 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridSplat: Fast Reflection-baked Gaussian Tracing using Hybrid Splatting
Dec 15, 2025
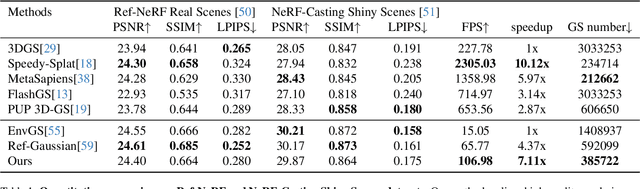


Rendering complex reflection of real-world scenes using 3D Gaussian splatting has been a quite promising solution for photorealistic novel view synthesis, but still faces bottlenecks especially in rendering speed and memory storage. This paper proposes a new Hybrid Splatting(HybridSplat) mechanism for Gaussian primitives. Our key idea is a new reflection-baked Gaussian tracing, which bakes the view-dependent reflection within each Gaussian primitive while rendering the reflection using tile-based Gaussian splatting. Then we integrate the reflective Gaussian primitives with base Gaussian primitives using a unified hybrid splatting framework for high-fidelity scene reconstruction. Moreover, we further introduce a pipeline-level acceleration for the hybrid splatting, and reflection-sensitive Gaussian pruning to reduce the model size, thus achieving much faster rendering speed and lower memory storage while preserving the reflection rendering quality. By extensive evaluation, our HybridSplat accelerates about 7x rendering speed across complex reflective scenes from Ref-NeRF, NeRF-Casting with 4x fewer Gaussian primitives than similar ray-tracing based Gaussian splatting baselines, serving as a new state-of-the-art method especially for complex reflective scenes.
Upgrade or Switch: Do We Need a New Registry Architecture for the Internet of AI Agents?
Jun 13, 2025The emerging Internet of AI Agents challenges existing web infrastructure designed for human-scale, reactive interactions. Unlike traditional web resources, autonomous AI agents initiate actions, maintain persistent state, spawn sub-agents, and negotiate directly with peers: demanding millisecond-level discovery, instant credential revocation, and cryptographic behavioral proofs that exceed current DNS/PKI capabilities. This paper analyzes whether to upgrade existing infrastructure or implement purpose-built registry architectures for autonomous agents. We identify critical failure points: DNS propagation (24-48 hours vs. required milliseconds), certificate revocation unable to scale to trillions of entities, and IPv4/IPv6 addressing inadequate for agent-scale routing. We evaluate three approaches: (1) Upgrade paths, (2) Switch options, (3) Hybrid registries. Drawing parallels to dialup-to-broadband transitions, we find that agent requirements constitute qualitative, and not incremental, changes. While upgrades offer compatibility and faster deployment, clean-slate solutions provide better performance but require longer for adoption. Our analysis suggests hybrid approaches will emerge, with centralized registries for critical agents and federated meshes for specialized use cases.
