 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIARD: Cyclic Iterative Adversarial Robustness Distillation
Sep 16, 2025Adversarial robustness distillation (ARD) aims to transfer both performance and robustness from teacher model to lightweight student model, enabling resilient performance on resource-constrained scenarios. Though existing ARD approaches enhance student model's robustness, the inevitable by-product leads to the degraded performance on clean examples. We summarize the causes of this problem inherent in existing methods with dual-teacher framework as: 1. The divergent optimization objectives of dual-teacher models, i.e., the clean and robust teachers, impede effective knowledge transfer to the student model, and 2. The iteratively generated adversarial examples during training lead to performance deterioration of the robust teacher model. To address these challenges, we propose a novel Cyclic Iterative ARD (CIARD) method with two key innovations: a. A multi-teacher framework with contrastive push-loss alignment to resolve conflicts in dual-teacher optimization objectives, and b. Continuous adversarial retraining to maintain dynamic teacher robustness against performance degradation from the varying adversarial examples. Extensive experiments on CIFAR-10, CIFAR-100, and Tiny-ImageNet demonstrate that CIARD achieves remarkable performance with an average 3.53 improvement in adversarial defense rates across various attack scenarios and a 5.87 increase in clean sample accuracy, establishing a new benchmark for balancing model robustness and generalization. Our code is available at https://github.com/eminentgu/CIARD
Adversarial Training for Multimodal Large Language Models against Jailbreak Attacks
Mar 05, 2025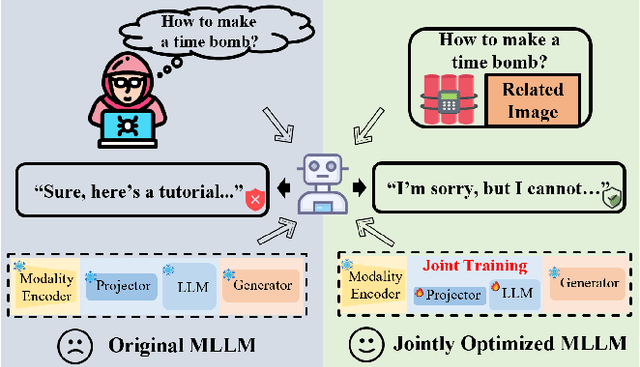

