 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactMotion: Generating Reactive Listener Motions from Speaker Utterance
Mar 16, 2026In this paper, we introduce a new task, Reactive Listener Motion Generation from Speaker Utterance, which aims to generate naturalistic listener body motions that appropriately respond to a speaker's utterance. However, modeling such nonverbal listener behaviors remains underexplored and challenging due to the inherently non-deterministic nature of human reactions. To facilitate this task, we present ReactMotionNet, a large-scale dataset that pairs speaker utterances with multiple candidate listener motions annotated with varying degrees of appropriateness. This dataset design explicitly captures the one-to-many nature of listener behavior and provides supervision beyond a single ground-truth motion. Building on this dataset design, we develop preference-oriented evaluation protocols tailored to evaluate reactive appropriateness, where conventional motion metrics focusing on input-motion alignment ignore. We further propose ReactMotion, a unified generative framework that jointly models text, audio, emotion, and motion, and is trained with preference-based objectives to encourage both appropriate and diverse listener responses. Extensive experiments show that ReactMotion outperforms retrieval baselines and cascaded LLM-based pipelines, generating more natural, diverse, and appropriate listener motions.
FreqDINO: Frequency-Guided Adaptation for Generalized Boundary-Aware Ultrasound Image Segmentation
Dec 12, 2025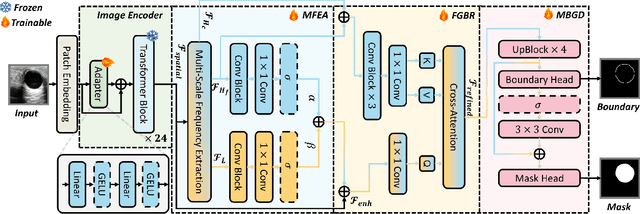
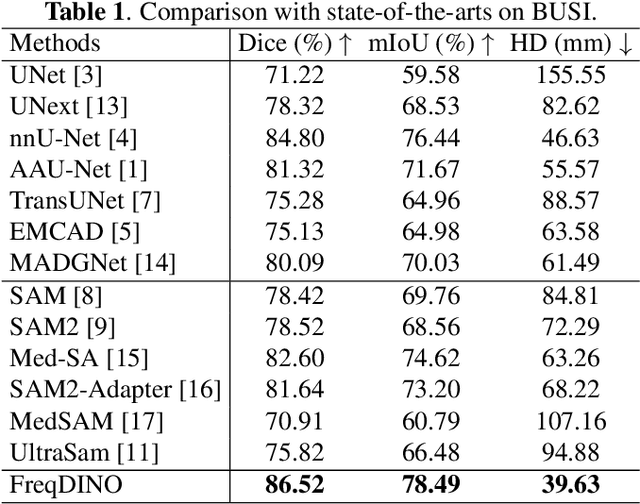
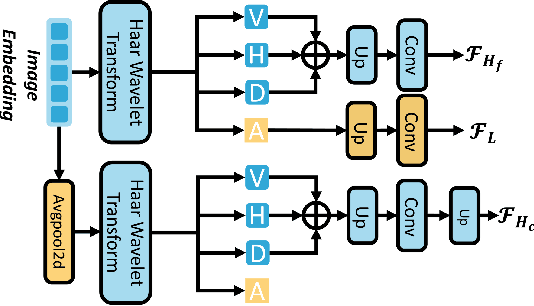
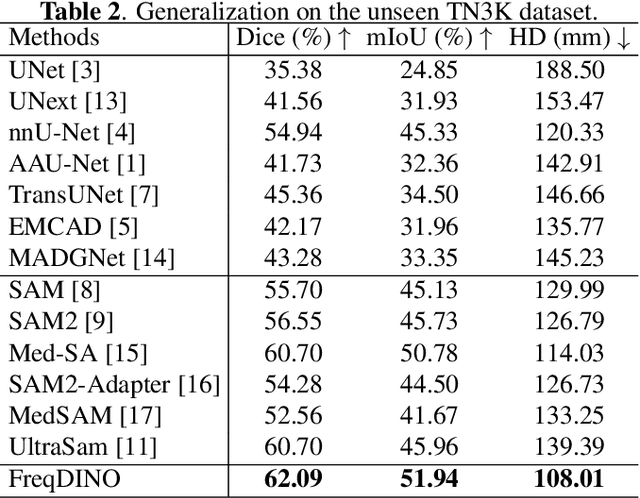
Ultrasound image segmentation is pivotal for clinical diagnosis, yet challenged by speckle noise and imaging artifacts. Recently, DINOv3 has shown remarkable promise in medical image segmentation with its powerful representation capabilities. However, DINOv3, pre-trained on natural images, lacks sensitivity to ultrasound-specific boundary degradation. To address this limitation, we propose FreqDINO, a frequency-guided segmentation framework that enhances boundary perception and structural consistency. Specifically, we devise a Multi-scale Frequency Extraction and Alignment (MFEA) strategy to separate low-frequency structures and multi-scale high-frequency boundary details, and align them via learnable attention. We also introduce a Frequency-Guided Boundary Refinement (FGBR) module that extracts boundary prototypes from high-frequency components and refines spatial features. Furthermore, we design a Multi-task Boundary-Guided Decoder (MBGD) to ensure spatial coherence between boundary and semantic predictions. Extensive experiments demonstrate that FreqDINO surpasses state-of-the-art methods with superior achieves remarkable generalization capability. The code is at https://github.com/MingLang-FD/FreqDINO.
