 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboView-Bias: Benchmarking Visual Bias in Embodied Agents for Robotic Manipulation
Sep 26, 2025The safety and reliability of embodied agents rely on accurate and unbiased visual perception. However, existing benchmarks mainly emphasize generalization and robustness under perturbations, while systematic quantification of visual bias remains scarce. This gap limits a deeper understanding of how perception influences decision-making stability. To address this issue, we propose RoboView-Bias, the first benchmark specifically designed to systematically quantify visual bias in robotic manipulation, following a principle of factor isolation. Leveraging a structured variant-generation framework and a perceptual-fairness validation protocol, we create 2,127 task instances that enable robust measurement of biases induced by individual visual factors and their interactions. Using this benchmark, we systematically evaluate three representative embodied agents across two prevailing paradigms and report three key findings: (i) all agents exhibit significant visual biases, with camera viewpoint being the most critical factor; (ii) agents achieve their highest success rates on highly saturated colors, indicating inherited visual preferences from underlying VLMs; and (iii) visual biases show strong, asymmetric coupling, with viewpoint strongly amplifying color-related bias. Finally, we demonstrate that a mitigation strategy based on a semantic grounding layer substantially reduces visual bias by approximately 54.5\% on MOKA. Our results highlight that systematic analysis of visual bias is a prerequisite for developing safe and reliable general-purpose embodied agents.
CIARD: Cyclic Iterative Adversarial Robustness Distillation
Sep 16, 2025Adversarial robustness distillation (ARD) aims to transfer both performance and robustness from teacher model to lightweight student model, enabling resilient performance on resource-constrained scenarios. Though existing ARD approaches enhance student model's robustness, the inevitable by-product leads to the degraded performance on clean examples. We summarize the causes of this problem inherent in existing methods with dual-teacher framework as: 1. The divergent optimization objectives of dual-teacher models, i.e., the clean and robust teachers, impede effective knowledge transfer to the student model, and 2. The iteratively generated adversarial examples during training lead to performance deterioration of the robust teacher model. To address these challenges, we propose a novel Cyclic Iterative ARD (CIARD) method with two key innovations: a. A multi-teacher framework with contrastive push-loss alignment to resolve conflicts in dual-teacher optimization objectives, and b. Continuous adversarial retraining to maintain dynamic teacher robustness against performance degradation from the varying adversarial examples. Extensive experiments on CIFAR-10, CIFAR-100, and Tiny-ImageNet demonstrate that CIARD achieves remarkable performance with an average 3.53 improvement in adversarial defense rates across various attack scenarios and a 5.87 increase in clean sample accuracy, establishing a new benchmark for balancing model robustness and generalization. Our code is available at https://github.com/eminentgu/CIARD
RecCoT: Enhancing Recommendation via Chain-of-Thought
Jun 26, 2025In real-world applications, users always interact with items in multiple aspects, such as through implicit binary feedback (e.g., clicks, dislikes, long views) and explicit feedback (e.g., comments, reviews). Modern recommendation systems (RecSys) learn user-item collaborative signals from these implicit feedback signals as a large-scale binary data-streaming, subsequently recommending other highly similar items based on users' personalized historical interactions. However, from this collaborative-connection perspective, the RecSys does not focus on the actual content of the items themselves but instead prioritizes higher-probability signals of behavioral co-occurrence among items. Consequently, under this binary learning paradigm, the RecSys struggles to understand why a user likes or dislikes certain items. To alleviate it, some works attempt to utilize the content-based reviews to capture the semantic knowledge to enhance recommender models. However, most of these methods focus on predicting the ratings of reviews, but do not provide a human-understandable explanation.
Federated Mixture-of-Expert for Non-Overlapped Cross-Domain Sequential Recommendation
Mar 17, 2025In the real world, users always have multiple interests while surfing different services to enrich their daily lives, e.g., watching hot short videos/live streamings. To describe user interests precisely for a better user experience, the recent literature proposes cross-domain techniques by transferring the other related services (a.k.a. domain) knowledge to enhance the accuracy of target service prediction. In practice, naive cross-domain techniques typically require there exist some overlapped users, and sharing overall information across domains, including user historical logs, user/item embeddings, and model parameter checkpoints. Nevertheless, other domain's user-side historical logs and embeddings are not always available in real-world RecSys designing, since users may be totally non-overlapped across domains, or the privacy-preserving policy limits the personalized information sharing across domains. Thereby, a challenging but valuable problem is raised: How to empower target domain prediction accuracy by utilizing the other domain model parameters checkpoints only? To answer the question, we propose the FMoE-CDSR, which explores the non-overlapped cross-domain sequential recommendation scenario from the federated learning perspective.
