 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-ray Insights Unleashed: Pioneering the Enhancement of Multi-Label Long-Tail Data
Dec 24, 2025Long-tailed pulmonary anomalies in chest radiography present formidable diagnostic challenges. Despite the recent strides in diffusion-based methods for enhancing the representation of tailed lesions, the paucity of rare lesion exemplars curtails the generative capabilities of these approaches, thereby leaving the diagnostic precision less than optimal. In this paper, we propose a novel data synthesis pipeline designed to augment tail lesions utilizing a copious supply of conventional normal X-rays. Specifically, a sufficient quantity of normal samples is amassed to train a diffusion model capable of generating normal X-ray images. This pre-trained diffusion model is subsequently utilized to inpaint the head lesions present in the diseased X-rays, thereby preserving the tail classes as augmented training data. Additionally, we propose the integration of a Large Language Model Knowledge Guidance (LKG) module alongside a Progressive Incremental Learning (PIL) strategy to stabilize the inpainting fine-tuning process. Comprehensive evaluations conducted on the public lung datasets MIMIC and CheXpert demonstrate that the proposed method sets a new benchmark in performance.
A Hybrid Framework Bridging CNN and ViT based on Theory of Evidence for Diabetic Retinopathy Grading
Oct 30, 2025Diabetic retinopathy (DR) is a leading cause of vision loss among middle-aged and elderly people, which significantly impacts their daily lives and mental health. To improve the efficiency of clinical screening and enable the early detection of DR, a variety of automated DR diagnosis systems have been recently established based on convolutional neural network (CNN) or vision Transformer (ViT). However, due to the own shortages of CNN / ViT, the performance of existing methods using single-type backbone has reached a bottleneck. One potential way for the further improvements is integrating different kinds of backbones, which can fully leverage the respective strengths of them (\emph{i.e.,} the local feature extraction capability of CNN and the global feature capturing ability of ViT). To this end, we propose a novel paradigm to effectively fuse the features extracted by different backbones based on the theory of evidence. Specifically, the proposed evidential fusion paradigm transforms the features from different backbones into supporting evidences via a set of deep evidential networks. With the supporting evidences, the aggregated opinion can be accordingly formed, which can be used to adaptively tune the fusion pattern between different backbones and accordingly boost the performance of our hybrid model. We evaluated our method on two publicly available DR grading datasets. The experimental results demonstrate that our hybrid model not only improves the accuracy of DR grading, compared to the state-of-the-art frameworks, but also provides the excellent interpretability for feature fusion and decision-making.
DGFamba: Learning Flow Factorized State Space for Visual Domain Generalization
Apr 10, 2025Domain generalization aims to learn a representation from the source domain, which can be generalized to arbitrary unseen target domains. A fundamental challenge for visual domain generalization is the domain gap caused by the dramatic style variation whereas the image content is stable. The realm of selective state space, exemplified by VMamba, demonstrates its global receptive field in representing the content. However, the way exploiting the domain-invariant property for selective state space is rarely explored. In this paper, we propose a novel Flow Factorized State Space model, dubbed as DG-Famba, for visual domain generalization. To maintain domain consistency, we innovatively map the style-augmented and the original state embeddings by flow factorization. In this latent flow space, each state embedding from a certain style is specified by a latent probability path. By aligning these probability paths in the latent space, the state embeddings are able to represent the same content distribution regardless of the style differences. Extensive experiments conducted on various visual domain generalization settings show its state-of-the-art performance.
{S$^3$-Mamba}: Small-Size-Sensitive Mamba for Lesion Segmentation
Dec 19, 2024Small lesions play a critical role in early disease diagnosis and intervention of severe infections. Popular models often face challenges in segmenting small lesions, as it occupies only a minor portion of an image, while down\_sampling operations may inevitably lose focus on local features of small lesions. To tackle the challenges, we propose a {\bf S}mall-{\bf S}ize-{\bf S}ensitive {\bf Mamba} ({\bf S$^3$-Mamba}), which promotes the sensitivity to small lesions across three dimensions: channel, spatial, and training strategy. Specifically, an Enhanced Visual State Space block is designed to focus on small lesions through multiple residual connections to preserve local features, and selectively amplify important details while suppressing irrelevant ones through channel-wise attention. A Tensor-based Cross-feature Multi-scale Attention is designed to integrate input image features and intermediate-layer features with edge features and exploit the attentive support of features across multiple scales, thereby retaining spatial details of small lesions at various granularities. Finally, we introduce a novel regularized curriculum learning to automatically assess lesion size and sample difficulty, and gradually focus from easy samples to hard ones like small lesions. Extensive experiments on three medical image segmentation datasets show the superiority of our S$^3$-Mamba, especially in segmenting small lesions. Our code is available at https://github.com/ErinWang2023/S3-Mamba.
