 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAncientBench: Towards Comprehensive Evaluation on Excavated and Transmitted Chinese Corpora
Dec 19, 2025
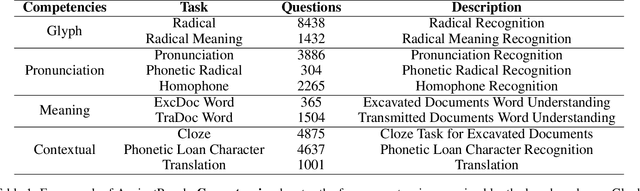

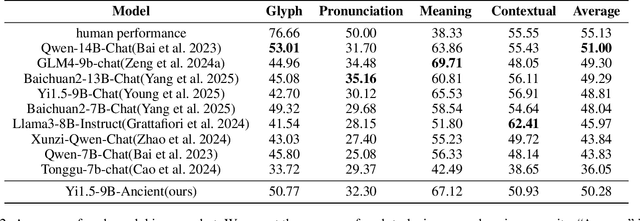
Comprehension of ancient texts plays an important role in archaeology and understanding of Chinese history and civilization. The rapid development of large language models needs benchmarks that can evaluate their comprehension of ancient characters. Existing Chinese benchmarks are mostly targeted at modern Chinese and transmitted documents in ancient Chinese, but the part of excavated documents in ancient Chinese is not covered. To meet this need, we propose the AncientBench, which aims to evaluate the comprehension of ancient characters, especially in the scenario of excavated documents. The AncientBench is divided into four dimensions, which correspond to the four competencies of ancient character comprehension: glyph comprehension, pronunciation comprehension, meaning comprehension, and contextual comprehension. The benchmark also contains ten tasks, including radical, phonetic radical, homophone, cloze, translation, and more, providing a comprehensive framework for evaluation. We convened archaeological researchers to conduct experimental evaluations, proposed an ancient model as baseline, and conducted extensive experiments on the currently best-performing large language models. The experimental results reveal the great potential of large language models in ancient textual scenarios as well as the gap with humans. Our research aims to promote the development and application of large language models in the field of archaeology and ancient Chinese language.
Ancient Script Image Recognition and Processing: A Review
Jun 24, 2025Ancient scripts, e.g., Egyptian hieroglyphs, Oracle Bone Inscriptions, and Ancient Greek inscriptions, serve as vital carriers of human civilization, embedding invaluable historical and cultural information. Automating ancient script image recognition has gained importance, enabling large-scale interpretation and advancing research in archaeology and digital humanities. With the rise of deep learning, this field has progressed rapidly, with numerous script-specific datasets and models proposed. While these scripts vary widely, spanning phonographic systems with limited glyphs to logographic systems with thousands of complex symbols, they share common challenges and methodological overlaps. Moreover, ancient scripts face unique challenges, including imbalanced data distribution and image degradation, which have driven the development of various dedicated methods. This survey provides a comprehensive review of ancient script image recognition methods. We begin by categorizing existing studies based on script types and analyzing respective recognition methods, highlighting both their differences and shared strategies. We then focus on challenges unique to ancient scripts, systematically examining their impact and reviewing recent solutions, including few-shot learning and noise-robust techniques. Finally, we summarize current limitations and outline promising future directions. Our goal is to offer a structured, forward-looking perspective to support ongoing advancements in the recognition, interpretation, and decipherment of ancient scripts.