Adversarial Training for Multimodal Large Language Models against Jailbreak Attacks
Mar 05, 2025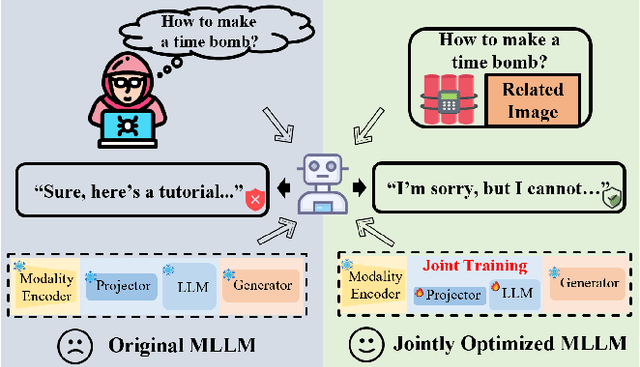

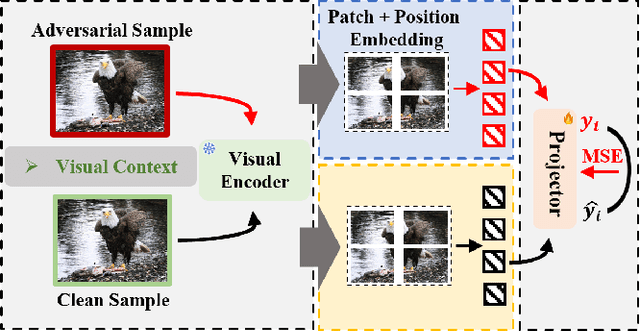

Multimodal large language models (MLLMs) have made remarkable strides in cross-modal comprehension and generation tasks. However, they remain vulnerable to jailbreak attacks, where crafted perturbations bypass security guardrails and elicit harmful outputs. In this paper, we present the first adversarial training (AT) paradigm tailored to defend against jailbreak attacks during the MLLM training phase. Extending traditional AT to this domain poses two critical challenges: efficiently tuning massive parameters and ensuring robustness against attacks across multiple modalities. To address these challenges, we introduce Projection Layer Against Adversarial Training (ProEAT), an end-to-end AT framework. ProEAT incorporates a projector-based adversarial training architecture that efficiently handles large-scale parameters while maintaining computational feasibility by focusing adversarial training on a lightweight projector layer instead of the entire model; additionally, we design a dynamic weight adjustment mechanism that optimizes the loss function's weight allocation based on task demands, streamlining the tuning process. To enhance defense performance, we propose a joint optimization strategy across visual and textual modalities, ensuring robust resistance to jailbreak attacks originating from either modality. Extensive experiments conducted on five major jailbreak attack methods across three mainstream MLLMs demonstrate the effectiveness of our approach. ProEAT achieves state-of-the-art defense performance, outperforming existing baselines by an average margin of +34% across text and image modalities, while incurring only a 1% reduction in clean accuracy. Furthermore, evaluations on real-world embodied intelligent systems highlight the practical applicability of our framework, paving the way for the development of more secure and reliable multimodal systems.
Cross-Domain Sequential Recommendation via Neural Process
Oct 17, 2024



Cross-Domain Sequential Recommendation (CDSR) is a hot topic in sequence-based user interest modeling, which aims at utilizing a single model to predict the next items for different domains. To tackle the CDSR, many methods are focused on domain overlapped users' behaviors fitting, which heavily relies on the same user's different-domain item sequences collaborating signals to capture the synergy of cross-domain item-item correlation. Indeed, these overlapped users occupy a small fraction of the entire user set only, which introduces a strong assumption that the small group of domain overlapped users is enough to represent all domain user behavior characteristics. However, intuitively, such a suggestion is biased, and the insufficient learning paradigm in non-overlapped users will inevitably limit model performance. Further, it is not trivial to model non-overlapped user behaviors in CDSR because there are no other domain behaviors to collaborate with, which causes the observed single-domain users' behavior sequences to be hard to contribute to cross-domain knowledge mining. Considering such a phenomenon, we raise a challenging and unexplored question: How to unleash the potential of non-overlapped users' behaviors to empower CDSR?
