 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructLayoutFormer:Conditional Structured Layout Generation via Structure Serialization and Disentanglement
Oct 30, 2025Structured layouts are preferable in many 2D visual contents (\eg, GUIs, webpages) since the structural information allows convenient layout editing. Computational frameworks can help create structured layouts but require heavy labor input. Existing data-driven approaches are effective in automatically generating fixed layouts but fail to produce layout structures. We present StructLayoutFormer, a novel Transformer-based approach for conditional structured layout generation. We use a structure serialization scheme to represent structured layouts as sequences. To better control the structures of generated layouts, we disentangle the structural information from the element placements. Our approach is the first data-driven approach that achieves conditional structured layout generation and produces realistic layout structures explicitly. We compare our approach with existing data-driven layout generation approaches by including post-processing for structure extraction. Extensive experiments have shown that our approach exceeds these baselines in conditional structured layout generation. We also demonstrate that our approach is effective in extracting and transferring layout structures. The code is publicly available at %\href{https://github.com/Teagrus/StructLayoutFormer} {https://github.com/Teagrus/StructLayoutFormer}.
StrokeFusion: Vector Sketch Generation via Joint Stroke-UDF Encoding and Latent Sequence Diffusion
Mar 31, 2025In the field of sketch generation, raster-format trained models often produce non-stroke artifacts, while vector-format trained models typically lack a holistic understanding of sketches, leading to compromised recognizability. Moreover, existing methods struggle to extract common features from similar elements (e.g., eyes of animals) appearing at varying positions across sketches. To address these challenges, we propose StrokeFusion, a two-stage framework for vector sketch generation. It contains a dual-modal sketch feature learning network that maps strokes into a high-quality latent space. This network decomposes sketches into normalized strokes and jointly encodes stroke sequences with Unsigned Distance Function (UDF) maps, representing sketches as sets of stroke feature vectors. Building upon this representation, our framework exploits a stroke-level latent diffusion model that simultaneously adjusts stroke position, scale, and trajectory during generation. This enables high-fidelity sketch generation while supporting stroke interpolation editing. Extensive experiments on the QuickDraw dataset demonstrate that our framework outperforms state-of-the-art techniques, validating its effectiveness in preserving structural integrity and semantic features. Code and models will be made publicly available upon publication.
Bridge then Begin Anew: Generating Target-relevant Intermediate Model for Source-free Visual Emotion Adaptation
Dec 18, 2024



Visual emotion recognition (VER), which aims at understanding humans' emotional reactions toward different visual stimuli, has attracted increasing attention. Given the subjective and ambiguous characteristics of emotion, annotating a reliable large-scale dataset is hard. For reducing reliance on data labeling, domain adaptation offers an alternative solution by adapting models trained on labeled source data to unlabeled target data. Conventional domain adaptation methods require access to source data. However, due to privacy concerns, source emotional data may be inaccessible. To address this issue, we propose an unexplored task: source-free domain adaptation (SFDA) for VER, which does not have access to source data during the adaptation process. To achieve this, we propose a novel framework termed Bridge then Begin Anew (BBA), which consists of two steps: domain-bridged model generation (DMG) and target-related model adaptation (TMA). First, the DMG bridges cross-domain gaps by generating an intermediate model, avoiding direct alignment between two VER datasets with significant differences. Then, the TMA begins training the target model anew to fit the target structure, avoiding the influence of source-specific knowledge. Extensive experiments are conducted on six SFDA settings for VER. The results demonstrate the effectiveness of BBA, which achieves remarkable performance gains compared with state-of-the-art SFDA methods and outperforms representative unsupervised domain adaptation approaches.
Self-supervised Preference Optimization: Enhance Your Language Model with Preference Degree Awareness
Sep 26, 2024