DenseFormer: Learning Dense Depth Map from Sparse Depth and Image via Conditional Diffusion Model
Mar 31, 2025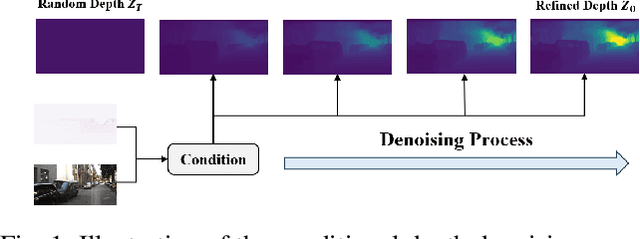
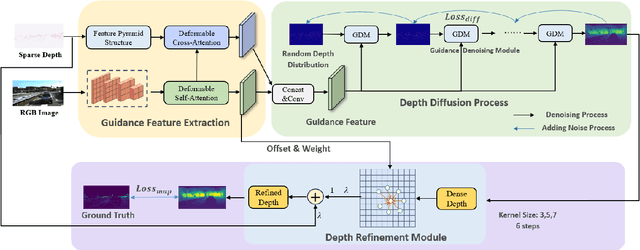
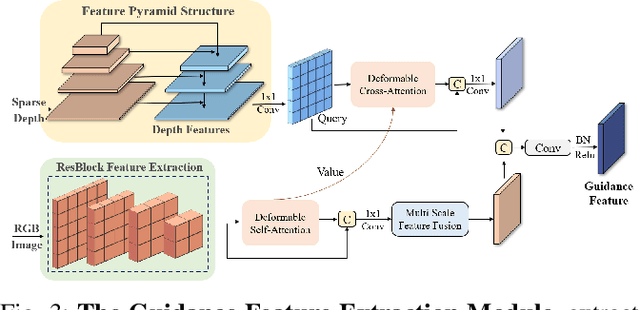
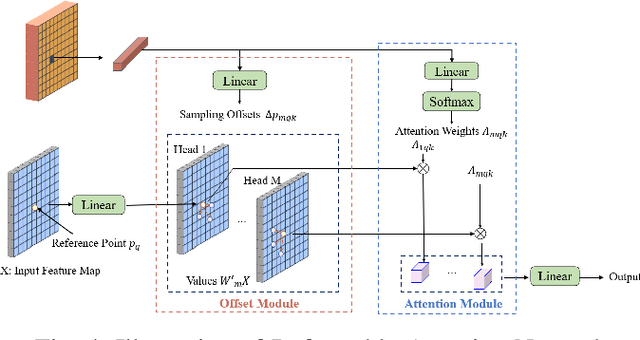
The depth completion task is a critical problem in autonomous driving, involving the generation of dense depth maps from sparse depth maps and RGB images. Most existing methods employ a spatial propagation network to iteratively refine the depth map after obtaining an initial dense depth. In this paper, we propose DenseFormer, a novel method that integrates the diffusion model into the depth completion task. By incorporating the denoising mechanism of the diffusion model, DenseFormer generates the dense depth map by progressively refining an initial random depth distribution through multiple iterations. We propose a feature extraction module that leverages a feature pyramid structure, along with multi-layer deformable attention, to effectively extract and integrate features from sparse depth maps and RGB images, which serve as the guiding condition for the diffusion process. Additionally, this paper presents a depth refinement module that applies multi-step iterative refinement across various ranges to the dense depth results generated by the diffusion process. The module utilizes image features enriched with multi-scale information and sparse depth input to further enhance the accuracy of the predicted depth map. Extensive experiments on the KITTI outdoor scene dataset demonstrate that DenseFormer outperforms classical depth completion methods.
V2X-DGPE: Addressing Domain Gaps and Pose Errors for Robust Collaborative 3D Object Detection
Jan 04, 2025



In V2X collaborative perception, the domain gaps between heterogeneous nodes pose a significant challenge for effective information fusion. Pose errors arising from latency and GPS localization noise further exacerbate the issue by leading to feature misalignment. To overcome these challenges, we propose V2X-DGPE, a high-accuracy and robust V2X feature-level collaborative perception framework. V2X-DGPE employs a Knowledge Distillation Framework and a Feature Compensation Module to learn domain-invariant representations from multi-source data, effectively reducing the feature distribution gap between vehicles and roadside infrastructure. Historical information is utilized to provide the model with a more comprehensive understanding of the current scene. Furthermore, a Collaborative Fusion Module leverages a heterogeneous self-attention mechanism to extract and integrate heterogeneous representations from vehicles and infrastructure. To address pose errors, V2X-DGPE introduces a deformable attention mechanism, enabling the model to adaptively focus on critical parts of the input features by dynamically offsetting sampling points. Extensive experiments on the real-world DAIR-V2X dataset demonstrate that the proposed method outperforms existing approaches, achieving state-of-the-art detection performance. The code is available at https://github.com/wangsch10/V2X-DGPE.