 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
Does Scaling Law Apply in Time Series Forecasting?
May 15, 2025Rapid expansion of model size has emerged as a key challenge in time series forecasting. From early Transformer with tens of megabytes to recent architectures like TimesNet with thousands of megabytes, performance gains have often come at the cost of exponentially increasing parameter counts. But is this scaling truly necessary? To question the applicability of the scaling law in time series forecasting, we propose Alinear, an ultra-lightweight forecasting model that achieves competitive performance using only k-level parameters. We introduce a horizon-aware adaptive decomposition mechanism that dynamically rebalances component emphasis across different forecast lengths, alongside a progressive frequency attenuation strategy that achieves stable prediction in various forecasting horizons without incurring the computational overhead of attention mechanisms. Extensive experiments on seven benchmark datasets demonstrate that Alinear consistently outperforms large-scale models while using less than 1% of their parameters, maintaining strong accuracy across both short and ultra-long forecasting horizons. Moreover, to more fairly evaluate model efficiency, we propose a new parameter-aware evaluation metric that highlights the superiority of ALinear under constrained model budgets. Our analysis reveals that the relative importance of trend and seasonal components varies depending on data characteristics rather than following a fixed pattern, validating the necessity of our adaptive design. This work challenges the prevailing belief that larger models are inherently better and suggests a paradigm shift toward more efficient time series modeling.
Multi-Grained Compositional Visual Clue Learning for Image Intent Recognition
Apr 25, 2025



In an era where social media platforms abound, individuals frequently share images that offer insights into their intents and interests, impacting individual life quality and societal stability. Traditional computer vision tasks, such as object detection and semantic segmentation, focus on concrete visual representations, while intent recognition relies more on implicit visual clues. This poses challenges due to the wide variation and subjectivity of such clues, compounded by the problem of intra-class variety in conveying abstract concepts, e.g. "enjoy life". Existing methods seek to solve the problem by manually designing representative features or building prototypes for each class from global features. However, these methods still struggle to deal with the large visual diversity of each intent category. In this paper, we introduce a novel approach named Multi-grained Compositional visual Clue Learning (MCCL) to address these challenges for image intent recognition. Our method leverages the systematic compositionality of human cognition by breaking down intent recognition into visual clue composition and integrating multi-grained features. We adopt class-specific prototypes to alleviate data imbalance. We treat intent recognition as a multi-label classification problem, using a graph convolutional network to infuse prior knowledge through label embedding correlations. Demonstrated by a state-of-the-art performance on the Intentonomy and MDID datasets, our approach advances the accuracy of existing methods while also possessing good interpretability. Our work provides an attempt for future explorations in understanding complex and miscellaneous forms of human expression.
EdgeGFL: Rethinking Edge Information in Graph Feature Preference Learning
Feb 04, 2025



Graph Neural Networks (GNNs) have significant advantages in handling non-Euclidean data and have been widely applied across various areas, thus receiving increasing attention in recent years. The framework of GNN models mainly includes the information propagation phase and the aggregation phase, treating nodes and edges as information entities and propagation channels, respectively. However, most existing GNN models face the challenge of disconnection between node and edge feature information, as these models typically treat the learning of edge and node features as independent tasks. To address this limitation, we aim to develop an edge-empowered graph feature preference learning framework that can capture edge embeddings to assist node embeddings. By leveraging the learned multidimensional edge feature matrix, we construct multi-channel filters to more effectively capture accurate node features, thereby obtaining the non-local structural characteristics and fine-grained high-order node features. Specifically, the inclusion of multidimensional edge information enhances the functionality and flexibility of the GNN model, enabling it to handle complex and diverse graph data more effectively. Additionally, integrating relational representation learning into the message passing framework allows graph nodes to receive more useful information, thereby facilitating node representation learning. Finally, experiments on four real-world heterogeneous graphs demonstrate the effectiveness of theproposed model.
Belted and Ensembled Neural Network for Linear and Nonlinear Sufficient Dimension Reduction
Dec 12, 2024



