 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLR-SGS: Robust LiDAR-Reflectance-Guided Salient Gaussian Splatting for Self-Driving Scene Reconstruction
Mar 13, 2026Recent 3D Gaussian Splatting (3DGS) methods have demonstrated the feasibility of self-driving scene reconstruction and novel view synthesis. However, most existing methods either rely solely on cameras or use LiDAR only for Gaussian initialization or depth supervision, while the rich scene information contained in point clouds, such as reflectance, and the complementarity between LiDAR and RGB have not been fully exploited, leading to degradation in challenging self-driving scenes, such as those with high ego-motion and complex lighting. To address these issues, we propose a robust and efficient LiDAR-reflectance-guided Salient Gaussian Splatting method (LR-SGS) for self-driving scenes, which introduces a structure-aware Salient Gaussian representation, initialized from geometric and reflectance feature points extracted from LiDAR and refined through a salient transform and improved density control to capture edge and planar structures. Furthermore, we calibrate LiDAR intensity into reflectance and attach it to each Gaussian as a lighting-invariant material channel, jointly aligned with RGB to enforce boundary consistency. Extensive experiments on the Waymo Open Dataset demonstrate that LR-SGS achieves superior reconstruction performance with fewer Gaussians and shorter training time. In particular, on Complex Lighting scenes, our method surpasses OmniRe by 1.18 dB PSNR.
Utonia: Toward One Encoder for All Point Clouds
Mar 03, 2026We dream of a future where point clouds from all domains can come together to shape a single model that benefits them all. Toward this goal, we present Utonia, a first step toward training a single self-supervised point transformer encoder across diverse domains, spanning remote sensing, outdoor LiDAR, indoor RGB-D sequences, object-centric CAD models, and point clouds lifted from RGB-only videos. Despite their distinct sensing geometries, densities, and priors, Utonia learns a consistent representation space that transfers across domains. This unification improves perception capability while revealing intriguing emergent behaviors that arise only when domains are trained jointly. Beyond perception, we observe that Utonia representations can also benefit embodied and multimodal reasoning: conditioning vision-language-action policies on Utonia features improves robotic manipulation, and integrating them into vision-language models yields gains on spatial reasoning. We hope Utonia can serve as a step toward foundation models for sparse 3D data, and support downstream applications in AR/VR, robotics, and autonomous driving.
Any3D-VLA: Enhancing VLA Robustness via Diverse Point Clouds
Jan 31, 2026Existing Vision-Language-Action (VLA) models typically take 2D images as visual input, which limits their spatial understanding in complex scenes. How can we incorporate 3D information to enhance VLA capabilities? We conduct a pilot study across different observation spaces and visual representations. The results show that explicitly lifting visual input into point clouds yields representations that better complement their corresponding 2D representations. To address the challenges of (1) scarce 3D data and (2) the domain gap induced by cross-environment differences and depth-scale biases, we propose Any3D-VLA. It unifies the simulator, sensor, and model-estimated point clouds within a training pipeline, constructs diverse inputs, and learns domain-agnostic 3D representations that are fused with the corresponding 2D representations. Simulation and real-world experiments demonstrate Any3D-VLA's advantages in improving performance and mitigating the domain gap. Our project homepage is available at https://xianzhefan.github.io/Any3D-VLA.github.io.
