 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generalized Zero-Shot Framework for Emotion Recognition from Body Gestures
Oct 20, 2020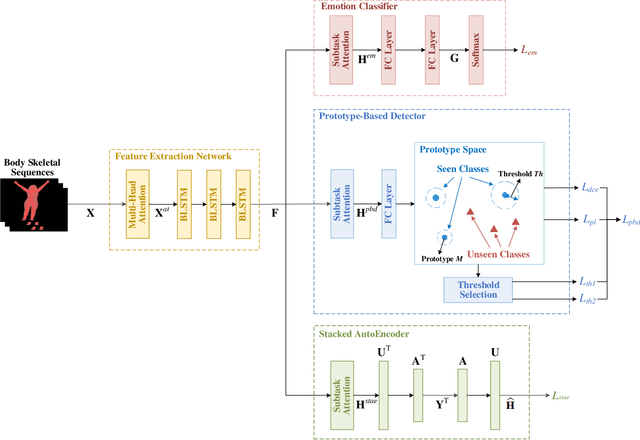

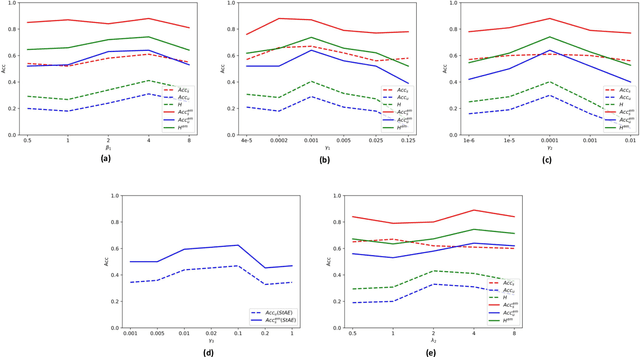
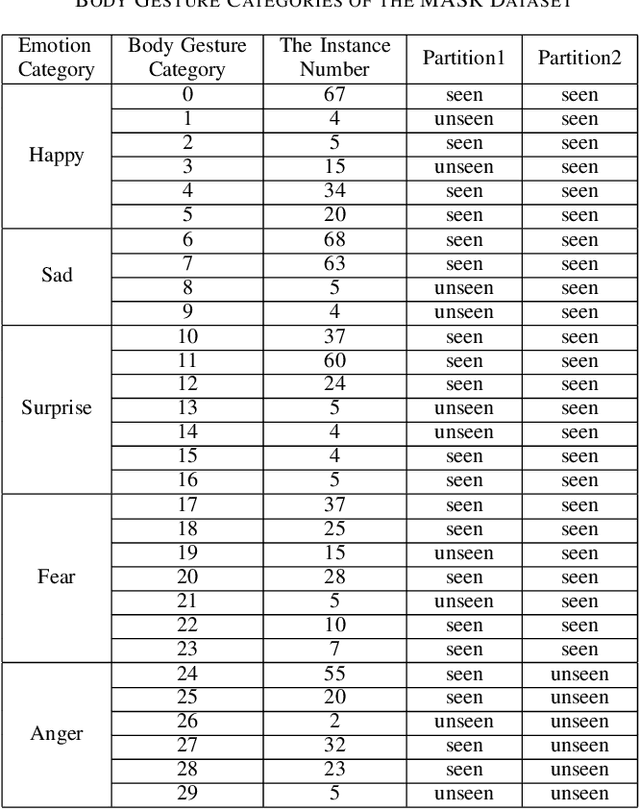
Although automatic emotion recognition from facial expressions and speech has made remarkable progress, emotion recognition from body gestures has not been thoroughly explored. People often use a variety of body language to express emotions, and it is difficult to enumerate all emotional body gestures and collect enough samples for each category. Therefore, recognizing new emotional body gestures is critical for better understanding human emotions. However, the existing methods fail to accurately determine which emotional state a new body gesture belongs to. In order to solve this problem, we introduce a Generalized Zero-Shot Learning (GZSL) framework, which consists of three branches to infer the emotional state of the new body gestures with only their semantic descriptions. The first branch is a Prototype-Based Detector (PBD) which is used to determine whether an sample belongs to a seen body gesture category and obtain the prediction results of the samples from the seen categories. The second branch is a Stacked AutoEncoder (StAE) with manifold regularization, which utilizes semantic representations to predict samples from unseen categories. Note that both of the above branches are for body gesture recognition. We further add an emotion classifier with a softmax layer as the third branch in order to better learn the feature representations for this emotion classification task. The input features for these three branches are learned by a shared feature extraction network, i.e., a Bidirectional Long Short-Term Memory Networks (BLSTM) with a self-attention module. We treat these three branches as subtasks and use multi-task learning strategies for joint training. The performance of our framework on an emotion recognition dataset is significantly superior to the traditional method of emotion classification and state-of-the-art zero-shot learning methods.
