 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti-Collapse Loss for Deep Metric Learning Based on Coding Rate Metric
Jul 03, 2024Deep metric learning (DML) aims to learn a discriminative high-dimensional embedding space for downstream tasks like classification, clustering, and retrieval. Prior literature predominantly focuses on pair-based and proxy-based methods to maximize inter-class discrepancy and minimize intra-class diversity. However, these methods tend to suffer from the collapse of the embedding space due to their over-reliance on label information. This leads to sub-optimal feature representation and inferior model performance. To maintain the structure of embedding space and avoid feature collapse, we propose a novel loss function called Anti-Collapse Loss. Specifically, our proposed loss primarily draws inspiration from the principle of Maximal Coding Rate Reduction. It promotes the sparseness of feature clusters in the embedding space to prevent collapse by maximizing the average coding rate of sample features or class proxies. Moreover, we integrate our proposed loss with pair-based and proxy-based methods, resulting in notable performance improvement. Comprehensive experiments on benchmark datasets demonstrate that our proposed method outperforms existing state-of-the-art methods. Extensive ablation studies verify the effectiveness of our method in preventing embedding space collapse and promoting generalization performance.
Learning with Imbalanced Noisy Data by Preventing Bias in Sample Selection
Feb 17, 2024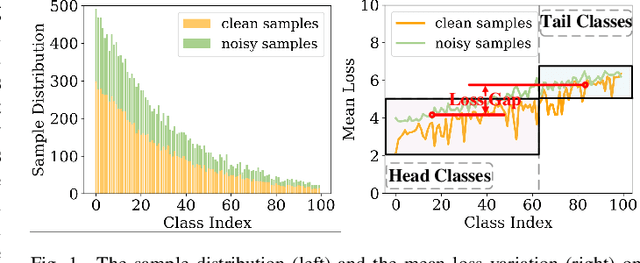
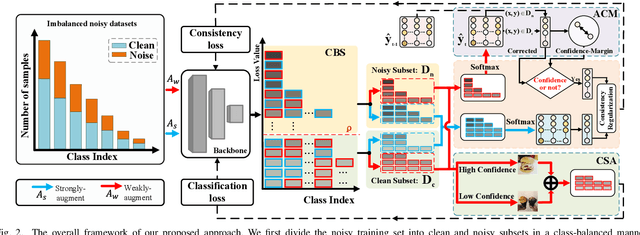
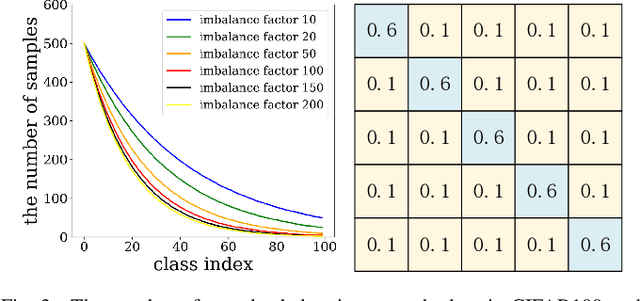
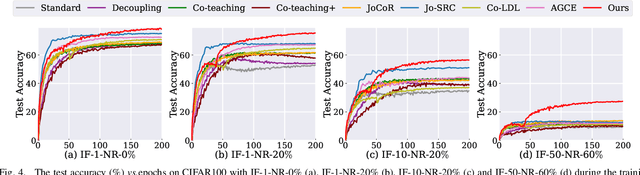
Learning with noisy labels has gained increasing attention because the inevitable imperfect labels in real-world scenarios can substantially hurt the deep model performance. Recent studies tend to regard low-loss samples as clean ones and discard high-loss ones to alleviate the negative impact of noisy labels. However, real-world datasets contain not only noisy labels but also class imbalance. The imbalance issue is prone to causing failure in the loss-based sample selection since the under-learning of tail classes also leans to produce high losses. To this end, we propose a simple yet effective method to address noisy labels in imbalanced datasets. Specifically, we propose Class-Balance-based sample Selection (CBS) to prevent the tail class samples from being neglected during training. We propose Confidence-based Sample Augmentation (CSA) for the chosen clean samples to enhance their reliability in the training process. To exploit selected noisy samples, we resort to prediction history to rectify labels of noisy samples. Moreover, we introduce the Average Confidence Margin (ACM) metric to measure the quality of corrected labels by leveraging the model's evolving training dynamics, thereby ensuring that low-quality corrected noisy samples are appropriately masked out. Lastly, consistency regularization is imposed on filtered label-corrected noisy samples to boost model performance. Comprehensive experimental results on synthetic and real-world datasets demonstrate the effectiveness and superiority of our proposed method, especially in imbalanced scenarios. Comprehensive experimental results on synthetic and real-world datasets demonstrate the effectiveness and superiority of our proposed method, especially in imbalanced scenarios.
