 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Sliced-Wasserstein Framework on Correlation Matrices for EEG Decoding
Jun 04, 2026Electroencephalography (EEG) offers noninvasive, millisecond resolution recordings of neuronal activity and is widely used in neuroscience and healthcare. Many EEG decoding pipelines rely on covariance descriptors for their robustness to noise, but such representations are sensitive to channel-wise scaling. Recent studies have therefore advocated full-rank correlation matrices as a scale-invariant alternative for EEG decoding. In this paper, we propose a general framework for Sliced Wasserstein (SW) discrepancies on manifolds endowed with Pullback Euclidean Metrics (PEMs), termed Pullback Euclidean Metric Sliced Wasserstein (PEMSW). Within this framework, we instantiate two Correlation Sliced-Wasserstein (CorSW) discrepancies on the manifold of full-rank correlation matrices under two recently introduced correlation geometries, \textit{i.e.}, the Off-Log Metric (OLM) and Log-Scaled Metric (LSM). Building on CorSW, we further develop a domain generalization (DG) framework for EEG decoding. Experiments on three EEG datasets demonstrate improved generalization under distribution shifts, with low training overhead and no additional inference cost. The source code is available at https://github.com/ChenHu-ML/CorSW.
Learning Fine-grained Domain Generalization via Hyperbolic State Space Hallucination
Apr 10, 2025



Fine-grained domain generalization (FGDG) aims to learn a fine-grained representation that can be well generalized to unseen target domains when only trained on the source domain data. Compared with generic domain generalization, FGDG is particularly challenging in that the fine-grained category can be only discerned by some subtle and tiny patterns. Such patterns are particularly fragile under the cross-domain style shifts caused by illumination, color and etc. To push this frontier, this paper presents a novel Hyperbolic State Space Hallucination (HSSH) method. It consists of two key components, namely, state space hallucination (SSH) and hyperbolic manifold consistency (HMC). SSH enriches the style diversity for the state embeddings by firstly extrapolating and then hallucinating the source images. Then, the pre- and post- style hallucinate state embeddings are projected into the hyperbolic manifold. The hyperbolic state space models the high-order statistics, and allows a better discernment of the fine-grained patterns. Finally, the hyperbolic distance is minimized, so that the impact of style variation on fine-grained patterns can be eliminated. Experiments on three FGDG benchmarks demonstrate its state-of-the-art performance.
DGFamba: Learning Flow Factorized State Space for Visual Domain Generalization
Apr 10, 2025Domain generalization aims to learn a representation from the source domain, which can be generalized to arbitrary unseen target domains. A fundamental challenge for visual domain generalization is the domain gap caused by the dramatic style variation whereas the image content is stable. The realm of selective state space, exemplified by VMamba, demonstrates its global receptive field in representing the content. However, the way exploiting the domain-invariant property for selective state space is rarely explored. In this paper, we propose a novel Flow Factorized State Space model, dubbed as DG-Famba, for visual domain generalization. To maintain domain consistency, we innovatively map the style-augmented and the original state embeddings by flow factorization. In this latent flow space, each state embedding from a certain style is specified by a latent probability path. By aligning these probability paths in the latent space, the state embeddings are able to represent the same content distribution regardless of the style differences. Extensive experiments conducted on various visual domain generalization settings show its state-of-the-art performance.
Learning Spectral-Decomposed Tokens for Domain Generalized Semantic Segmentation
Jul 29, 2024