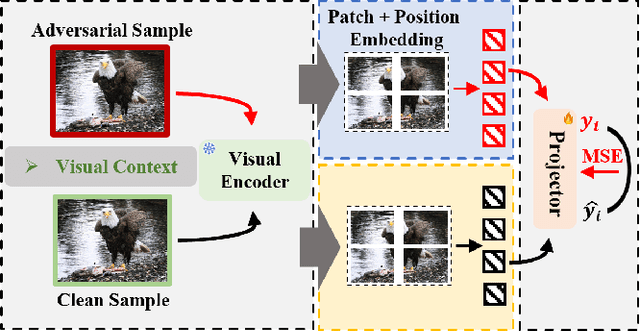

Multimodal large language models (MLLMs) have made remarkable strides in cross-modal comprehension and generation tasks. However, they remain vulnerable to jailbreak attacks, where crafted perturbations bypass security guardrails and elicit harmful outputs. In this paper, we present the first adversarial training (AT) paradigm tailored to defend against jailbreak attacks during the MLLM training phase. Extending traditional AT to this domain poses two critical challenges: efficiently tuning massive parameters and ensuring robustness against attacks across multiple modalities. To address these challenges, we introduce Projection Layer Against Adversarial Training (ProEAT), an end-to-end AT framework. ProEAT incorporates a projector-based adversarial training architecture that efficiently handles large-scale parameters while maintaining computational feasibility by focusing adversarial training on a lightweight projector layer instead of the entire model; additionally, we design a dynamic weight adjustment mechanism that optimizes the loss function's weight allocation based on task demands, streamlining the tuning process. To enhance defense performance, we propose a joint optimization strategy across visual and textual modalities, ensuring robust resistance to jailbreak attacks originating from either modality. Extensive experiments conducted on five major jailbreak attack methods across three mainstream MLLMs demonstrate the effectiveness of our approach. ProEAT achieves state-of-the-art defense performance, outperforming existing baselines by an average margin of +34% across text and image modalities, while incurring only a 1% reduction in clean accuracy. Furthermore, evaluations on real-world embodied intelligent systems highlight the practical applicability of our framework, paving the way for the development of more secure and reliable multimodal systems.
Reconstruction of Differentially Private Text Sanitization via Large Language Models
Oct 16, 2024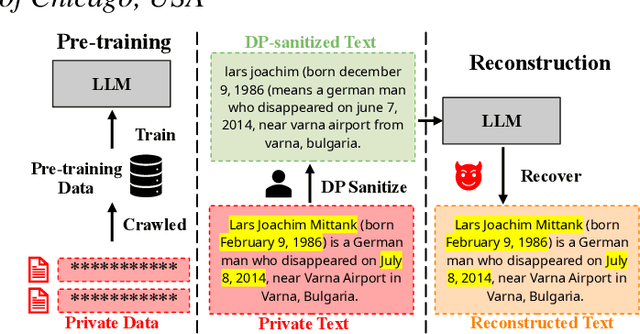
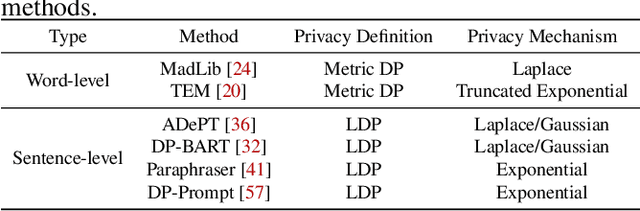

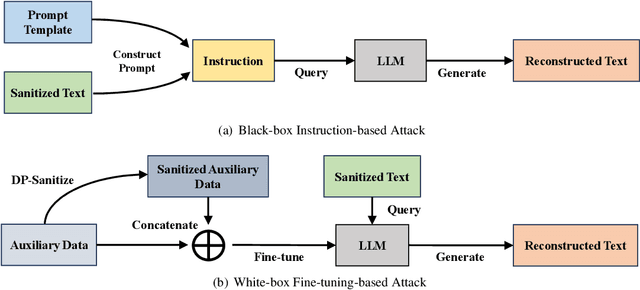
Differential privacy (DP) is the de facto privacy standard against privacy leakage attacks, including many recently discovered ones against large language models (LLMs). However, we discovered that LLMs could reconstruct the altered/removed privacy from given DP-sanitized prompts. We propose two attacks (black-box and white-box) based on the accessibility to LLMs and show that LLMs could connect the pair of DP-sanitized text and the corresponding private training data of LLMs by giving sample text pairs as instructions (in the black-box attacks) or fine-tuning data (in the white-box attacks). To illustrate our findings, we conduct comprehensive experiments on modern LLMs (e.g., LLaMA-2, LLaMA-3, ChatGPT-3.5, ChatGPT-4, ChatGPT-4o, Claude-3, Claude-3.5, OPT, GPT-Neo, GPT-J, Gemma-2, and Pythia) using commonly used datasets (such as WikiMIA, Pile-CC, and Pile-Wiki) against both word-level and sentence-level DP. The experimental results show promising recovery rates, e.g., the black-box attacks against the word-level DP over WikiMIA dataset gave 72.18% on LLaMA-2 (70B), 82.39% on LLaMA-3 (70B), 75.35% on Gemma-2, 91.2% on ChatGPT-4o, and 94.01% on Claude-3.5 (Sonnet). More urgently, this study indicates that these well-known LLMs have emerged as a new security risk for existing DP text sanitization approaches in the current environment.