Hierarchical Graph Pattern Understanding for Zero-Shot VOS
Dec 15, 2023



The optical flow guidance strategy is ideal for obtaining motion information of objects in the video. It is widely utilized in video segmentation tasks. However, existing optical flow-based methods have a significant dependency on optical flow, which results in poor performance when the optical flow estimation fails for a particular scene. The temporal consistency provided by the optical flow could be effectively supplemented by modeling in a structural form. This paper proposes a new hierarchical graph neural network (GNN) architecture, dubbed hierarchical graph pattern understanding (HGPU), for zero-shot video object segmentation (ZS-VOS). Inspired by the strong ability of GNNs in capturing structural relations, HGPU innovatively leverages motion cues (\ie, optical flow) to enhance the high-order representations from the neighbors of target frames. Specifically, a hierarchical graph pattern encoder with message aggregation is introduced to acquire different levels of motion and appearance features in a sequential manner. Furthermore, a decoder is designed for hierarchically parsing and understanding the transformed multi-modal contexts to achieve more accurate and robust results. HGPU achieves state-of-the-art performance on four publicly available benchmarks (DAVIS-16, YouTube-Objects, Long-Videos and DAVIS-17). Code and pre-trained model can be found at \url{https://github.com/NUST-Machine-Intelligence-Laboratory/HGPU}.
* accepted by IEEE Transactions on Image Processing
Holistic Prototype Attention Network for Few-Shot VOS
Jul 16, 2023



Few-shot video object segmentation (FSVOS) aims to segment dynamic objects of unseen classes by resorting to a small set of support images that contain pixel-level object annotations. Existing methods have demonstrated that the domain agent-based attention mechanism is effective in FSVOS by learning the correlation between support images and query frames. However, the agent frame contains redundant pixel information and background noise, resulting in inferior segmentation performance. Moreover, existing methods tend to ignore inter-frame correlations in query videos. To alleviate the above dilemma, we propose a holistic prototype attention network (HPAN) for advancing FSVOS. Specifically, HPAN introduces a prototype graph attention module (PGAM) and a bidirectional prototype attention module (BPAM), transferring informative knowledge from seen to unseen classes. PGAM generates local prototypes from all foreground features and then utilizes their internal correlations to enhance the representation of the holistic prototypes. BPAM exploits the holistic information from support images and video frames by fusing co-attention and self-attention to achieve support-query semantic consistency and inner-frame temporal consistency. Extensive experiments on YouTube-FSVOS have been provided to demonstrate the effectiveness and superiority of our proposed HPAN method.
