 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Optimizable to Interactable: Mixed Digital Twin-Empowered Testing of Vehicle-Infrastructure Cooperation Systems
Mar 19, 2026Sufficient testing under corner cases is critical for the long-term operation of vehicle-infrastructure cooperation systems (VICS). However, existing corner-case generation methods are primarily AI-driven, and VICS testing under corner cases is typically limited to simulation. In this paper, we introduce an L5 ''Interactable'' level to the VICS digital twin (VICS-DT) taxonomy, extending beyond the conventional L4 ''Optimizable'' level. We further propose an L5-level VICS testing framework, IMPACT (Interactive Mixed-digital-twin Paradigm for Advanced Cooperative vehicle-infrastructure Testing). By enabling direct human interactions with VICS entities, IMPACT incorporates highly uncertain and unpredictable human behaviors into the testing loop, naturally generating high-quality corner cases that complement AI-based methods. Furthermore, the mixedDT-enabled ''Physical-Virtual Action Interaction'' facilitates safe VICS testing under corner cases, incorporating real-world environments and entities rather than purely in simulation. Finally, we implement IMPACT on the I-VIT (Interactive Vehicle-Infrastructure Testbed), and experiments demonstrate its effectiveness. The experimental videos are available at our project website: https://dongjh20.github.io/IMPACT.
Multi-Source Human-in-the-Loop Digital Twin Testbed for Connected and Autonomous Vehicles in Mixed Traffic Flow
Mar 18, 2026In the emerging mixed traffic environments, Connected and Autonomous Vehicles (CAVs) have to interact with surrounding human-driven vehicles (HDVs). This paper introduces MSH-MCCT (Multi-Source Human-in-the-Loop Mixed Cloud Control Testbed), a novel CAV testbed that captures complex interactions between various CAVs and HDVs. Utilizing the Mixed Digital Twin concept, which combines Mixed Reality with Digital Twin, MSH-MCCT integrates physical, virtual, and mixed platforms, along with multi-source control inputs. Bridged by the mixed platform, MSH-MCCT allows human drivers and CAV algorithms to operate both physical and virtual vehicles within multiple fields of view. Particularly, this testbed facilitates the coexistence and real-time interaction of physical and virtual CAVs \& HDVs, significantly enhancing the experimental flexibility and scalability. Experiments on vehicle platooning in mixed traffic showcase the potential of MSH-MCCT to conduct CAV testing with multi-source real human drivers in the loop through driving simulators of diverse fidelity. The videos for the experiments are available at our project website: https://dongjh20.github.io/MSH-MCCT.
WaveRNet: Wavelet-Guided Frequency Learning for Multi-Source Domain-Generalized Retinal Vessel Segmentation
Jan 09, 2026Domain-generalized retinal vessel segmentation is critical for automated ophthalmic diagnosis, yet faces significant challenges from domain shift induced by non-uniform illumination and varying contrast, compounded by the difficulty of preserving fine vessel structures. While the Segment Anything Model (SAM) exhibits remarkable zero-shot capabilities, existing SAM-based methods rely on simple adapter fine-tuning while overlooking frequency-domain information that encodes domain-invariant features, resulting in degraded generalization under illumination and contrast variations. Furthermore, SAM's direct upsampling inevitably loses fine vessel details. To address these limitations, we propose WaveRNet, a wavelet-guided frequency learning framework for robust multi-source domain-generalized retinal vessel segmentation. Specifically, we devise a Spectral-guided Domain Modulator (SDM) that integrates wavelet decomposition with learnable domain tokens, enabling the separation of illumination-robust low-frequency structures from high-frequency vessel boundaries while facilitating domain-specific feature generation. Furthermore, we introduce a Frequency-Adaptive Domain Fusion (FADF) module that performs intelligent test-time domain selection through wavelet-based frequency similarity and soft-weighted fusion. Finally, we present a Hierarchical Mask-Prompt Refiner (HMPR) that overcomes SAM's upsampling limitation through coarse-to-fine refinement with long-range dependency modeling. Extensive experiments under the Leave-One-Domain-Out protocol on four public retinal datasets demonstrate that WaveRNet achieves state-of-the-art generalization performance. The source code is available at https://github.com/Chanchan-Wang/WaveRNet.