Recently, there has been significant interest in replacing the reward model in Reinforcement Learning with Human Feedback (RLHF) methods for Large Language Models (LLMs), such as Direct Preference Optimization (DPO) and its variants. These approaches commonly use a binary cross-entropy mechanism on pairwise samples, i.e., minimizing and maximizing the loss based on preferred or dis-preferred responses, respectively. However, while this training strategy omits the reward model, it also overlooks the varying preference degrees within different responses. We hypothesize that this is a key factor hindering LLMs from sufficiently understanding human preferences. To address this problem, we propose a novel Self-supervised Preference Optimization (SPO) framework, which constructs a self-supervised preference degree loss combined with the alignment loss, thereby helping LLMs improve their ability to understand the degree of preference. Extensive experiments are conducted on two widely used datasets of different tasks. The results demonstrate that SPO can be seamlessly integrated with existing preference optimization methods and significantly boost their performance to achieve state-of-the-art performance. We also conduct detailed analyses to offer comprehensive insights into SPO, which verifies its effectiveness. The code is available at https://github.com/lijian16/SPO.
Multi-source Domain Adaptation for Panoramic Semantic Segmentation
Aug 29, 2024



Panoramic semantic segmentation has received widespread attention recently due to its comprehensive 360\degree field of view. However, labeling such images demands greater resources compared to pinhole images. As a result, many unsupervised domain adaptation methods for panoramic semantic segmentation have emerged, utilizing real pinhole images or low-cost synthetic panoramic images. But, the segmentation model lacks understanding of the panoramic structure when only utilizing real pinhole images, and it lacks perception of real-world scenes when only adopting synthetic panoramic images. Therefore, in this paper, we propose a new task of multi-source domain adaptation for panoramic semantic segmentation, aiming to utilize both real pinhole and synthetic panoramic images in the source domains, enabling the segmentation model to perform well on unlabeled real panoramic images in the target domain. Further, we propose Deformation Transform Aligner for Panoramic Semantic Segmentation (DTA4PASS), which converts all pinhole images in the source domains into panoramic-like images, and then aligns the converted source domains with the target domain. Specifically, DTA4PASS consists of two main components: Unpaired Semantic Morphing (USM) and Distortion Gating Alignment (DGA). Firstly, in USM, the Semantic Dual-view Discriminator (SDD) assists in training the diffeomorphic deformation network, enabling the effective transformation of pinhole images without paired panoramic views. Secondly, DGA assigns pinhole-like and panoramic-like features to each image by gating, and aligns these two features through uncertainty estimation. DTA4PASS outperforms the previous state-of-the-art methods by 1.92% and 2.19% on the outdoor and indoor multi-source domain adaptation scenarios, respectively. The source code will be released.
LLMI3D: Empowering LLM with 3D Perception from a Single 2D Image
Aug 14, 2024

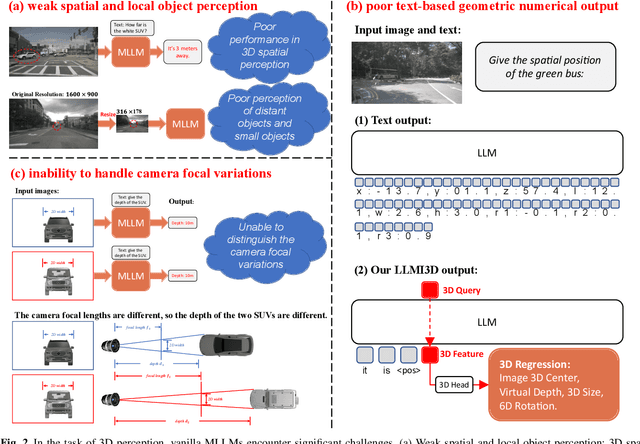

Recent advancements in autonomous driving, augmented reality, robotics, and embodied intelligence have necessitated 3D perception algorithms. However, current 3D perception methods, particularly small models, struggle with processing logical reasoning, question-answering, and handling open scenario categories. On the other hand, generative multimodal large language models (MLLMs) excel in general capacity but underperform in 3D tasks, due to weak spatial and local object perception, poor text-based geometric numerical output, and inability to handle camera focal variations. To address these challenges, we propose the following solutions: Spatial-Enhanced Local Feature Mining for better spatial feature extraction, 3D Query Token-Derived Info Decoding for precise geometric regression, and Geometry Projection-Based 3D Reasoning for handling camera focal length variations. We employ parameter-efficient fine-tuning for a pre-trained MLLM and develop LLMI3D, a powerful 3D perception MLLM. Additionally, we have constructed the IG3D dataset, which provides fine-grained descriptions and question-answer annotations. Extensive experiments demonstrate that our LLMI3D achieves state-of-the-art performance, significantly outperforming existing methods.
FRI-Net: Floorplan Reconstruction via Room-wise Implicit Representation
Jul 15, 2024