DanHAR: Dual Attention Network For Multimodal Human Activity Recognition Using Wearable Sensors
Jun 25, 2020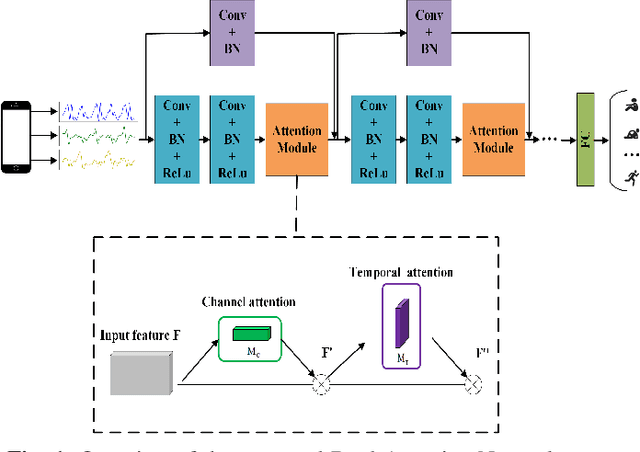
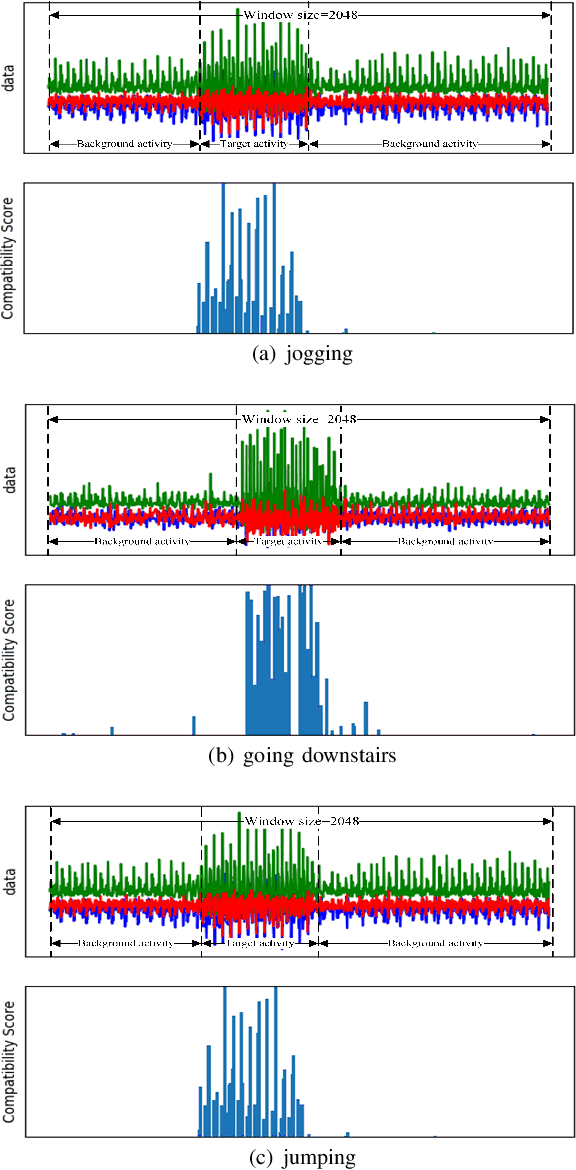
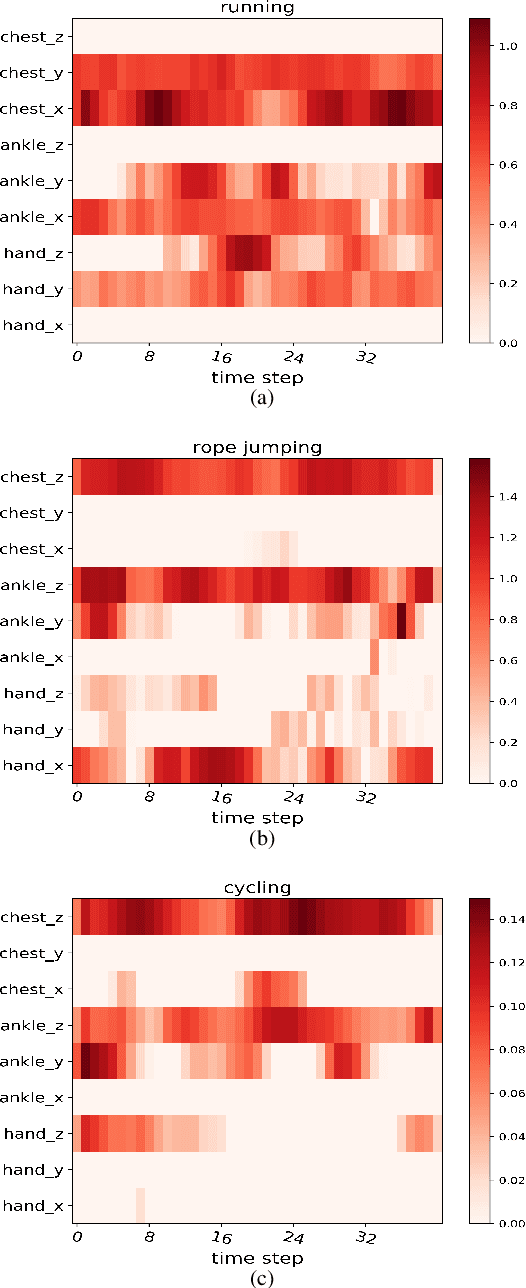
Human activity recognition (HAR) in ubiquitous computing has been beginning to incorporate attention into the context of deep neural networks (DNNs), in which the rich sensing data from multimodal sensors such as accelerometer and gyroscope is used to infer human activities. Recently, two attention methods are proposed via combining with Gated Recurrent Units (GRU) and Long Short-Term Memory (LSTM) network, which can capture the dependencies of sensing signals in both spatial and temporal domains simultaneously. However, recurrent networks often have a weak feature representing power compared with convolutional neural networks (CNNs). On the other hand, two attention, i.e., hard attention and soft attention, are applied in temporal domains via combining with CNN, which pay more attention to the target activity from a long sequence. However, they can only tell where to focus and miss channel information, which plays an important role in deciding what to focus. As a result, they fail to address the spatial-temporal dependencies of multimodal sensing signals, compared with attention-based GRU or LSTM. In the paper, we propose a novel dual attention method called DanHAR, which introduces the framework of blending channel attention and temporal attention on a CNN, demonstrating superiority in improving the comprehensibility for multimodal HAR. Extensive experiments on four public HAR datasets and weakly labeled dataset show that DanHAR achieves state-of-the-art performance with negligible overhead of parameters. Furthermore, visualizing analysis is provided to show that our attention can amplifies more important sensor modalities and timesteps during classification, which agrees well with human common intuition.
Uneven illumination surface defects inspection based on convolutional neural network
May 16, 2019Surface defect inspection based on machine vision is often affected by uneven illumination. In order to improve the inspection rate of surface defects inspection under uneven illumination condition, this paper proposes a method for detecting surface image defects based on convolutional neural network, which is based on the adjustment of convolutional neural networks, training parameters, changing the structure of the network, to achieve the purpose of accurately identifying various defects. Experimental on defect inspection of copper strip and steel images shows that the convolutional neural network can automatically learn features without preprocessing the image, and correct identification of various types of image defects affected by uneven illumination, thus overcoming the drawbacks of traditional machine vision inspection methods under uneven illumination.