Learning Spectral-Decomposed Tokens for Domain Generalized Semantic Segmentation
Jul 29, 2024



The rapid development of Vision Foundation Model (VFM) brings inherent out-domain generalization for a variety of down-stream tasks. Among them, domain generalized semantic segmentation (DGSS) holds unique challenges as the cross-domain images share common pixel-wise content information but vary greatly in terms of the style. In this paper, we present a novel Spectral-dEcomposed Token (SET) learning framework to advance the frontier. Delving into further than existing fine-tuning token & frozen backbone paradigm, the proposed SET especially focuses on the way learning style-invariant features from these learnable tokens. Particularly, the frozen VFM features are first decomposed into the phase and amplitude components in the frequency space, which mainly contain the information of content and style, respectively, and then separately processed by learnable tokens for task-specific information extraction. After the decomposition, style variation primarily impacts the token-based feature enhancement within the amplitude branch. To address this issue, we further develop an attention optimization method to bridge the gap between style-affected representation and static tokens during inference. Extensive cross-domain experiments show its state-of-the-art performance.
Dual Teacher Knowledge Distillation with Domain Alignment for Face Anti-spoofing
Jan 02, 2024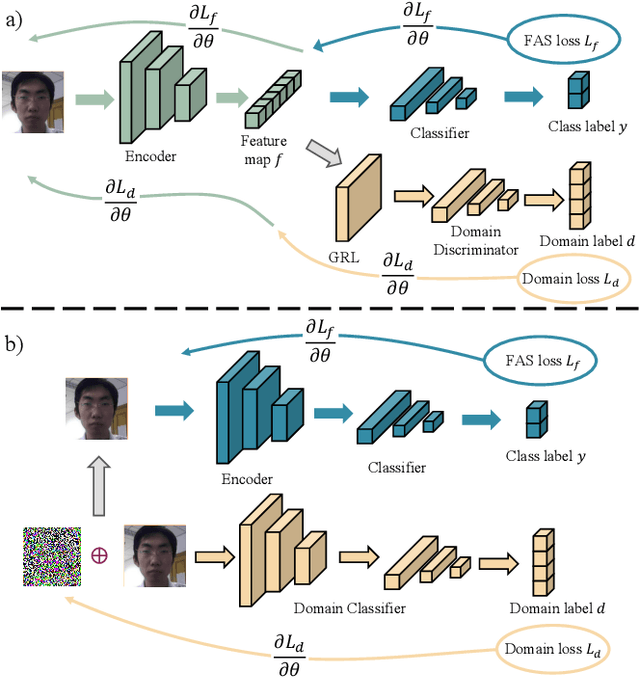
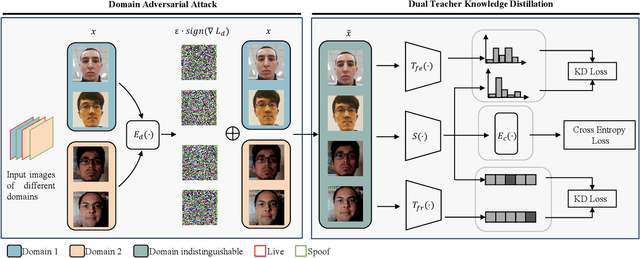
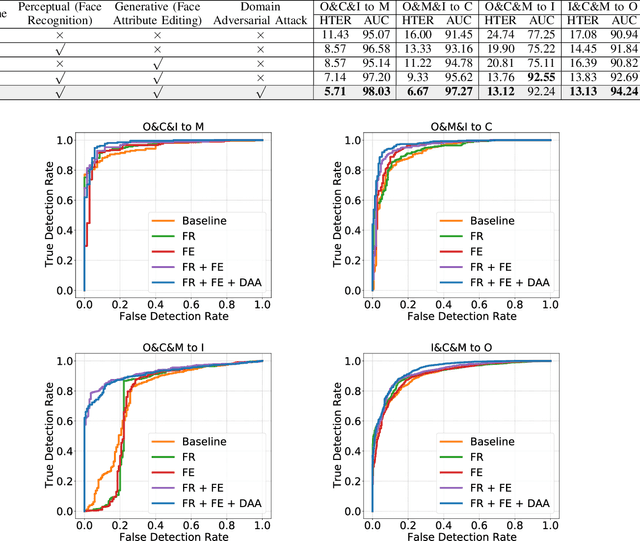
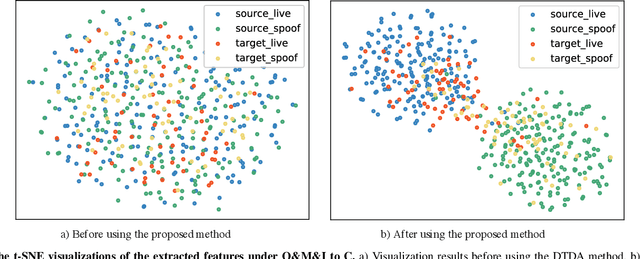
Face recognition systems have raised concerns due to their vulnerability to different presentation attacks, and system security has become an increasingly critical concern. Although many face anti-spoofing (FAS) methods perform well in intra-dataset scenarios, their generalization remains a challenge. To address this issue, some methods adopt domain adversarial training (DAT) to extract domain-invariant features. However, the competition between the encoder and the domain discriminator can cause the network to be difficult to train and converge. In this paper, we propose a domain adversarial attack (DAA) method to mitigate the training instability problem by adding perturbations to the input images, which makes them indistinguishable across domains and enables domain alignment. Moreover, since models trained on limited data and types of attacks cannot generalize well to unknown attacks, we propose a dual perceptual and generative knowledge distillation