Self-supervised Preference Optimization: Enhance Your Language Model with Preference Degree Awareness
Sep 26, 2024



Recently, there has been significant interest in replacing the reward model in Reinforcement Learning with Human Feedback (RLHF) methods for Large Language Models (LLMs), such as Direct Preference Optimization (DPO) and its variants. These approaches commonly use a binary cross-entropy mechanism on pairwise samples, i.e., minimizing and maximizing the loss based on preferred or dis-preferred responses, respectively. However, while this training strategy omits the reward model, it also overlooks the varying preference degrees within different responses. We hypothesize that this is a key factor hindering LLMs from sufficiently understanding human preferences. To address this problem, we propose a novel Self-supervised Preference Optimization (SPO) framework, which constructs a self-supervised preference degree loss combined with the alignment loss, thereby helping LLMs improve their ability to understand the degree of preference. Extensive experiments are conducted on two widely used datasets of different tasks. The results demonstrate that SPO can be seamlessly integrated with existing preference optimization methods and significantly boost their performance to achieve state-of-the-art performance. We also conduct detailed analyses to offer comprehensive insights into SPO, which verifies its effectiveness. The code is available at https://github.com/lijian16/SPO.
Toward Zero-shot Character Recognition: A Gold Standard Dataset with Radical-level Annotations
Aug 01, 2023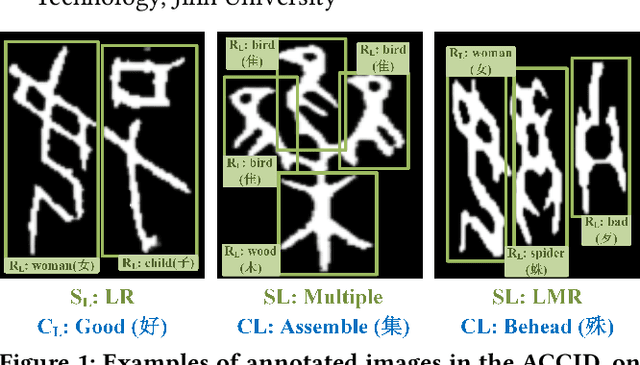
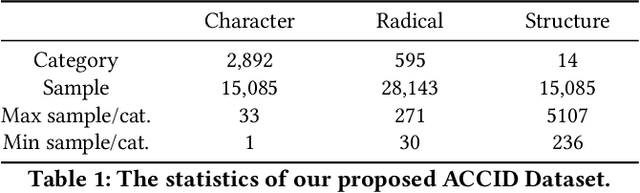
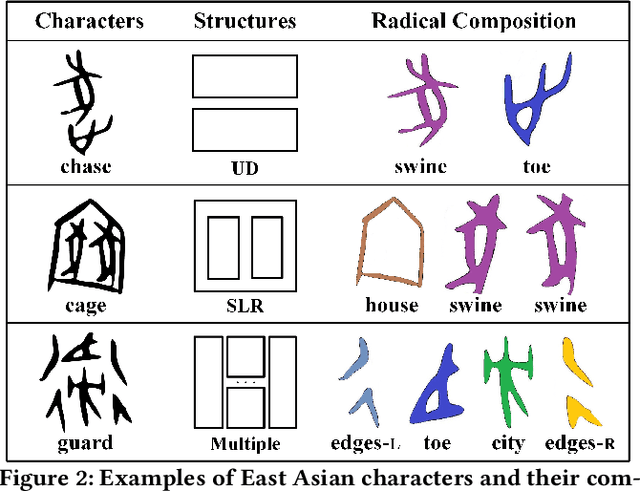

Optical character recognition (OCR) methods have been applied to diverse tasks, e.g., street view text recognition and document analysis. Recently, zero-shot OCR has piqued the interest of the research community because it considers a practical OCR scenario with unbalanced data distribution. However, there is a lack of benchmarks for evaluating such zero-shot methods that apply a divide-and-conquer recognition strategy by decomposing characters into radicals. Meanwhile, radical recognition, as another important OCR task, also lacks radical-level annotation for model training. In this paper, we construct an ancient Chinese character image dataset that contains both radical-level and character-level annotations to satisfy the requirements of the above-mentioned methods, namely, ACCID, where radical-level annotations include radical categories, radical locations, and structural relations. To increase the adaptability of ACCID, we propose a splicing-based synthetic character algorithm to augment the training samples and apply an image denoising method to improve the image quality. By introducing character decomposition and recombination, we propose a baseline method for zero-shot OCR. The experimental results demonstrate the validity of ACCID and the baseline model quantitatively and qualitatively.
