defense framework tailored to ALMs. Based on the assumption that safety-aligned shortcuts naturally exist in ALMs, we design a method to identify universal Shortcut Activation Perturbations (SAPs) that serve as triggers that activate the safety shortcuts to safeguard ALMs at inference time. To better sift out effective triggers while preserving the model's utility on benign tasks, we further propose Mel-Gradient Sparse Mask (M-GSM), which restricts perturbations to Mel-frequency bins that are sensitive to jailbreaks but insensitive to speech understanding. Both theoretical analyses and empirical results demonstrate the robustness of our method against both seen and unseen attacks. Overall, \MethodName reduces the average success rate of advanced ALM-specific jailbreak attacks to 4.6% across four models, while maintaining comparable utility on benign benchmarks, establishing it as the new state of the art. Our code and data are available at https://github.com/WeifeiJin/ALMGuard.