ProPy: Building Interactive Prompt Pyramids upon CLIP for Partially Relevant Video Retrieval
Aug 26, 2025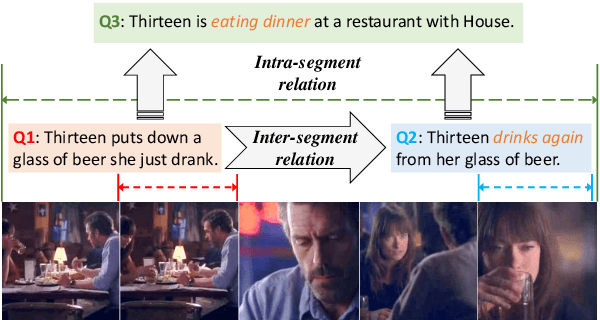

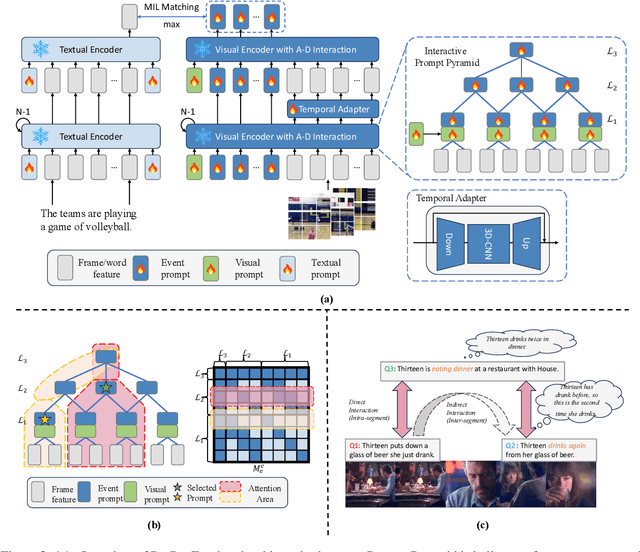
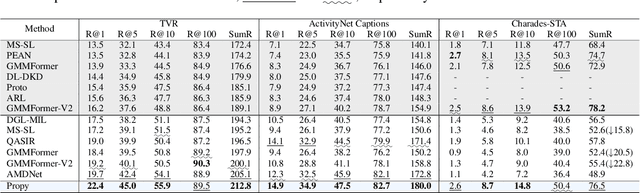
Partially Relevant Video Retrieval (PRVR) is a practical yet challenging task that involves retrieving videos based on queries relevant to only specific segments. While existing works follow the paradigm of developing models to process unimodal features, powerful pretrained vision-language models like CLIP remain underexplored in this field. To bridge this gap, we propose ProPy, a model with systematic architectural adaption of CLIP specifically designed for PRVR. Drawing insights from the semantic relevance of multi-granularity events, ProPy introduces two key innovations: (1) A Prompt Pyramid structure that organizes event prompts to capture semantics at multiple granularity levels, and (2) An Ancestor-Descendant Interaction Mechanism built on the pyramid that enables dynamic semantic interaction among events. With these designs, ProPy achieves SOTA performance on three public datasets, outperforming previous models by significant margins. Code is available at https://github.com/BUAAPY/ProPy.
Self-supervised Preference Optimization: Enhance Your Language Model with Preference Degree Awareness
Sep 26, 2024



Recently, there has been significant interest in replacing the reward model in Reinforcement Learning with Human Feedback (RLHF) methods for Large Language Models (LLMs), such as Direct Preference Optimization (DPO) and its variants. These approaches commonly use a binary cross-entropy mechanism on pairwise samples, i.e., minimizing and maximizing the loss based on preferred or dis-preferred responses, respectively. However, while this training strategy omits the reward model, it also overlooks the varying preference degrees within different responses. We hypothesize that this is a key factor hindering LLMs from sufficiently understanding human preferences. To address this problem, we propose a novel Self-supervised Preference Optimization (SPO) framework, which constructs a self-supervised preference degree loss combined with the alignment loss, thereby helping LLMs improve their ability to understand the degree of preference. Extensive experiments are conducted on two widely used datasets of different tasks. The results demonstrate that SPO can be seamlessly integrated with existing preference optimization methods and significantly boost their performance to achieve state-of-the-art performance. We also conduct detailed analyses to offer comprehensive insights into SPO, which verifies its effectiveness. The code is available at https://github.com/lijian16/SPO.
Understanding Public Safety Trends in Calgary through data mining
Jul 30, 2024This paper utilizes statistical data from various open datasets in Calgary to to uncover patterns and insights for community crimes, disorders, and traffic incidents. Community attributes like demographics, housing, and pet registration were collected and analyzed through geospatial visualization and correlation analysis. Strongly correlated features were identified using the chi-square test, and predictive models were built using association rule mining and machine learning algorithms. The findings suggest that crime rates are closely linked to factors such as population density, while pet registration has a smaller impact. This study offers valuable insights for city managers to enhance community safety strategies.