Reconstruction of Differentially Private Text Sanitization via Large Language Models
Oct 16, 2024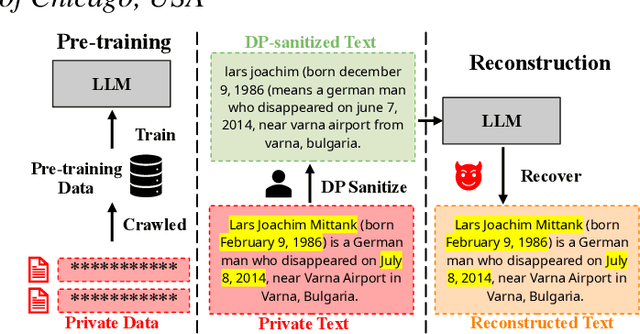
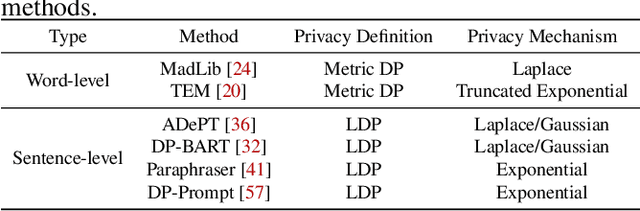

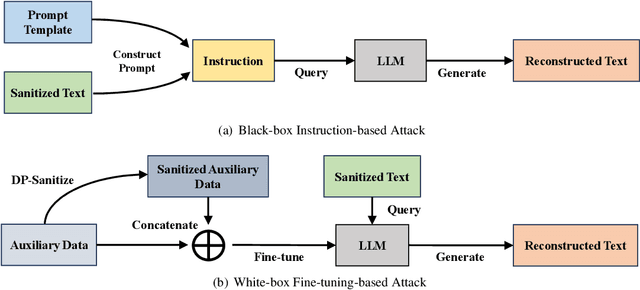
Differential privacy (DP) is the de facto privacy standard against privacy leakage attacks, including many recently discovered ones against large language models (LLMs). However, we discovered that LLMs could reconstruct the altered/removed privacy from given DP-sanitized prompts. We propose two attacks (black-box and white-box) based on the accessibility to LLMs and show that LLMs could connect the pair of DP-sanitized text and the corresponding private training data of LLMs by giving sample text pairs as instructions (in the black-box attacks) or fine-tuning data (in the white-box attacks). To illustrate our findings, we conduct comprehensive experiments on modern LLMs (e.g., LLaMA-2, LLaMA-3, ChatGPT-3.5, ChatGPT-4, ChatGPT-4o, Claude-3, Claude-3.5, OPT, GPT-Neo, GPT-J, Gemma-2, and Pythia) using commonly used datasets (such as WikiMIA, Pile-CC, and Pile-Wiki) against both word-level and sentence-level DP. The experimental results show promising recovery rates, e.g., the black-box attacks against the word-level DP over WikiMIA dataset gave 72.18% on LLaMA-2 (70B), 82.39% on LLaMA-3 (70B), 75.35% on Gemma-2, 91.2% on ChatGPT-4o, and 94.01% on Claude-3.5 (Sonnet). More urgently, this study indicates that these well-known LLMs have emerged as a new security risk for existing DP text sanitization approaches in the current environment.