We introduce a unified, flexible, and easy-to-implement framework of sufficient dimension reduction that can accommodate both linear and nonlinear dimension reduction, and both the conditional distribution and the conditional mean as the targets of estimation. This unified framework is achieved by a specially structured neural network -- the Belted and Ensembled Neural Network (BENN) -- that consists of a narrow latent layer, which we call the belt, and a family of transformations of the response, which we call the ensemble. By strategically placing the belt at different layers of the neural network, we can achieve linear or nonlinear sufficient dimension reduction, and by choosing the appropriate transformation families, we can achieve dimension reduction for the conditional distribution or the conditional mean. Moreover, thanks to the advantage of the neural network, the method is very fast to compute, overcoming a computation bottleneck of the traditional sufficient dimension reduction estimators, which involves the inversion of a matrix of dimension either p or n. We develop the algorithm and convergence rate of our method, compare it with existing sufficient dimension reduction methods, and apply it to two data examples.
MultiCounter: Multiple Action Agnostic Repetition Counting in Untrimmed Videos
Sep 06, 2024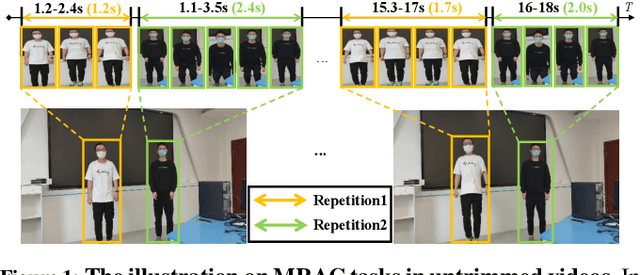

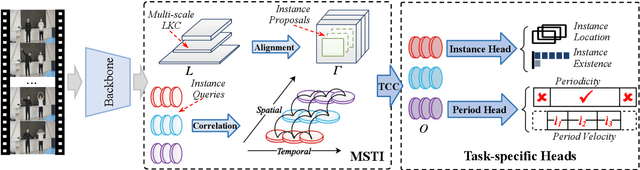
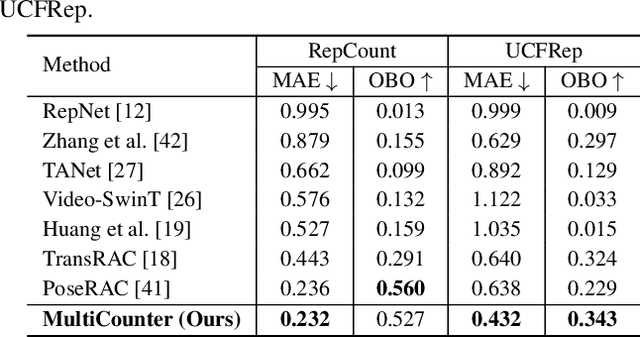
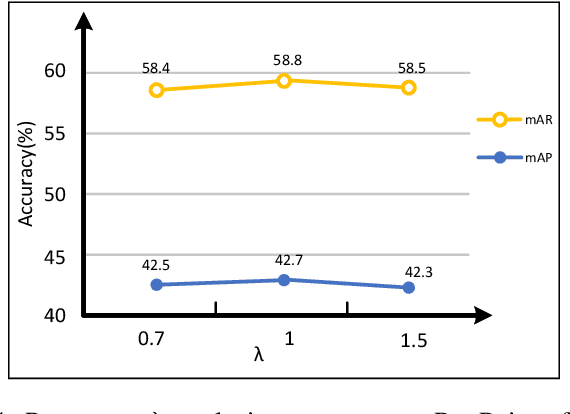
Multi-instance Repetitive Action Counting (MRAC) aims to estimate the number of repetitive actions performed by multiple instances in untrimmed videos, commonly found in human-centric domains like sports and exercise. In this paper, we propose MultiCounter, a fully end-to-end deep learning framework that enables simultaneous detection, tracking, and counting of repetitive actions of multiple human instances. Specifically, MultiCounter incorporates two novel modules: 1) mixed spatiotemporal interaction for efficient context correlation across consecutive frames, and 2) task-specific heads for accurate perception of periodic boundaries and generalization for action-agnostic human instances. We train MultiCounter on a synthetic dataset called MultiRep generated from annotated real-world videos. Experiments on the MultiRep dataset validate the fundamental challenge of MRAC tasks and showcase the superiority of our proposed model. Compared to ByteTrack+RepNet, a solution that combines an advanced tracker with a single repetition counter, MultiCounter substantially improves Period-mAP by 41.0%, reduces AvgMAE by 58.6%, and increases AvgOBO 1.48 times. This sets a new benchmark in the field of MRAC. Moreover, MultiCounter runs in real-time on a commodity GPU server and is insensitive to the number of human instances in a video.
DMKD: Improving Feature-based Knowledge Distillation for Object Detection Via Dual Masking Augmentation
Sep 07, 2023