Co-attention Propagation Network for Zero-Shot Video Object Segmentation
Apr 08, 2023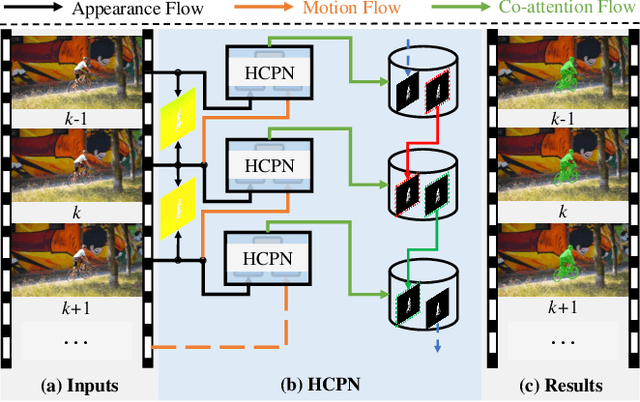
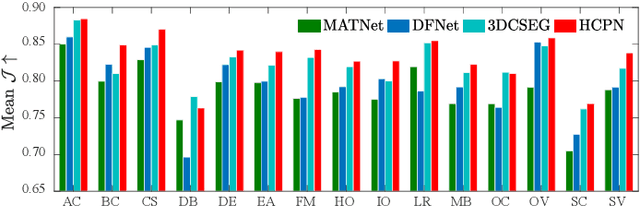

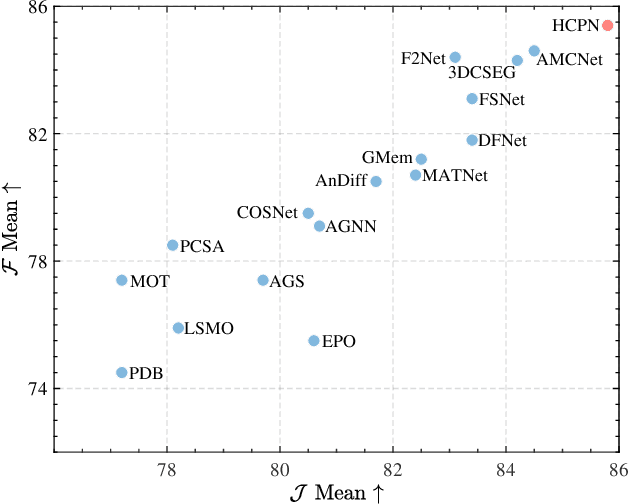
Zero-shot video object segmentation (ZS-VOS) aims to segment foreground objects in a video sequence without prior knowledge of these objects. However, existing ZS-VOS methods often struggle to distinguish between foreground and background or to keep track of the foreground in complex scenarios. The common practice of introducing motion information, such as optical flow, can lead to overreliance on optical flow estimation. To address these challenges, we propose an encoder-decoder-based hierarchical co-attention propagation network (HCPN) capable of tracking and segmenting objects. Specifically, our model is built upon multiple collaborative evolutions of the parallel co-attention module (PCM) and the cross co-attention module (CCM). PCM captures common foreground regions among adjacent appearance and motion features, while CCM further exploits and fuses cross-modal motion features returned by PCM. Our method is progressively trained to achieve hierarchical spatio-temporal feature propagation across the entire video. Experimental results demonstrate that our HCPN outperforms all previous methods on public benchmarks, showcasing its effectiveness for ZS-VOS.
Attention Map Guided Transformer Pruning for Edge Device
Apr 04, 2023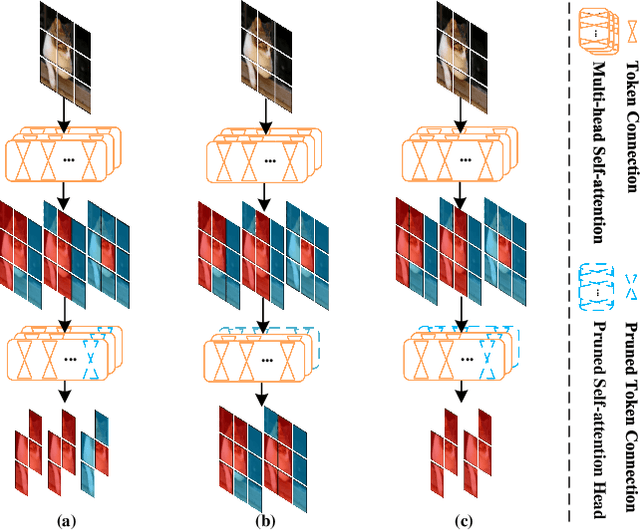
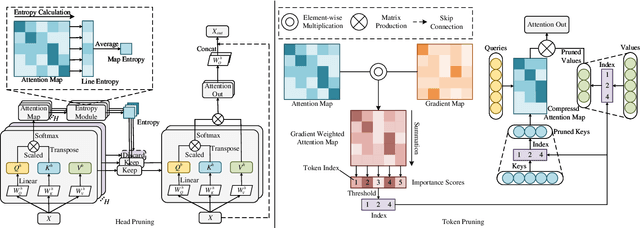
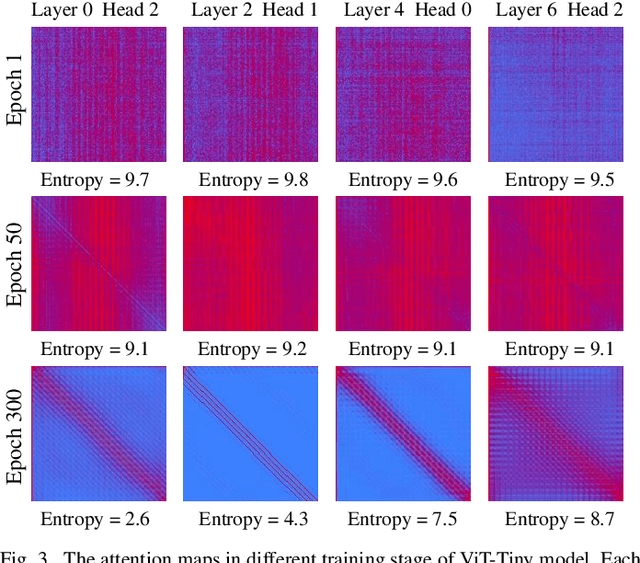
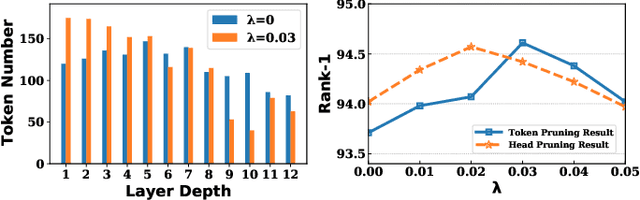
Due to its significant capability of modeling long-range dependencies, vision transformer (ViT) has achieved promising success in both holistic and occluded person re-identification (Re-ID) tasks. However, the inherent problems of transformers such as the huge computational cost and memory footprint are still two unsolved issues that will block the deployment of ViT based person Re-ID models on resource-limited edge devices. Our goal is to reduce both the inference complexity and model size without sacrificing the comparable accuracy on person Re-ID, especially for tasks with occlusion. To this end, we propose a