COMOGen: A Controllable Text-to-3D Multi-object Generation Framework
Sep 01, 2024



The controllability of 3D object generation methods is achieved through input text. Existing text-to-3D object generation methods primarily focus on generating a single object based on a single object description. However, these methods often face challenges in producing results that accurately correspond to our desired positions when the input text involves multiple objects. To address the issue of controllability in generating multiple objects, this paper introduces COMOGen, a COntrollable text-to-3D Multi-Object Generation framework. COMOGen enables the simultaneous generation of multiple 3D objects by the distillation of layout and multi-view prior knowledge. The framework consists of three modules: the layout control module, the multi-view consistency control module, and the 3D content enhancement module. Moreover, to integrate these three modules as an integral framework, we propose Layout Multi-view Score Distillation, which unifies two prior knowledge and further enhances the diversity and quality of generated 3D content. Comprehensive experiments demonstrate the effectiveness of our approach compared to the state-of-the-art methods, which represents a significant step forward in enabling more controlled and versatile text-based 3D content generation.
Foster Adaptivity and Balance in Learning with Noisy Labels
Jul 03, 2024Label noise is ubiquitous in real-world scenarios, posing a practical challenge to supervised models due to its effect in hurting the generalization performance of deep neural networks. Existing methods primarily employ the sample selection paradigm and usually rely on dataset-dependent prior knowledge (\eg, a pre-defined threshold) to cope with label noise, inevitably degrading the adaptivity. Moreover, existing methods tend to neglect the class balance in selecting samples, leading to biased model performance. To this end, we propose a simple yet effective approach named \textbf{SED} to deal with label noise in a \textbf{S}elf-adaptiv\textbf{E} and class-balance\textbf{D} manner. Specifically, we first design a novel sample selection strategy to empower self-adaptivity and class balance when identifying clean and noisy data. A mean-teacher model is then employed to correct labels of noisy samples. Subsequently, we propose a self-adaptive and class-balanced sample re-weighting mechanism to assign different weights to detected noisy samples. Finally, we additionally employ consistency regularization on selected clean samples to improve model generalization performance. Extensive experimental results on synthetic and real-world datasets demonstrate the effectiveness and superiority of our proposed method. The source code has been made available at https://github.com/NUST-Machine-Intelligence-Laboratory/SED.
Enhancing Content-based Recommendation via Large Language Model
Mar 30, 2024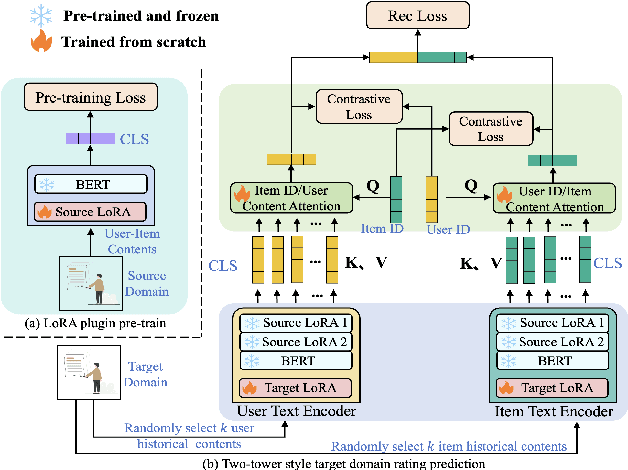
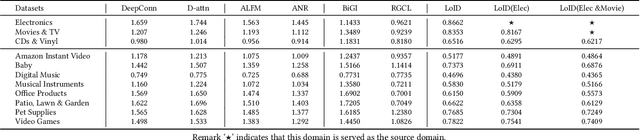


In real-world applications, users express different behaviors when they interact with different items, including implicit click/like interactions, and explicit comments/reviews interactions. Nevertheless, almost all recommender works are focused on how to describe user preferences by the implicit click/like interactions, to find the synergy of people. For the content-based explicit comments/reviews interactions, some works attempt to utilize them to mine the semantic knowledge to enhance recommender models. However, they still neglect the following two points: (1) The content semantic is a universal world knowledge; how do we extract the multi-aspect semantic information to empower different domains? (2) The user/item ID feature is a fundamental element for recommender models; how do we align the ID and content semantic feature space? In this paper, we propose a `plugin' semantic knowledge transferring method \textbf{LoID}, which includes two major components: (1) LoRA-based large language model pretraining to extract multi-aspect semantic information; (2) ID-based contrastive objective to align their feature spaces. We conduct extensive experiments with SOTA baselines on real-world datasets, the detailed results demonstrating significant improvements of our method LoID.