Recent mainstream masked distillation methods function by reconstructing selectively masked areas of a student network from the feature map of its teacher counterpart. In these methods, the masked regions need to be properly selected, such that reconstructed features encode sufficient discrimination and representation capability like the teacher feature. However, previous masked distillation methods only focus on spatial masking, making the resulting masked areas biased towards spatial importance without encoding informative channel clues. In this study, we devise a Dual Masked Knowledge Distillation (DMKD) framework which can capture both spatially important and channel-wise informative clues for comprehensive masked feature reconstruction. More specifically, we employ dual attention mechanism for guiding the respective masking branches, leading to reconstructed feature encoding dual significance. Furthermore, fusing the reconstructed features is achieved by self-adjustable weighting strategy for effective feature distillation. Our experiments on object detection task demonstrate that the student networks achieve performance gains of 4.1% and 4.3% with the help of our method when RetinaNet and Cascade Mask R-CNN are respectively used as the teacher networks, while outperforming the other state-of-the-art distillation methods.
Holistic Prototype Attention Network for Few-Shot VOS
Jul 16, 2023



Few-shot video object segmentation (FSVOS) aims to segment dynamic objects of unseen classes by resorting to a small set of support images that contain pixel-level object annotations. Existing methods have demonstrated that the domain agent-based attention mechanism is effective in FSVOS by learning the correlation between support images and query frames. However, the agent frame contains redundant pixel information and background noise, resulting in inferior segmentation performance. Moreover, existing methods tend to ignore inter-frame correlations in query videos. To alleviate the above dilemma, we propose a holistic prototype attention network (HPAN) for advancing FSVOS. Specifically, HPAN introduces a prototype graph attention module (PGAM) and a bidirectional prototype attention module (BPAM), transferring informative knowledge from seen to unseen classes. PGAM generates local prototypes from all foreground features and then utilizes their internal correlations to enhance the representation of the holistic prototypes. BPAM exploits the holistic information from support images and video frames by fusing co-attention and self-attention to achieve support-query semantic consistency and inner-frame temporal consistency. Extensive experiments on YouTube-FSVOS have been provided to demonstrate the effectiveness and superiority of our proposed HPAN method.
AMD: Adaptive Masked Distillation for Object Detection
Feb 10, 2023


