 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLDTR: Transformer-based Lane Detection with Anchor-chain Representation
Mar 21, 2024Despite recent advances in lane detection methods, scenarios with limited- or no-visual-clue of lanes due to factors such as lighting conditions and occlusion remain challenging and crucial for automated driving. Moreover, current lane representations require complex post-processing and struggle with specific instances. Inspired by the DETR architecture, we propose LDTR, a transformer-based model to address these issues. Lanes are modeled with a novel anchor-chain, regarding a lane as a whole from the beginning, which enables LDTR to handle special lanes inherently. To enhance lane instance perception, LDTR incorporates a novel multi-referenced deformable attention module to distribute attention around the object. Additionally, LDTR incorporates two line IoU algorithms to improve convergence efficiency and employs a Gaussian heatmap auxiliary branch to enhance model representation capability during training. To evaluate lane detection models, we rely on Frechet distance, parameterized F1-score, and additional synthetic metrics. Experimental results demonstrate that LDTR achieves state-of-the-art performance on well-known datasets.
CANet: Curved Guide Line Network with Adaptive Decoder for Lane Detection
Apr 23, 2023



Lane detection is challenging due to the complicated on road scenarios and line deformation from different camera perspectives. Lots of solutions were proposed, but can not deal with corner lanes well. To address this problem, this paper proposes a new top-down deep learning lane detection approach, CANET. A lane instance is first responded by the heat-map on the U-shaped curved guide line at global semantic level, thus the corresponding features of each lane are aggregated at the response point. Then CANET obtains the heat-map response of the entire lane through conditional convolution, and finally decodes the point set to describe lanes via adaptive decoder. The experimental results show that CANET reaches SOTA in different metrics. Our code will be released soon.
ReadNet:Towards Accurate ReID with Limited and Noisy Samples
May 12, 2020

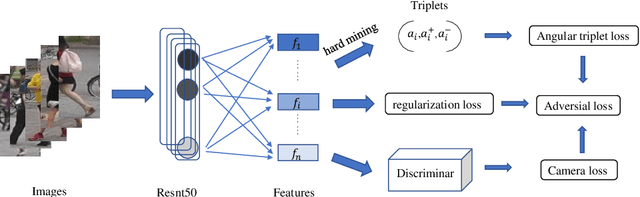
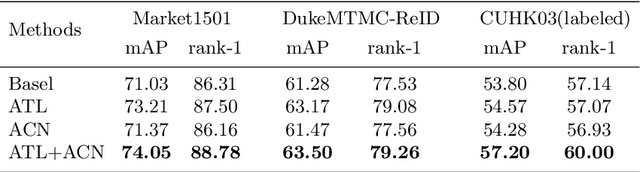
Person re-identification (ReID) is an essential cross-camera retrieval task to identify pedestrians. However, the photo number of each pedestrian usually differs drastically, and thus the data limitation and imbalance problem hinders the prediction accuracy greatly. Additionally, in real-world applications, pedestrian images are captured by different surveillance cameras, so the noisy camera related information, such as the lights, perspectives and resolutions, result in inevitable domain gaps for ReID algorithms. These challenges bring difficulties to current deep learning methods with triplet loss for coping with such problems. To address these challenges, this paper proposes ReadNet, an adversarial camera network (ACN) with an angular triplet loss (ATL). In detail, ATL focuses on learning the angular distance among different identities to mitigate the effect of data imbalance, and guarantees a linear decision boundary as well, while ACN takes the camera discriminator as a game opponent of feature extractor to filter camera related information to bridge the multi-camera gaps. ReadNet is designed to be flexible so that either ATL or ACN can be deployed independently or simultaneously. The experiment results on various benchmark datasets have shown that ReadNet can deliver better prediction performance than current state-of-the-art methods.