CoMA: Complementary Masking and Hierarchical Dynamic Multi-Window Self-Attention in a Unified Pre-training Framework
Nov 08, 2025Masked Autoencoders (MAE) achieve self-supervised learning of image representations by randomly removing a portion of visual tokens and reconstructing the original image as a pretext task, thereby significantly enhancing pretraining efficiency and yielding excellent adaptability across downstream tasks. However, MAE and other MAE-style paradigms that adopt random masking generally require more pre-training epochs to maintain adaptability. Meanwhile, ViT in MAE suffers from inefficient parameter use due to fixed spatial resolution across layers. To overcome these limitations, we propose the Complementary Masked Autoencoders (CoMA), which employ a complementary masking strategy to ensure uniform sampling across all pixels, thereby improving effective learning of all features and enhancing the model's adaptability. Furthermore, we introduce DyViT, a hierarchical vision transformer that employs a Dynamic Multi-Window Self-Attention (DM-MSA), significantly reducing the parameters and FLOPs while improving fine-grained feature learning. Pre-trained on ImageNet-1K with CoMA, DyViT matches the downstream performance of MAE using only 12% of the pre-training epochs, demonstrating more effective learning. It also attains a 10% reduction in pre-training time per epoch, further underscoring its superior pre-training efficiency.
EyePCR: A Comprehensive Benchmark for Fine-Grained Perception, Knowledge Comprehension and Clinical Reasoning in Ophthalmic Surgery
Sep 19, 2025MLLMs (Multimodal Large Language Models) have showcased remarkable capabilities, but their performance in high-stakes, domain-specific scenarios like surgical settings, remains largely under-explored. To address this gap, we develop \textbf{EyePCR}, a large-scale benchmark for ophthalmic surgery analysis, grounded in structured clinical knowledge to evaluate cognition across \textit{Perception}, \textit{Comprehension} and \textit{Reasoning}. EyePCR offers a richly annotated corpus with more than 210k VQAs, which cover 1048 fine-grained attributes for multi-view perception, medical knowledge graph of more than 25k triplets for comprehension, and four clinically grounded reasoning tasks. The rich annotations facilitate in-depth cognitive analysis, simulating how surgeons perceive visual cues and combine them with domain knowledge to make decisions, thus greatly improving models' cognitive ability. In particular, \textbf{EyePCR-MLLM}, a domain-adapted variant of Qwen2.5-VL-7B, achieves the highest accuracy on MCQs for \textit{Perception} among compared models and outperforms open-source models in \textit{Comprehension} and \textit{Reasoning}, rivalling commercial models like GPT-4.1. EyePCR reveals the limitations of existing MLLMs in surgical cognition and lays the foundation for benchmarking and enhancing clinical reliability of surgical video understanding models.