RoLID-11K: A Dashcam Dataset for Small-Object Roadside Litter Detection
Jan 01, 2026Roadside litter poses environmental, safety and economic challenges, yet current monitoring relies on labour-intensive surveys and public reporting, providing limited spatial coverage. Existing vision datasets for litter detection focus on street-level still images, aerial scenes or aquatic environments, and do not reflect the unique characteristics of dashcam footage, where litter appears extremely small, sparse and embedded in cluttered road-verge backgrounds. We introduce RoLID-11K, the first large-scale dataset for roadside litter detection from dashcams, comprising over 11k annotated images spanning diverse UK driving conditions and exhibiting pronounced long-tail and small-object distributions. We benchmark a broad spectrum of modern detectors, from accuracy-oriented transformer architectures to real-time YOLO models, and analyse their strengths and limitations on this challenging task. Our results show that while CO-DETR and related transformers achieve the best localisation accuracy, real-time models remain constrained by coarse feature hierarchies. RoLID-11K establishes a challenging benchmark for extreme small-object detection in dynamic driving scenes and aims to support the development of scalable, low-cost systems for roadside-litter monitoring. The dataset is available at https://github.com/xq141839/RoLID-11K.
FreqDINO: Frequency-Guided Adaptation for Generalized Boundary-Aware Ultrasound Image Segmentation
Dec 12, 2025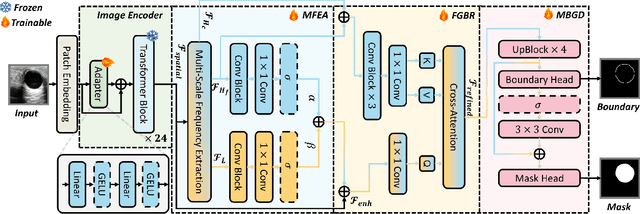
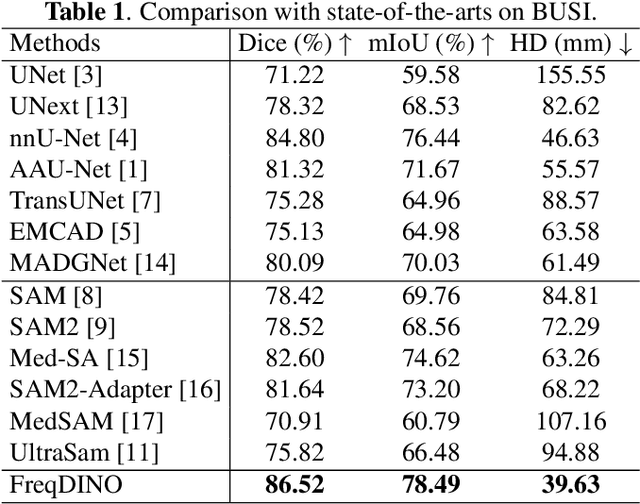
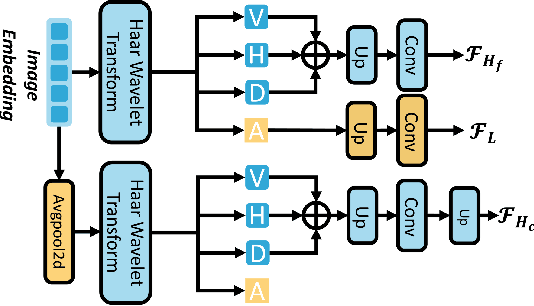
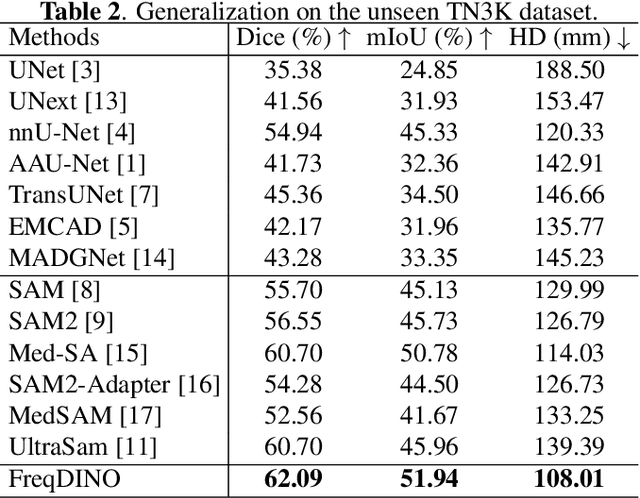
Ultrasound image segmentation is pivotal for clinical diagnosis, yet challenged by speckle noise and imaging artifacts. Recently, DINOv3 has shown remarkable promise in medical image segmentation with its powerful representation capabilities. However, DINOv3, pre-trained on natural images, lacks sensitivity to ultrasound-specific boundary degradation. To address this limitation, we propose FreqDINO, a frequency-guided segmentation framework that enhances boundary perception and structural consistency. Specifically, we devise a Multi-scale Frequency Extraction and Alignment (MFEA) strategy to separate low-frequency structures and multi-scale high-frequency boundary details, and align them via learnable attention. We also introduce a Frequency-Guided Boundary Refinement (FGBR) module that extracts boundary prototypes from high-frequency components and refines spatial features. Furthermore, we design a Multi-task Boundary-Guided Decoder (MBGD) to ensure spatial coherence between boundary and semantic predictions. Extensive experiments demonstrate that FreqDINO surpasses state-of-the-art methods with superior achieves remarkable generalization capability. The code is at https://github.com/MingLang-FD/FreqDINO.
LapFM: A Laparoscopic Segmentation Foundation Model via Hierarchical Concept Evolving Pre-training