As a general model compression paradigm, feature-based knowledge distillation allows the student model to learn expressive features from the teacher counterpart. In this paper, we mainly focus on designing an effective feature-distillation framework and propose a spatial-channel adaptive masked distillation (AMD) network for object detection. More specifically, in order to accurately reconstruct important feature regions, we first perform attention-guided feature masking on the feature map of the student network, such that we can identify the important features via spatially adaptive feature masking instead of random masking in the previous methods. In addition, we employ a simple and efficient module to allow the student network channel to be adaptive, improving its model capability in object perception and detection. In contrast to the previous methods, more crucial object-aware features can be reconstructed and learned from the proposed network, which is conducive to accurate object detection. The empirical experiments demonstrate the superiority of our method: with the help of our proposed distillation method, the student networks report 41.3%, 42.4%, and 42.7% mAP scores when RetinaNet, Cascade Mask-RCNN and RepPoints are respectively used as the teacher framework for object detection, which outperforms the previous state-of-the-art distillation methods including FGD and MGD.
Real-time Human Activity Recognition Using Conditionally Parametrized Convolutions on Mobile and Wearable Devices
Jun 13, 2020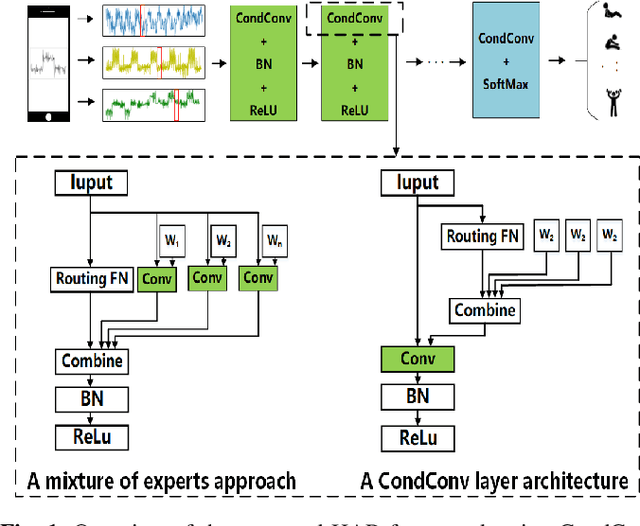
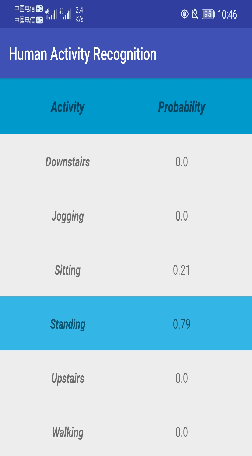
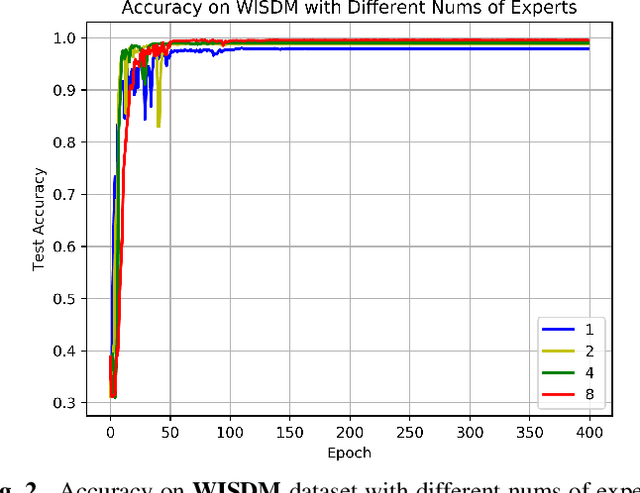
Recently, deep learning has represented an important research trend in human activity recognition (HAR). In particular, deep convolutional neural networks (CNNs) have achieved state-of-the-art performance on various HAR datasets. For deep learning, improvements in performance have to heavily rely on increasing model size or capacity to scale to larger and larger datasets, which inevitably leads to the increase of operations. A high number of operations in deep leaning increases computational cost and is not suitable for real-time HAR using mobile and wearable sensors. Though shallow learning techniques often are lightweight, they could not achieve good performance. Therefore, deep learning methods that can balance the trade-off between accuracy and computation cost is highly needed, which to our knowledge has seldom been researched. In this paper, we for the first time propose a computation efficient CNN using conditionally parametrized convolution for real-time HAR on mobile and wearable devices. We evaluate the proposed method on four public benchmark HAR datasets consisting of WISDM dataset, PAMAP2 dataset, UNIMIB-SHAR dataset, and OPPORTUNITY dataset, achieving state-of-the-art accuracy without compromising computation cost. Various ablation experiments are performed to show how such a network with large capacity is clearly preferable to baseline while requiring a similar amount of operations. The method can be used as a drop-in replacement for the existing deep HAR architectures and easily deployed onto mobile and wearable devices for real-time HAR applications.