 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRMedSeg: Unlocking High-resolution Medical Image segmentation via Memory-efficient Attention Modeling
Paper and Code
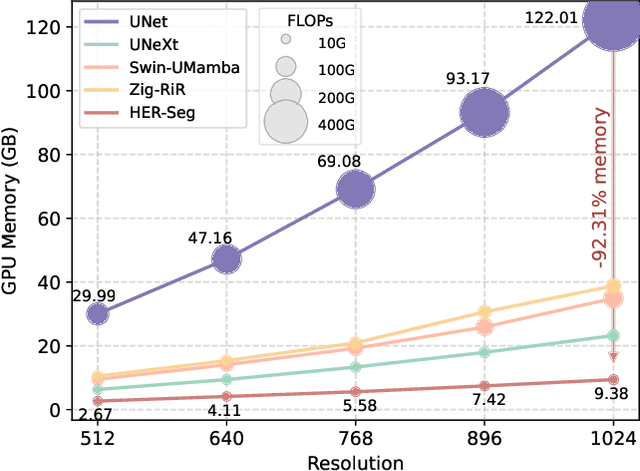
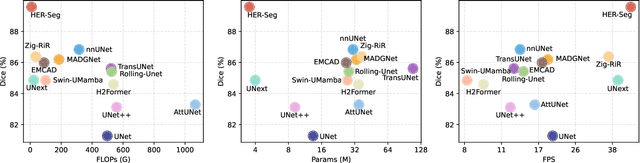
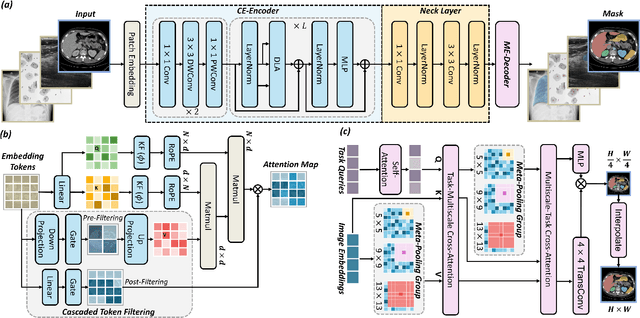
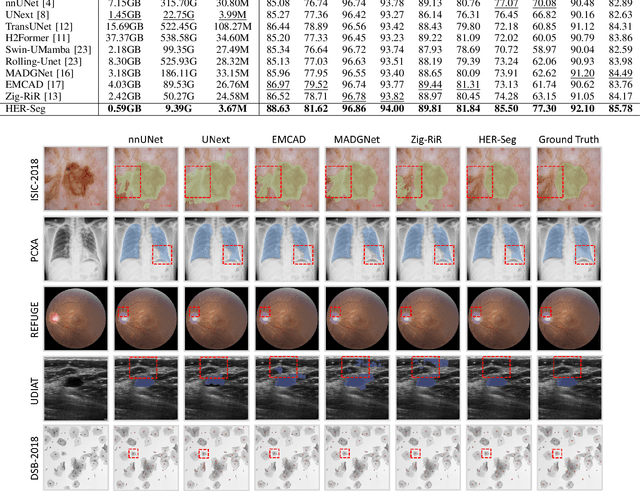
High-resolution segmentation is critical for precise disease diagnosis by extracting micro-imaging information from medical images. Existing transformer-based encoder-decoder frameworks have demonstrated remarkable versatility and zero-shot performance in medical segmentation. While beneficial, they usually require huge memory costs when handling large-size segmentation mask predictions, which are expensive to apply to real-world scenarios. To address this limitation, we propose a memory-efficient framework for high-resolution medical image segmentation, called HRMedSeg. Specifically, we first devise a lightweight gated vision transformer (LGViT) as our image encoder to model long-range dependencies with linear complexity. Then, we design an efficient cross-multiscale decoder (ECM-Decoder) to generate high-resolution segmentation masks. Moreover, we utilize feature distillation during pretraining to unleash the potential of our proposed model. Extensive experiments reveal that HRMedSeg outperforms state-of-the-arts in diverse high-resolution medical image segmentation tasks. In particular, HRMedSeg uses only 0.59GB GPU memory per batch during fine-tuning, demonstrating low training costs. Besides, when HRMedSeg meets the Segment Anything Model (SAM), our HRMedSegSAM takes 0.61% parameters of SAM-H. The code is available at https://github.com/xq141839/HRMedSeg.