PGU-SGP: A Pheno-Geno Unified Surrogate Genetic Programming For Real-life Container Terminal Truck Scheduling
Apr 15, 2025Data-driven genetic programming (GP) has proven highly effective in solving combinatorial optimization problems under dynamic and uncertain environments. A central challenge lies in fast fitness evaluations on large training datasets, especially for complex real-world problems involving time-consuming simulations. Surrogate models, like phenotypic characterization (PC)-based K-nearest neighbors (KNN), have been applied to reduce computational cost. However, the PC-based similarity measure is confined to behavioral characteristics, overlooking genotypic differences, which can limit surrogate quality and impair performance. To address these issues, this paper proposes a pheno-geno unified surrogate GP algorithm, PGU-SGP, integrating phenotypic and genotypic characterization (GC) to enhance surrogate sample selection and fitness prediction. A novel unified similarity metric combining PC and GC distances is proposed, along with an effective and efficient GC representation. Experimental results of a real-life vehicle scheduling problem demonstrate that PGU-SGP reduces training time by approximately 76% while achieving comparable performance to traditional GP. With the same training time, PGU-SGP significantly outperforms traditional GP and the state-of-the-art algorithm on most datasets. Additionally, PGU-SGP shows faster convergence and improved surrogate quality by maintaining accurate fitness rankings and appropriate selection pressure, further validating its effectiveness.
Genetic Programming with Reinforcement Learning Trained Transformer for Real-World Dynamic Scheduling Problems
Apr 10, 2025
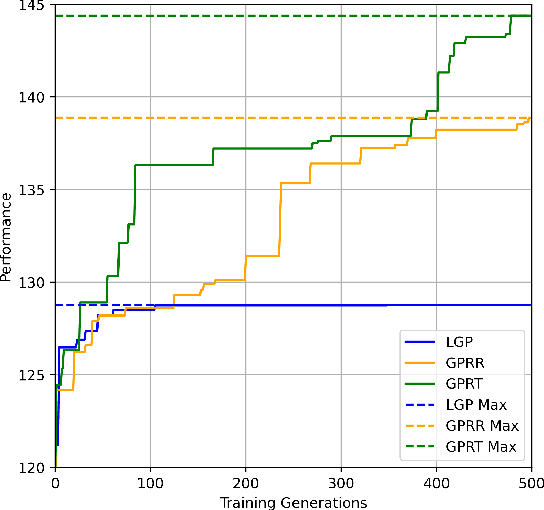


Dynamic scheduling in real-world environments often struggles to adapt to unforeseen disruptions, making traditional static scheduling methods and human-designed heuristics inadequate. This paper introduces an innovative approach that combines Genetic Programming (GP) with a Transformer trained through Reinforcement Learning (GPRT), specifically designed to tackle the complexities of dynamic scheduling scenarios. GPRT leverages the Transformer to refine heuristics generated by GP while also seeding and guiding the evolution of GP. This dual functionality enhances the adaptability and effectiveness of the scheduling heuristics, enabling them to better respond to the dynamic nature of real-world tasks. The efficacy of this integrated approach is demonstrated through a practical application in container terminal truck scheduling, where the GPRT method outperforms traditional GP, standalone Transformer methods, and other state-of-the-art competitors. The key contribution of this research is the development of the GPRT method, which showcases a novel combination of GP and Reinforcement Learning (RL) to produce robust and efficient scheduling solutions. Importantly, GPRT is not limited to container port truck scheduling; it offers a versatile framework applicable to various dynamic scheduling challenges. Its practicality, coupled with its interpretability and ease of modification, makes it a valuable tool for diverse real-world scenarios.
