 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDanHAR: Dual Attention Network For Multimodal Human Activity Recognition Using Wearable Sensors
Jun 25, 2020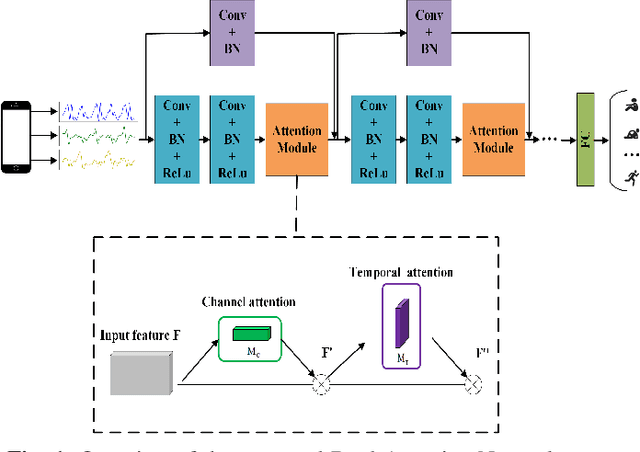
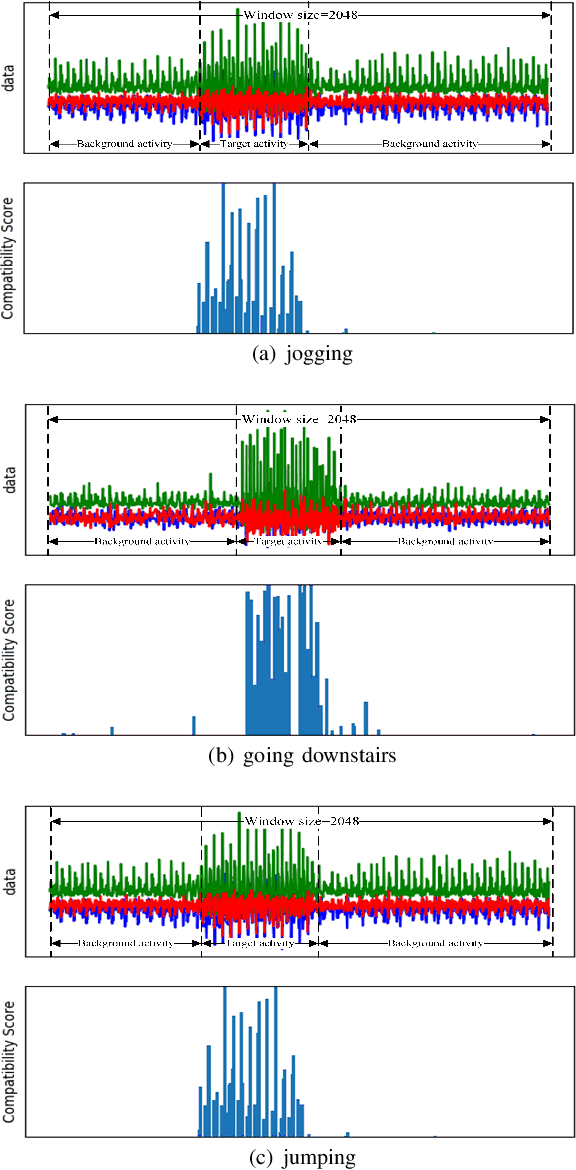
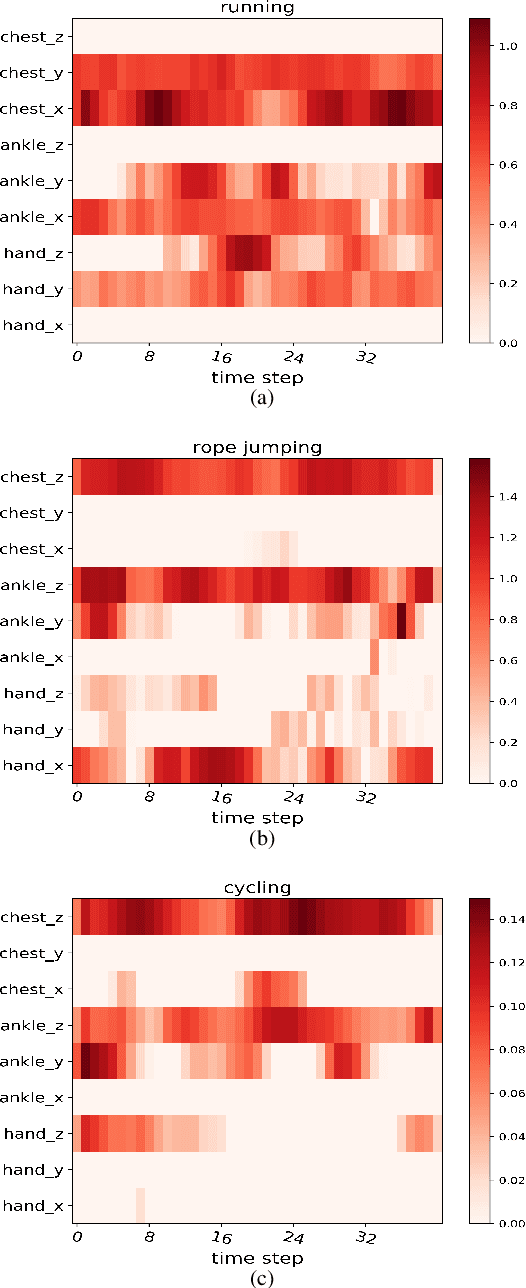
Human activity recognition (HAR) in ubiquitous computing has been beginning to incorporate attention into the context of deep neural networks (DNNs), in which the rich sensing data from multimodal sensors such as accelerometer and gyroscope is used to infer human activities. Recently, two attention methods are proposed via combining with Gated Recurrent Units (GRU) and Long Short-Term Memory (LSTM) network, which can capture the dependencies of sensing signals in both spatial and temporal domains simultaneously. However, recurrent networks often have a weak feature representing power compared with convolutional neural networks (CNNs). On the other hand, two attention, i.e., hard attention and soft attention, are applied in temporal domains via combining with CNN, which pay more attention to the target activity from a long sequence. However, they can only tell where to focus and miss channel information, which plays an important role in deciding what to focus. As a result, they fail to address the spatial-temporal dependencies of multimodal sensing signals, compared with attention-based GRU or LSTM. In the paper, we propose a novel dual attention method called DanHAR, which introduces the framework of blending channel attention and temporal attention on a CNN, demonstrating superiority in improving the comprehensibility for multimodal HAR. Extensive experiments on four public HAR datasets and weakly labeled dataset show that DanHAR achieves state-of-the-art performance with negligible overhead of parameters. Furthermore, visualizing analysis is provided to show that our attention can amplifies more important sensor modalities and timesteps during classification, which agrees well with human common intuition.