Dec 09, 2025Surgical segmentation is pivotal for scene understanding yet remains hindered by annotation scarcity and semantic inconsistency across diverse procedures. Existing approaches typically fine-tune natural foundation models (e.g., SAM) with limited supervision, functioning merely as domain adapters rather than surgical foundation models. Consequently, they struggle to generalize across the vast variability of surgical targets. To bridge this gap, we present LapFM, a foundation model designed to evolve robust segmentation capabilities from massive unlabeled surgical images. Distinct from medical foundation models relying on inefficient self-supervised proxy tasks, LapFM leverages a Hierarchical Concept Evolving Pre-training paradigm. First, we establish a Laparoscopic Concept Hierarchy (LCH) via a hierarchical mask decoder with parent-child query embeddings, unifying diverse entities (i.e., Anatomy, Tissue, and Instrument) into a scalable knowledge structure with cross-granularity semantic consistency. Second, we propose a Confidence-driven Evolving Labeling that iteratively generates and filters pseudo-labels based on hierarchical consistency, progressively incorporating reliable samples from unlabeled images into training. This process yields LapBench-114K, a large-scale benchmark comprising 114K image-mask pairs. Extensive experiments demonstrate that LapFM significantly outperforms state-of-the-art methods, establishing new standards for granularity-adaptive generalization in universal laparoscopic segmentation. The source code is available at https://github.com/xq141839/LapFM.
TM-UNet: Token-Memory Enhanced Sequential Modeling for Efficient Medical Image Segmentation
Nov 15, 2025Medical image segmentation is essential for clinical diagnosis and treatment planning. Although transformer-based methods have achieved remarkable results, their high computational cost hinders clinical deployment. To address this issue, we propose TM-UNet, a novel lightweight framework that integrates token sequence modeling with an efficient memory mechanism for efficient medical segmentation. Specifically, we introduce a multi-scale token-memory (MSTM) block that transforms 2D spatial features into token sequences through strategic spatial scanning, leveraging matrix memory cells to selectively retain and propagate discriminative contextual information across tokens. This novel token-memory mechanism acts as a dynamic knowledge store that captures long-range dependencies with linear complexity, enabling efficient global reasoning without redundant computation. Our MSTM block further incorporates exponential gating to identify token effectiveness and multi-scale contextual extraction via parallel pooling operations, enabling hierarchical representation learning without computational overhead. Extensive experiments demonstrate that TM-UNet outperforms state-of-the-art methods across diverse medical segmentation tasks with substantially reduced computation cost. The code is available at https://github.com/xq141839/TM-UNet.