framework for face anti-spoofing that utilizes pre-trained face-related models containing rich face priors. Specifically, we adopt two different face-related models as teachers to transfer knowledge to the target student model. The pre-trained teacher models are not from the task of face anti-spoofing but from perceptual and generative tasks, respectively, which implicitly augment the data. By combining both DAA and dual-teacher knowledge distillation, we develop a dual teacher knowledge distillation with domain alignment framework (DTDA) for face anti-spoofing. The advantage of our proposed method has been verified through extensive ablation studies and comparison with state-of-the-art methods on public datasets across multiple protocols.
Adversarial Medical Image with Hierarchical Feature Hiding
Dec 04, 2023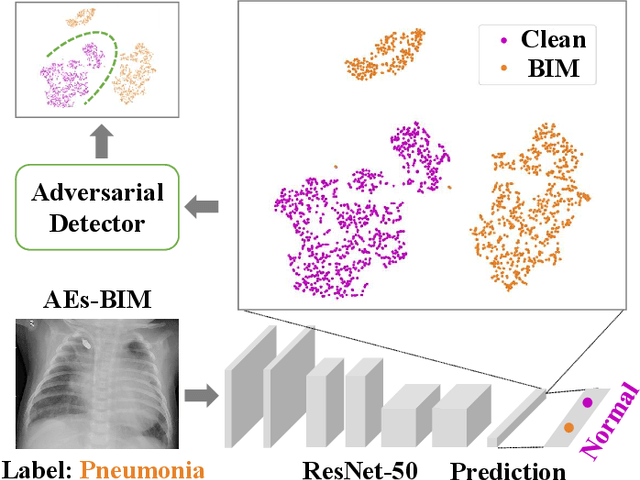
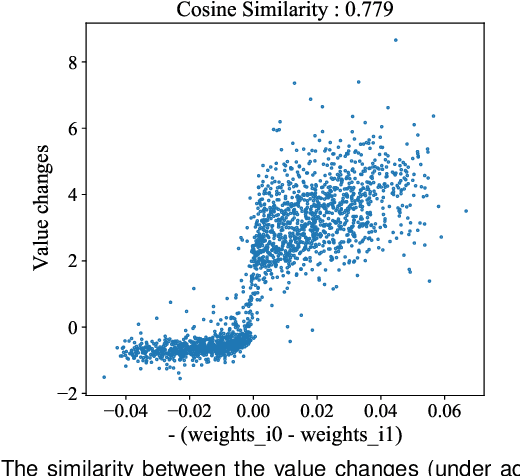
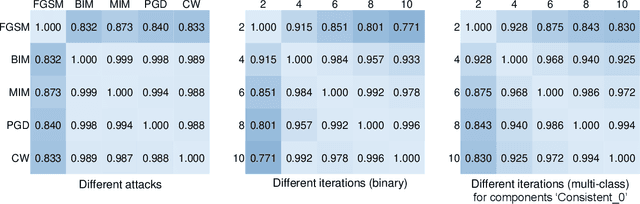
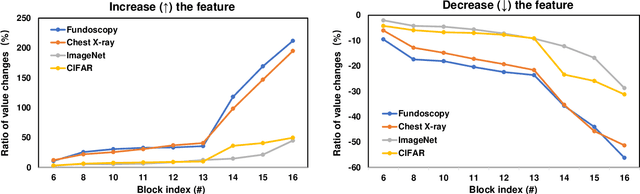
Deep learning based methods for medical images can be easily compromised by adversarial examples (AEs), posing a great security flaw in clinical decision-making. It has been discovered that conventional adversarial attacks like PGD which optimize the classification logits, are easy to distinguish in the feature space, resulting in accurate reactive defenses. To better understand this phenomenon and reassess the reliability of the reactive defenses for medical AEs, we thoroughly investigate the characteristic of conventional medical AEs. Specifically, we first theoretically prove that conventional adversarial attacks change the outputs by continuously optimizing vulnerable features in a fixed direction, thereby leading to outlier representations in the feature space. Then, a stress test is conducted to reveal the vulnerability of medical images, by comparing with natural images. Interestingly, this vulnerability is a double-edged sword, which can be exploited to hide AEs. We then propose a simple-yet-effective hierarchical feature constraint (HFC), a novel add-on to conventional white-box attacks, which assists to hide the adversarial feature in the target feature distribution. The proposed method is evaluated on three medical datasets, both 2D and 3D, with different modalities. The experimental results demonstrate the superiority of HFC, \emph{i.e.,} it bypasses an array of state-of-the-art adversarial medical AE detectors more efficiently than competing adaptive attacks, which reveals the deficiencies of medical reactive defense and allows to develop more robust defenses in future.