In this paper, we introduce a novel method called FRI-Net for 2D floorplan reconstruction from 3D point cloud. Existing methods typically rely on corner regression or box regression, which lack consideration for the global shapes of rooms. To address these issues, we propose a novel approach using a room-wise implicit representation with structural regularization to characterize the shapes of rooms in floorplans. By incorporating geometric priors of room layouts in floorplans into our training strategy, the generated room polygons are more geometrically regular. We have conducted experiments on two challenging datasets, Structured3D and SceneCAD. Our method demonstrates improved performance compared to state-of-the-art methods, validating the effectiveness of our proposed representation for floorplan reconstruction.
MapVision: CVPR 2024 Autonomous Grand Challenge Mapless Driving Tech Report
Jun 14, 2024



Autonomous driving without high-definition (HD) maps demands a higher level of active scene understanding. In this competition, the organizers provided the multi-perspective camera images and standard-definition (SD) maps to explore the boundaries of scene reasoning capabilities. We found that most existing algorithms construct Bird's Eye View (BEV) features from these multi-perspective images and use multi-task heads to delineate road centerlines, boundary lines, pedestrian crossings, and other areas. However, these algorithms perform poorly at the far end of roads and struggle when the primary subject in the image is occluded. Therefore, in this competition, we not only used multi-perspective images as input but also incorporated SD maps to address this issue. We employed map encoder pre-training to enhance the network's geometric encoding capabilities and utilized YOLOX to improve traffic element detection precision. Additionally, for area detection, we innovatively introduced LDTR and auxiliary tasks to achieve higher precision. As a result, our final OLUS score is 0.58.
More is Better: Deep Domain Adaptation with Multiple Sources
May 01, 2024In many practical applications, it is often difficult and expensive to obtain large-scale labeled data to train state-of-the-art deep neural networks. Therefore, transferring the learned knowledge from a separate, labeled source domain to an unlabeled or sparsely labeled target domain becomes an appealing alternative. However, direct transfer often results in significant performance decay due to domain shift. Domain adaptation (DA) aims to address this problem by aligning the distributions between the source and target domains. Multi-source domain adaptation (MDA) is a powerful and practical extension in which the labeled data may be collected from multiple sources with different distributions. In this survey, we first define various MDA strategies. Then we systematically summarize and compare modern MDA methods in the deep learning era from different perspectives, followed by commonly used datasets and a brief benchmark. Finally, we discuss future research directions for MDA that are worth investigating.
LDTR: Transformer-based Lane Detection with Anchor-chain Representation
Mar 21, 2024Despite recent advances in lane detection methods, scenarios with limited- or no-visual-clue of lanes due to factors such as lighting conditions and occlusion remain challenging and crucial for automated driving. Moreover, current lane representations require complex post-processing and struggle with specific instances. Inspired by the DETR architecture, we propose LDTR, a transformer-based model to address these issues. Lanes are modeled with a novel anchor-chain, regarding a lane as a whole from the beginning, which enables LDTR to handle special lanes inherently. To enhance lane instance perception, LDTR incorporates a novel multi-referenced deformable attention module to distribute attention around the object. Additionally, LDTR incorporates two line IoU algorithms to improve convergence efficiency and employs a Gaussian heatmap auxiliary branch to enhance model representation capability during training. To evaluate lane detection models, we rely on Frechet distance, parameterized F1-score, and additional synthetic metrics. Experimental results demonstrate that LDTR achieves state-of-the-art performance on well-known datasets.