EPIDetect: Video-based convulsive seizure detection in chronic epilepsy mouse model for anti-epilepsy drug screening
May 31, 2024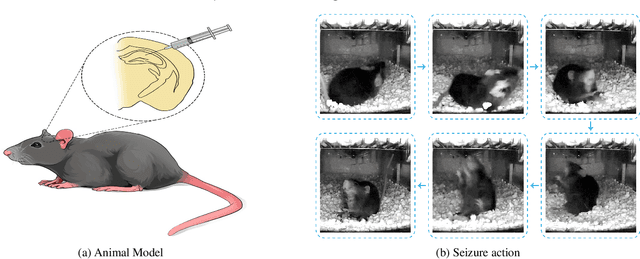
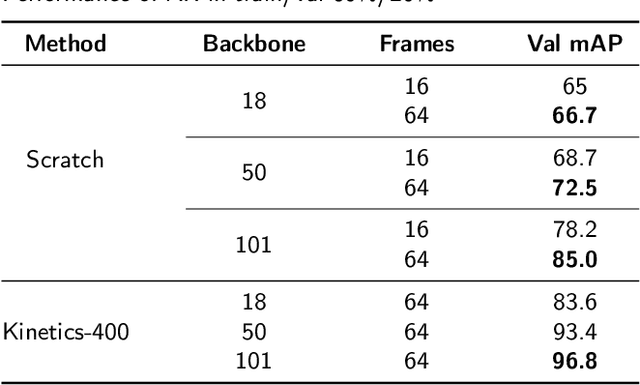
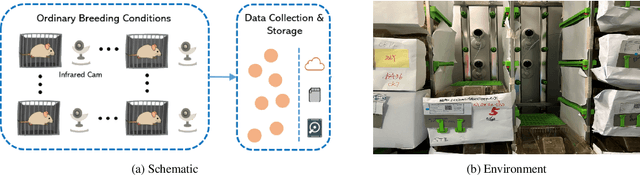
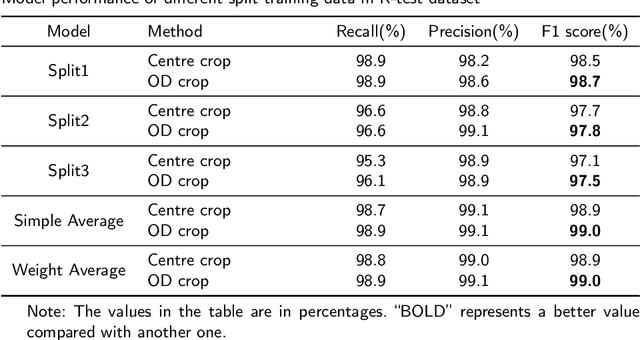
In the preclinical translational studies, drug candidates with remarkable anti-epileptic efficacy demonstrate long-term suppression of spontaneous recurrent seizures (SRSs), particularly convulsive seizures (CSs), in mouse models of chronic epilepsy. However, the current methods for monitoring CSs have limitations in terms of invasiveness, specific laboratory settings, high cost, and complex operation, which hinder drug screening efforts. In this study, a camera-based system for automated detection of CSs in chronically epileptic mice is first established to screen potential anti-epilepsy drugs.
DriveGPT4: Interpretable End-to-end Autonomous Driving via Large Language Model
Oct 08, 2023In the past decade, autonomous driving has experienced rapid development in both academia and industry. However, its limited interpretability remains a significant unsolved problem, severely hindering autonomous vehicle commercialization and further development. Previous approaches utilizing small language models have failed to address this issue due to their lack of flexibility, generalization ability, and robustness. Recently, multimodal large language models (LLMs) have gained considerable attention from the research community for their capability to process and reason non-text data (e.g., images and videos) by text. In this paper, we present DriveGPT4, an interpretable end-to-end autonomous driving system utilizing LLMs. DriveGPT4 is capable of interpreting vehicle actions and providing corresponding reasoning, as well as answering diverse questions posed by human users for enhanced interaction. Additionally, DriveGPT4 predicts vehicle low-level control signals in an end-to-end fashion. These capabilities stem from a customized visual instruction tuning dataset specifically designed for autonomous driving. To the best of our knowledge, DriveGPT4 is the first work focusing on interpretable end-to-end autonomous driving. When evaluated on multiple tasks alongside conventional methods and video understanding LLMs, DriveGPT4 demonstrates superior qualitative and quantitative performance. Additionally, DriveGPT4 can be generalized in a zero-shot fashion to accommodate more unseen scenarios. The project page is available at https://tonyxuqaq.github.io/projects/DriveGPT4/ .