Automatic view plane prescription for cardiac magnetic resonance imaging via supervision by spatial relationship between views
Sep 22, 2023



Background: View planning for the acquisition of cardiac magnetic resonance (CMR) imaging remains a demanding task in clinical practice. Purpose: Existing approaches to its automation relied either on an additional volumetric image not typically acquired in clinic routine, or on laborious manual annotations of cardiac structural landmarks. This work presents a clinic-compatible, annotation-free system for automatic CMR view planning. Methods: The system mines the spatial relationship, more specifically, locates the intersecting lines, between the target planes and source views, and trains deep networks to regress heatmaps defined by distances from the intersecting lines. The intersection lines are the prescription lines prescribed by the technologists at the time of image acquisition using cardiac landmarks, and retrospectively identified from the spatial relationship. As the spatial relationship is self-contained in properly stored data, the need for additional manual annotation is eliminated. In addition, the interplay of multiple target planes predicted in a source view is utilized in a stacked hourglass architecture to gradually improve the regression. Then, a multi-view planning strategy is proposed to aggregate information from the predicted heatmaps for all the source views of a target plane, for a globally optimal prescription, mimicking the similar strategy practiced by skilled human prescribers. Results: The experiments include 181 CMR exams. Our system yields the mean angular difference and point-to-plane distance of 5.68 degrees and 3.12 mm, respectively. It not only achieves superior accuracy to existing approaches including conventional atlas-based and newer deep-learning-based in prescribing the four standard CMR planes but also demonstrates prescription of the first cardiac-anatomy-oriented plane(s) from the body-oriented scout.
Federated Pseudo Modality Generation for Incomplete Multi-Modal MRI Reconstruction
Aug 20, 2023While multi-modal learning has been widely used for MRI reconstruction, it relies on paired multi-modal data which is difficult to acquire in real clinical scenarios. Especially in the federated setting, the common situation is that several medical institutions only have single-modal data, termed the modality missing issue. Therefore, it is infeasible to deploy a standard federated learning framework in such conditions. In this paper, we propose a novel communication-efficient federated learning framework, namely Fed-PMG, to address the missing modality challenge in federated multi-modal MRI reconstruction. Specifically, we utilize a pseudo modality generation mechanism to recover the missing modality for each single-modal client by sharing the distribution information of the amplitude spectrum in frequency space. However, the step of sharing the original amplitude spectrum leads to heavy communication costs. To reduce the communication cost, we introduce a clustering scheme to project the set of amplitude spectrum into finite cluster centroids, and share them among the clients. With such an elaborate design, our approach can effectively complete the missing modality within an acceptable communication cost. Extensive experiments demonstrate that our proposed method can attain similar performance with the ideal scenario, i.e., all clients have the full set of modalities. The source code will be released.
BoxDiff: Text-to-Image Synthesis with Training-Free Box-Constrained Diffusion
Aug 10, 2023



Recent text-to-image diffusion models have demonstrated an astonishing capacity to generate high-quality images. However, researchers mainly studied the way of synthesizing images with only text prompts. While some works have explored using other modalities as conditions, considerable paired data, e.g., box/mask-image pairs, and fine-tuning time are required for nurturing models. As such paired data is time-consuming and labor-intensive to acquire and restricted to a closed set, this potentially becomes the bottleneck for applications in an open world. This paper focuses on the simplest form of user-provided conditions, e.g., box or scribble. To mitigate the aforementioned problem, we propose a training-free method to control objects and contexts in the synthesized images adhering to the given spatial conditions. Specifically, three spatial constraints, i.e., Inner-Box, Outer-Box, and Corner Constraints, are designed and seamlessly integrated into the denoising step of diffusion models, requiring no additional training and massive annotated layout data. Extensive results show that the proposed constraints can control what and where to present in the images while retaining the ability of the Stable Diffusion model to synthesize with high fidelity and diverse concept coverage. The code is publicly available at https://github.com/Sierkinhane/BoxDiff.