novel attention map guided (AMG) transformer pruning method, which removes both redundant tokens and heads with the guidance of the attention map in a hardware-friendly way. We first calculate the entropy in the key dimension and sum it up for the whole map, and the corresponding head parameters of maps with high entropy will be removed for model size reduction. Then we combine the similarity and first-order gradients of key tokens along the query dimension for token importance estimation and remove redundant key and value tokens to further reduce the inference complexity. Comprehensive experiments on Occluded DukeMTMC and Market-1501 demonstrate the effectiveness of our proposals. For example, our proposed pruning strategy on ViT-Base enjoys \textup{\textbf{29.4\%}} \textup{\textbf{FLOPs}} savings with \textup{\textbf{0.2\%}} drop on Rank-1 and \textup{\textbf{0.4\%}} improvement on mAP, respectively.
Webly Supervised Fine-Grained Recognition: Benchmark Datasets and An Approach
Aug 11, 2021
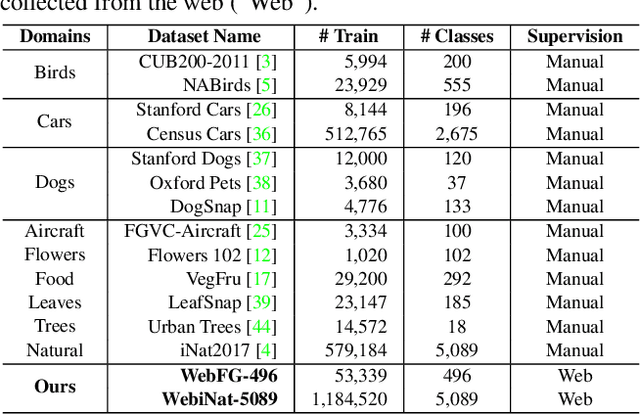

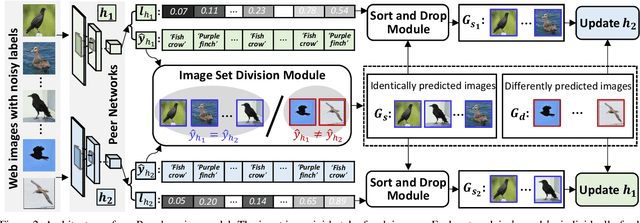
Learning from the web can ease the extreme dependence of deep learning on large-scale manually labeled datasets. Especially for fine-grained recognition, which targets at distinguishing subordinate categories, it will significantly reduce the labeling costs by leveraging free web data. Despite its significant practical and research value, the webly supervised fine-grained recognition problem is not extensively studied in the computer vision community, largely due to the lack of high-quality datasets. To fill this gap, in this paper we construct two new benchmark webly supervised fine-grained datasets, termed WebFG-496 and WebiNat-5089, respectively. In concretely, WebFG-496 consists of three sub-datasets containing a total of 53,339 web training images with 200 species of birds (Web-bird), 100 types of aircrafts (Web-aircraft), and 196 models of cars (Web-car). For WebiNat-5089, it contains 5089 sub-categories and more than 1.1 million web training images, which is the largest webly supervised fine-grained dataset ever. As a minor contribution, we also propose a novel webly supervised method (termed "{Peer-learning}") for benchmarking these datasets.~Comprehensive experimental results and analyses on two new benchmark datasets demonstrate that the proposed method achieves superior performance over the competing baseline models and states-of-the-art. Our benchmark datasets and the source codes of Peer-learning have been made available at {\url{https://github.com/NUST-Machine-Intelligence-Laboratory/weblyFG-dataset}}.