Efficient convolutional neural networks with smaller filters for human activity recognition using wearable sensors
May 08, 2020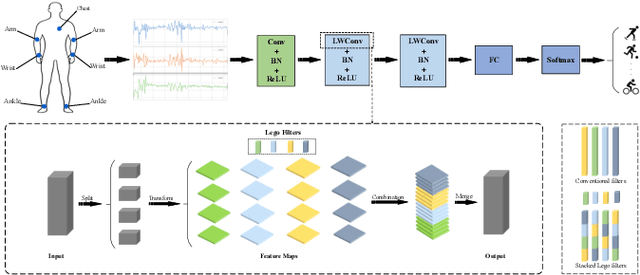
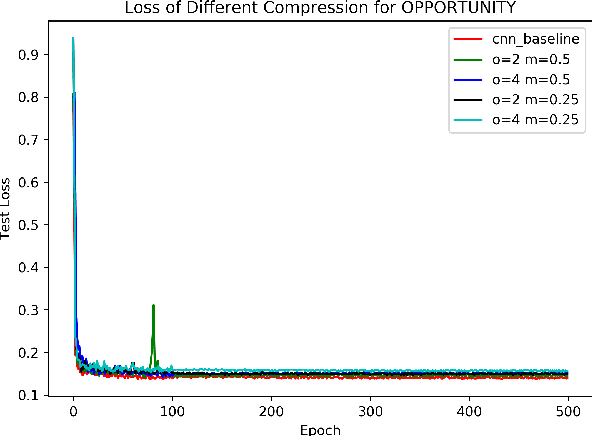
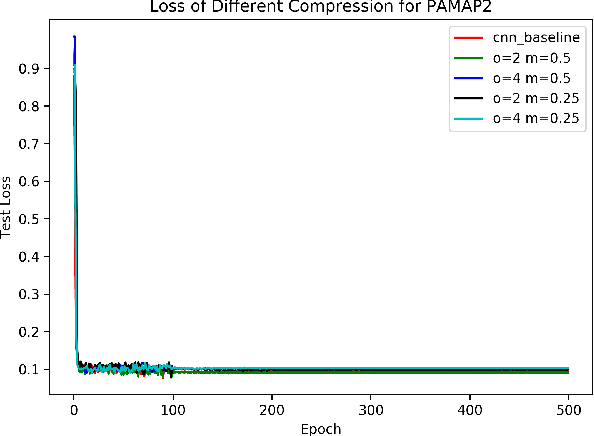
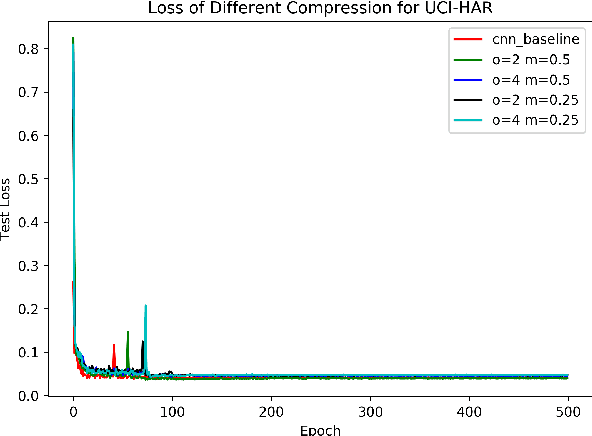
Recently, human activity recognition (HAR) has been beginning to adopt deep learning to substitute for traditional shallow learning techniques that rely on hand-crafted features. CNNs, in particular, have set latest state-of-the-art on various HAR datasets. However, deep model often requires more computing resources, which limits its applications in embedded HAR. Although many successful methods have been proposed to reduce memory and FLOPs of CNNs, they often involve special network architectures for visual tasks, which are not suitable for deep HAR tasks with time series sensor signals, due to remarkable discrepancy. Therefore, it is necessary to develop lightweight deep models to perform HAR. As filter is the basic unit in constructing CNNs, we must ask whether redesigning smaller filters is applicable for deep HAR. In the paper, inspired by the idea, we proposed a lightweight CNN using re-designed Lego filters for the use of HAR. A set of lower-dimensional filters is used as Lego bricks to be stacked for conventional filters, which does not rely on any special network structure. To our knowledge, this is the first paper that proposes lightweight CNN for HAR in ubiquitous and wearable computing arena. The experiment results on five public HAR datasets, UCI-HAR dataset, OPPORTUNITY dataset, UNIMIB-SHAR dataset, PAMAP2 dataset, and WISDM dataset, indicate that our novel Lego-CNN approach can greatly reduce memory and computation cost over CNN, while maintaining comparable accuracy. We believe that the proposed approach could combine with the existing state-of-the-art HAR architecture and easily deployed onto wearable devices for real HAR applications.