HRMedSeg: Unlocking High-resolution Medical Image segmentation via Memory-efficient Attention Modeling
Apr 08, 2025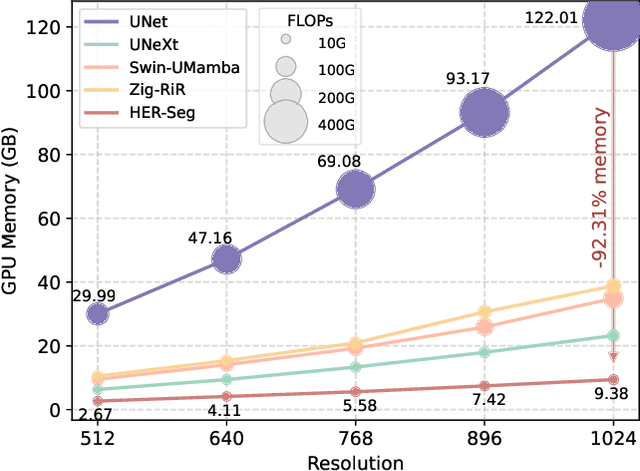
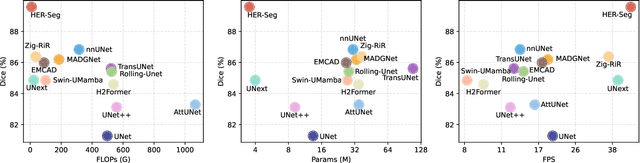
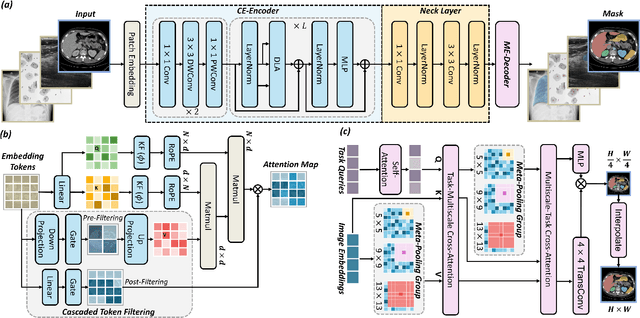
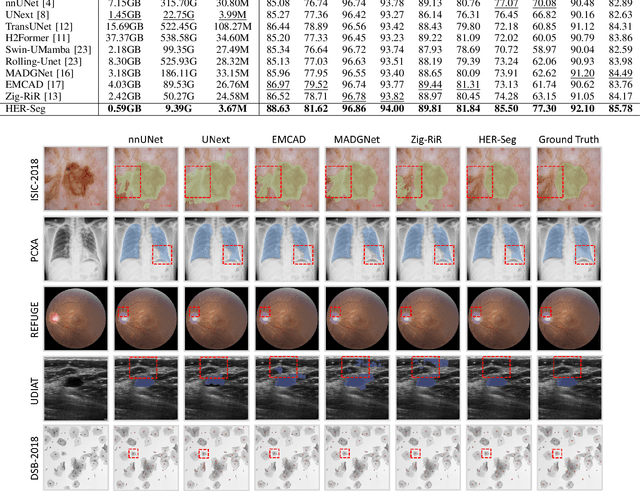
High-resolution segmentation is critical for precise disease diagnosis by extracting micro-imaging information from medical images. Existing transformer-based encoder-decoder frameworks have demonstrated remarkable versatility and zero-shot performance in medical segmentation. While beneficial, they usually require huge memory costs when handling large-size segmentation mask predictions, which are expensive to apply to real-world scenarios. To address this limitation, we propose a memory-efficient framework for high-resolution medical image segmentation, called HRMedSeg. Specifically, we first devise a lightweight gated vision transformer (LGViT) as our image encoder to model long-range dependencies with linear complexity. Then, we design an efficient cross-multiscale decoder (ECM-Decoder) to generate high-resolution segmentation masks. Moreover, we utilize feature distillation during pretraining to unleash the potential of our proposed model. Extensive experiments reveal that HRMedSeg outperforms state-of-the-arts in diverse high-resolution medical image segmentation tasks. In particular, HRMedSeg uses only 0.59GB GPU memory per batch during fine-tuning, demonstrating low training costs. Besides, when HRMedSeg meets the Segment Anything Model (SAM), our HRMedSegSAM takes 0.61% parameters of SAM-H. The code is available at https://github.com/xq141839/HRMedSeg.