CharFormer: A Glyph Fusion based Attentive Framework for High-precision Character Image Denoising
Jul 19, 2022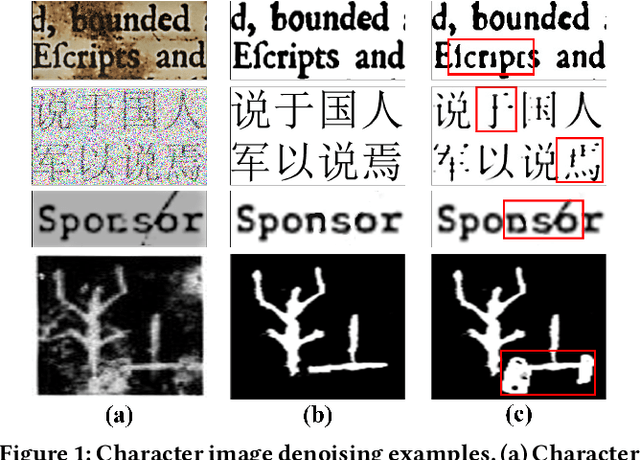
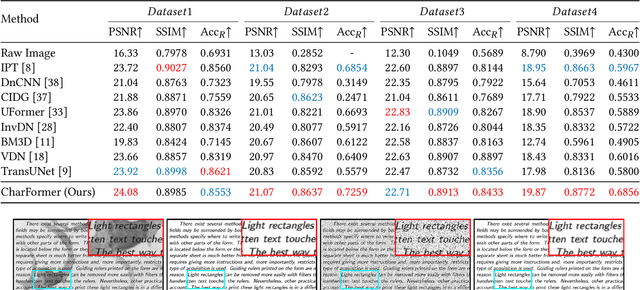
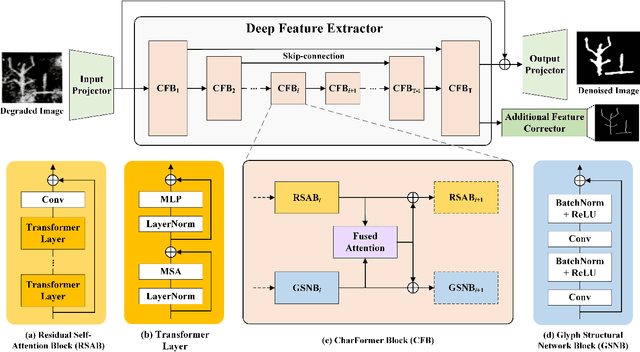
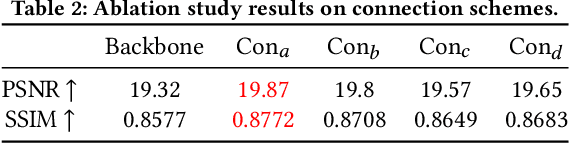
Degraded images commonly exist in the general sources of character images, leading to unsatisfactory character recognition results. Existing methods have dedicated efforts to restoring degraded character images. However, the denoising results obtained by these methods do not appear to improve character recognition performance. This is mainly because current methods only focus on pixel-level information and ignore critical features of a character, such as its glyph, resulting in character-glyph damage during the denoising process. In this paper, we introduce a novel generic framework based on glyph fusion and attention mechanisms, i.e., CharFormer, for precisely recovering character images without changing their inherent glyphs. Unlike existing frameworks, CharFormer introduces a parallel target task for capturing additional information and injecting it into the image denoising backbone, which will maintain the consistency of character glyphs during character image denoising. Moreover, we utilize attention-based networks for global-local feature interaction, which will help to deal with blind denoising and enhance denoising performance. We compare CharFormer with state-of-the-art methods on multiple datasets. The experimental results show the superiority of CharFormer quantitatively and qualitatively.