CoMA: Complementary Masking and Hierarchical Dynamic Multi-Window Self-Attention in a Unified Pre-training Framework
Nov 08, 2025Masked Autoencoders (MAE) achieve self-supervised learning of image representations by randomly removing a portion of visual tokens and reconstructing the original image as a pretext task, thereby significantly enhancing pretraining efficiency and yielding excellent adaptability across downstream tasks. However, MAE and other MAE-style paradigms that adopt random masking generally require more pre-training epochs to maintain adaptability. Meanwhile, ViT in MAE suffers from inefficient parameter use due to fixed spatial resolution across layers. To overcome these limitations, we propose the Complementary Masked Autoencoders (CoMA), which employ a complementary masking strategy to ensure uniform sampling across all pixels, thereby improving effective learning of all features and enhancing the model's adaptability. Furthermore, we introduce DyViT, a hierarchical vision transformer that employs a Dynamic Multi-Window Self-Attention (DM-MSA), significantly reducing the parameters and FLOPs while improving fine-grained feature learning. Pre-trained on ImageNet-1K with CoMA, DyViT matches the downstream performance of MAE using only 12% of the pre-training epochs, demonstrating more effective learning. It also attains a 10% reduction in pre-training time per epoch, further underscoring its superior pre-training efficiency.
LinguaSim: Interactive Multi-Vehicle Testing Scenario Generation via Natural Language Instruction Based on Large Language Models
Oct 09, 2025The generation of testing and training scenarios for autonomous vehicles has drawn significant attention. While Large Language Models (LLMs) have enabled new scenario generation methods, current methods struggle to balance command adherence accuracy with the realism of real-world driving environments. To reduce scenario description complexity, these methods often compromise realism by limiting scenarios to 2D, or open-loop simulations where background vehicles follow predefined, non-interactive behaviors. We propose LinguaSim, an LLM-based framework that converts natural language into realistic, interactive 3D scenarios, ensuring both dynamic vehicle interactions and faithful alignment between the input descriptions and the generated scenarios. A feedback calibration module further refines the generation precision, improving fidelity to user intent. By bridging the gap between natural language and closed-loop, interactive simulations, LinguaSim constrains adversarial vehicle behaviors using both the scenario description and the autonomous driving model guiding them. This framework facilitates the creation of high-fidelity scenarios that enhance safety testing and training. Experiments show LinguaSim can generate scenarios with varying criticality aligned with different natural language descriptions (ACT: 0.072 s for dangerous vs. 3.532 s for safe descriptions; comfortability: 0.654 vs. 0.764), and its refinement module effectively reduces excessive aggressiveness in LinguaSim's initial outputs, lowering the crash rate from 46.9% to 6.3% to better match user intentions.
MasHost Builds It All: Autonomous Multi-Agent System Directed by Reinforcement Learning
Jun 12, 2025Large Language Model (LLM)-driven Multi-agent systems (Mas) have recently emerged as a powerful paradigm for tackling complex real-world tasks. However, existing Mas construction methods typically rely on manually crafted interaction mechanisms or heuristic rules, introducing human biases and constraining the autonomous ability. Even with recent advances in adaptive Mas construction, existing systems largely remain within the paradigm of semi-autonomous patterns. In this work, we propose MasHost, a Reinforcement Learning (RL)-based framework for autonomous and query-adaptive Mas design. By formulating Mas construction as a graph search problem, our proposed MasHost jointly samples agent roles and their interactions through a unified probabilistic sampling mechanism. Beyond the accuracy and efficiency objectives pursued in prior works, we introduce component rationality as an additional and novel design principle in Mas. To achieve this multi-objective optimization, we propose Hierarchical Relative Policy Optimization (HRPO), a novel RL strategy that collaboratively integrates group-relative advantages and action-wise rewards. To our knowledge, our proposed MasHost is the first RL-driven framework for autonomous Mas graph construction. Extensive experiments on six benchmarks demonstrate that MasHost consistently outperforms most competitive baselines, validating its effectiveness, efficiency, and structure rationality.