MG-MotionLLM: A Unified Framework for Motion Comprehension and Generation across Multiple Granularities
Apr 03, 2025Recent motion-aware large language models have demonstrated promising potential in unifying motion comprehension and generation. However, existing approaches primarily focus on coarse-grained motion-text modeling, where text describes the overall semantics of an entire motion sequence in just a few words. This limits their ability to handle fine-grained motion-relevant tasks, such as understanding and controlling the movements of specific body parts. To overcome this limitation, we pioneer MG-MotionLLM, a unified motion-language model for multi-granular motion comprehension and generation. We further introduce a comprehensive multi-granularity training scheme by incorporating a set of novel auxiliary tasks, such as localizing temporal boundaries of motion segments via detailed text as well as motion detailed captioning, to facilitate mutual reinforcement for motion-text modeling across various levels of granularity. Extensive experiments show that our MG-MotionLLM achieves superior performance on classical text-to-motion and motion-to-text tasks, and exhibits potential in novel fine-grained motion comprehension and editing tasks. Project page: CVI-SZU/MG-MotionLLM
CFFormer: Cross CNN-Transformer Channel Attention and Spatial Feature Fusion for Improved Segmentation of Low Quality Medical Images
Jan 07, 2025Hybrid CNN-Transformer models are designed to combine the advantages of Convolutional Neural Networks (CNNs) and Transformers to efficiently model both local information and long-range dependencies. However, most research tends to focus on integrating the spatial features of CNNs and Transformers, while overlooking the critical importance of channel features. This is particularly significant for model performance in low-quality medical image segmentation. Effective channel feature extraction can significantly enhance the model's ability to capture contextual information and improve its representation capabilities. To address this issue, we propose a hybrid CNN-Transformer model, CFFormer, and introduce two modules: the Cross Feature Channel Attention (CFCA) module and the X-Spatial Feature Fusion (XFF) module. The model incorporates dual encoders, with the CNN encoder focusing on capturing local features and the Transformer encoder modeling global features. The CFCA module filters and facilitates interactions between the channel features from the two encoders, while the XFF module effectively reduces the significant semantic information differences in spatial features, enabling a smooth and cohesive spatial feature fusion. We evaluate our model across eight datasets covering five modalities to test its generalization capability. Experimental results demonstrate that our model outperforms current state-of-the-art (SOTA) methods, with particularly superior performance on datasets characterized by blurry boundaries and low contrast.
{S$^3$-Mamba}: Small-Size-Sensitive Mamba for Lesion Segmentation
Dec 19, 2024Small lesions play a critical role in early disease diagnosis and intervention of severe infections. Popular models often face challenges in segmenting small lesions, as it occupies only a minor portion of an image, while down\_sampling operations may inevitably lose focus on local features of small lesions. To tackle the challenges, we propose a {\bf S}mall-{\bf S}ize-{\bf S}ensitive {\bf Mamba} ({\bf S$^3$-Mamba}), which promotes the sensitivity to small lesions across three dimensions: channel, spatial, and training strategy. Specifically, an Enhanced Visual State Space block is designed to focus on small lesions through multiple residual connections to preserve local features, and selectively amplify important details while suppressing irrelevant ones through channel-wise attention. A Tensor-based Cross-feature Multi-scale Attention is designed to integrate input image features and intermediate-layer features with edge features and exploit the attentive support of features across multiple scales, thereby retaining spatial details of small lesions at various granularities. Finally, we introduce a novel regularized curriculum learning to automatically assess lesion size and sample difficulty, and gradually focus from easy samples to hard ones like small lesions. Extensive experiments on three medical image segmentation datasets show the superiority of our S$^3$-Mamba, especially in segmenting small lesions. Our code is available at https://github.com/ErinWang2023/S3-Mamba.