SVCNet: Scribble-based Video Colorization Network with Temporal Aggregation
Mar 21, 2023



In this paper, we propose a scribble-based video colorization network with temporal aggregation called SVCNet. It can colorize monochrome videos based on different user-given color scribbles. It addresses three common issues in the scribble-based video colorization area: colorization vividness, temporal consistency, and color bleeding. To improve the colorization quality and strengthen the temporal consistency, we adopt two sequential sub-networks in SVCNet for precise colorization and temporal smoothing, respectively. The first stage includes a pyramid feature encoder to incorporate color scribbles with a grayscale frame, and a semantic feature encoder to extract semantics. The second stage finetunes the output from the first stage by aggregating the information of neighboring colorized frames (as short-range connections) and the first colorized frame (as a long-range connection). To alleviate the color bleeding artifacts, we learn video colorization and segmentation simultaneously. Furthermore, we set the majority of operations on a fixed small image resolution and use a Super-resolution Module at the tail of SVCNet to recover original sizes. It allows the SVCNet to fit different image resolutions at the inference. Finally, we evaluate the proposed SVCNet on DAVIS and Videvo benchmarks. The experimental results demonstrate that SVCNet produces both higher-quality and more temporally consistent videos than other well-known video colorization approaches. The codes and models can be found at https://github.com/zhaoyuzhi/SVCNet.
HDPV-SLAM: Hybrid Depth-augmented Panoramic Visual SLAM for Mobile Mapping System with Tilted LiDAR and Panoramic Visual Camera
Jan 27, 2023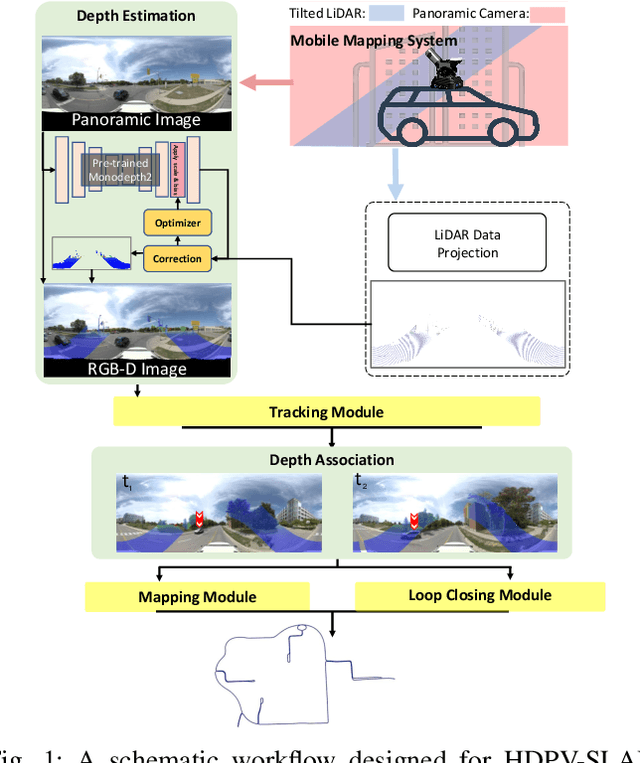
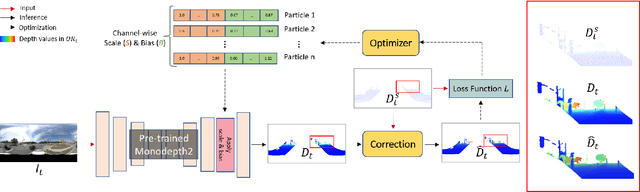


This paper proposes a novel visual simultaneous localization and mapping (SLAM), called Hybrid Depth-augmented Panoramic Visual SLAM (HDPV-SLAM), generating accurate and metrically scaled vehicle trajectories using a panoramic camera and a titled multi-beam LiDAR scanner. RGB-D SLAM served as the design foundation for HDPV-SLAM, adding depth information to visual features. It seeks to overcome the two problems that limit the performance of RGB-D SLAM systems. The first barrier is the sparseness of LiDAR depth, which makes it challenging to connect it with visual features extracted from the RGB image. We address this issue by proposing a depth estimation module for iteratively densifying sparse LiDAR depth based on deep learning (DL). The second issue relates to the challenges in the depth association caused by a significant deficiency of horizontal overlapping coverage between the panoramic camera and the tilted LiDAR sensor. To overcome this difficulty, we present a hybrid depth association module that optimally combines depth information estimated by two independent procedures, feature triangulation and depth estimation. This hybrid depth association module intends to maximize the use of more accurate depth information between the triangulated depth with visual features tracked and the DL-based corrected depth during a phase of feature tracking. We assessed HDPV-SLAM's performance using the 18.95 km-long York University and Teledyne Optech (YUTO) MMS dataset. Experimental results demonstrate that the proposed two modules significantly contribute to HDPV-SLAM's performance, which outperforms the state-of-the-art (SOTA) SLAM systems.