 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelating CNN-Transformer Fusion Network for Change Detection
Jul 03, 2024



While deep learning, particularly convolutional neural networks (CNNs), has revolutionized remote sensing (RS) change detection (CD), existing approaches often miss crucial features due to neglecting global context and incomplete change learning. Additionally, transformer networks struggle with low-level details. RCTNet addresses these limitations by introducing \textbf{(1)} an early fusion backbone to exploit both spatial and temporal features early on, \textbf{(2)} a Cross-Stage Aggregation (CSA) module for enhanced temporal representation, \textbf{(3)} a Multi-Scale Feature Fusion (MSF) module for enriched feature extraction in the decoder, and \textbf{(4)} an Efficient Self-deciphering Attention (ESA) module utilizing transformers to capture global information and fine-grained details for accurate change detection. Extensive experiments demonstrate RCTNet's clear superiority over traditional RS image CD methods, showing significant improvement and an optimal balance between accuracy and computational cost.
Foster Adaptivity and Balance in Learning with Noisy Labels
Jul 03, 2024Label noise is ubiquitous in real-world scenarios, posing a practical challenge to supervised models due to its effect in hurting the generalization performance of deep neural networks. Existing methods primarily employ the sample selection paradigm and usually rely on dataset-dependent prior knowledge (\eg, a pre-defined threshold) to cope with label noise, inevitably degrading the adaptivity. Moreover, existing methods tend to neglect the class balance in selecting samples, leading to biased model performance. To this end, we propose a simple yet effective approach named \textbf{SED} to deal with label noise in a \textbf{S}elf-adaptiv\textbf{E} and class-balance\textbf{D} manner. Specifically, we first design a novel sample selection strategy to empower self-adaptivity and class balance when identifying clean and noisy data. A mean-teacher model is then employed to correct labels of noisy samples. Subsequently, we propose a self-adaptive and class-balanced sample re-weighting mechanism to assign different weights to detected noisy samples. Finally, we additionally employ consistency regularization on selected clean samples to improve model generalization performance. Extensive experimental results on synthetic and real-world datasets demonstrate the effectiveness and superiority of our proposed method. The source code has been made available at https://github.com/NUST-Machine-Intelligence-Laboratory/SED.
Learning with Imbalanced Noisy Data by Preventing Bias in Sample Selection
Feb 17, 2024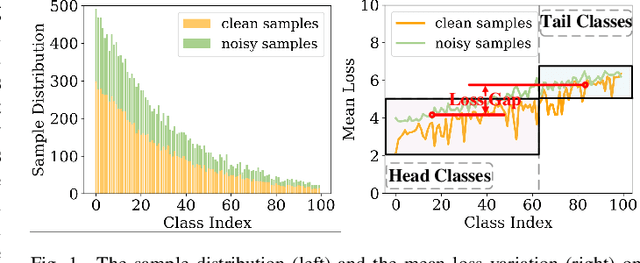
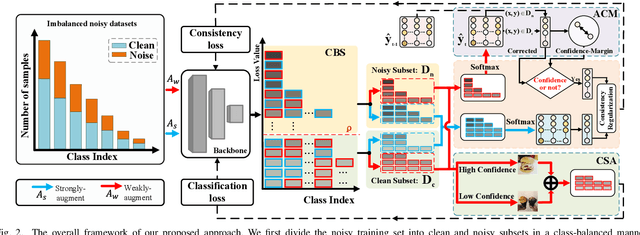
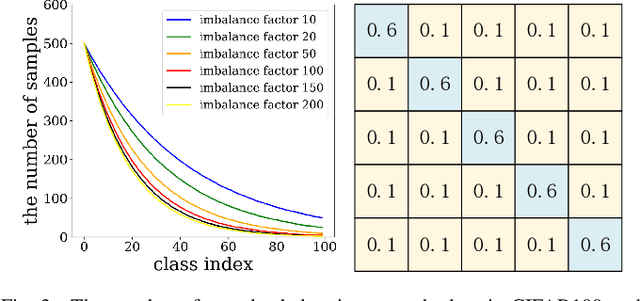
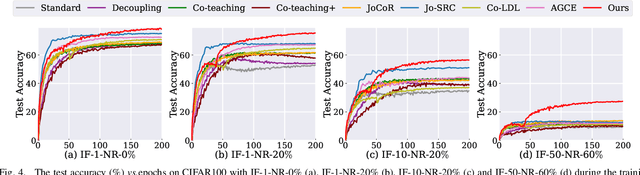
Learning with noisy labels has gained increasing attention because the inevitable imperfect labels in real-world scenarios can substantially hurt the deep model performance. Recent studies tend to regard low-loss samples as clean ones and discard high-loss ones to alleviate the negative impact of noisy labels. However, real-world datasets contain not only noisy labels but also class imbalance. The imbalance issue is prone to causing failure in the loss-based sample selection since the under-learning of tail classes also leans to produce high losses. To this end, we propose a simple yet effective method to address noisy labels in imbalanced datasets. Specifically, we propose Class-Balance-based sample Selection (CBS) to prevent the tail class samples from being neglected during training. We propose Confidence-based Sample Augmentation (CSA) for the chosen clean samples to enhance their reliability in the training process. To exploit selected noisy samples, we resort to prediction history to rectify labels of noisy samples. Moreover, we introduce the Average Confidence Margin (ACM) metric to measure the quality of corrected labels by leveraging the model's evolving training dynamics, thereby ensuring that low-quality corrected noisy samples are appropriately masked out. Lastly, consistency regularization is imposed on filtered label-corrected noisy samples to boost model performance. Comprehensive experimental results on synthetic and real-world datasets demonstrate the effectiveness and superiority of our proposed method, especially in imbalanced scenarios. Comprehensive experimental results on synthetic and real-world datasets demonstrate the effectiveness and superiority of our proposed method, especially in imbalanced scenarios.
Adaptive Integration of Partial Label Learning and Negative Learning for Enhanced Noisy Label Learning
Dec 15, 2023



There has been significant attention devoted to the effectiveness of various domains, such as semi-supervised learning, contrastive learning, and meta-learning, in enhancing the performance of methods for noisy label learning (NLL) tasks. However, most existing methods still depend on prior assumptions regarding clean samples amidst different sources of noise (\eg, a pre-defined drop rate or a small subset of clean samples). In this paper, we propose a simple yet powerful idea called \textbf{NPN}, which revolutionizes \textbf{N}oisy label learning by integrating \textbf{P}artial label learning (PLL) and \textbf{N}egative learning (NL). Toward this goal, we initially decompose the given label space adaptively into the candidate and complementary labels, thereby establishing the conditions for PLL and NL. We propose two adaptive data-driven paradigms of label disambiguation for PLL: hard disambiguation and soft disambiguation. Furthermore, we generate reliable complementary labels using all non-candidate labels for NL to enhance model robustness through indirect supervision. To maintain label reliability during the later stage of model training, we introduce a consistency regularization term that encourages agreement between the outputs of multiple augmentations. Experiments conducted on both synthetically corrupted and real-world noisy datasets demonstrate the superiority of NPN compared to other state-of-the-art (SOTA) methods. The source code has been made available at {\color{purple}{\url{https://github.com/NUST-Machine-Intelligence-Laboratory/NPN}}}.