The rapid development of Vision Foundation Model (VFM) brings inherent out-domain generalization for a variety of down-stream tasks. Among them, domain generalized semantic segmentation (DGSS) holds unique challenges as the cross-domain images share common pixel-wise content information but vary greatly in terms of the style. In this paper, we present a novel Spectral-dEcomposed Token (SET) learning framework to advance the frontier. Delving into further than existing fine-tuning token & frozen backbone paradigm, the proposed SET especially focuses on the way learning style-invariant features from these learnable tokens. Particularly, the frozen VFM features are first decomposed into the phase and amplitude components in the frequency space, which mainly contain the information of content and style, respectively, and then separately processed by learnable tokens for task-specific information extraction. After the decomposition, style variation primarily impacts the token-based feature enhancement within the amplitude branch. To address this issue, we further develop an attention optimization method to bridge the gap between style-affected representation and static tokens during inference. Extensive cross-domain experiments show its state-of-the-art performance.
GOOD: Towards Domain Generalized Orientated Object Detection
Feb 20, 2024
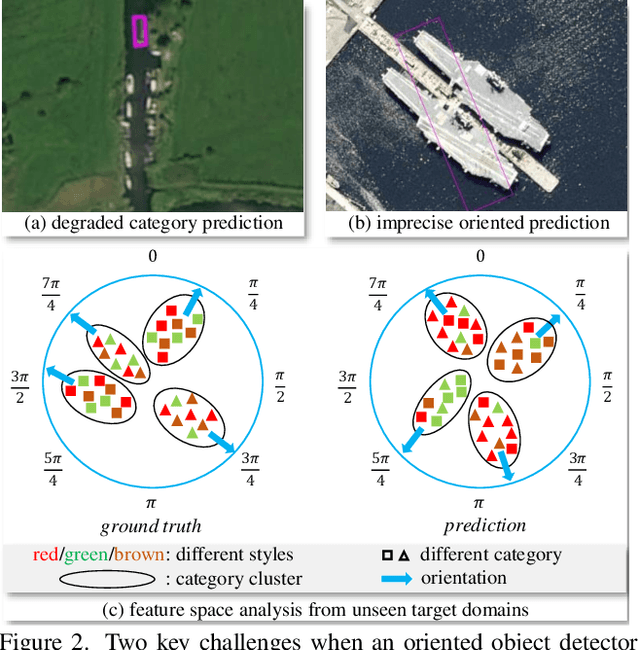
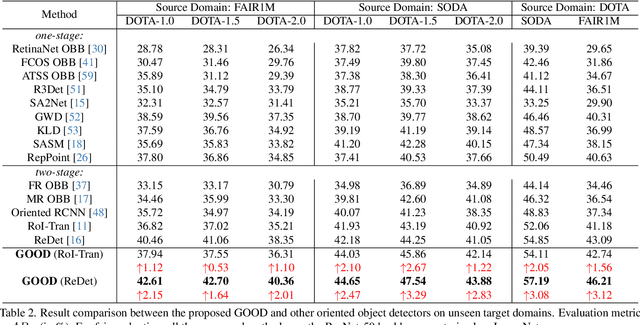
Oriented object detection has been rapidly developed in the past few years, but most of these methods assume the training and testing images are under the same statistical distribution, which is far from reality. In this paper, we propose the task of domain generalized oriented object detection, which intends to explore the generalization of oriented object detectors on arbitrary unseen target domains. Learning domain generalized oriented object detectors is particularly challenging, as the cross-domain style variation not only negatively impacts the content representation, but also leads to unreliable orientation predictions. To address these challenges, we propose a generalized oriented object detector (GOOD). After style hallucination by the emerging contrastive language-image pre-training (CLIP), it consists of two key components, namely, rotation-aware content consistency learning (RAC) and style consistency learning (SEC). The proposed RAC allows the oriented object detector to learn stable orientation representation from style-diversified samples. The proposed SEC further stabilizes the generalization ability of content representation from different image styles. Extensive experiments on multiple cross-domain settings show the state-of-the-art performance of GOOD. Source code will be publicly available.
Cross-Level Multi-Instance Distillation for Self-Supervised Fine-Grained Visual Categorization
Jan 16, 2024



High-quality annotation of fine-grained visual categories demands great expert knowledge, which is taxing and time consuming. Alternatively, learning fine-grained visual representation from enormous unlabeled images (e.g., species, brands) by self-supervised learning becomes a feasible solution. However, recent researches find that existing self-supervised learning methods are less qualified to represent fine-grained categories. The bottleneck lies in that the pre-text representation is built from every patch-wise embedding, while fine-grained categories are only determined by several key patches of an image. In this paper, we propose a Cross-level Multi-instance Distillation (CMD) framework to tackle the challenge. Our key idea is to consider the importance of each image patch in determining the fine-grained pre-text representation by multiple instance learning. To comprehensively learn the relation between informative patches and fine-grained semantics, the multi-instance knowledge distillation is implemented on both the region/image crop pairs from the teacher and student net, and the region-image crops inside the teacher / student net, which we term as intra-level multi-instance distillation and inter-level multi-instance distillation. Extensive experiments on CUB-200-2011, Stanford Cars and FGVC Aircraft show that the proposed method outperforms the contemporary method by upto 10.14% and existing state-of-the-art self-supervised learning approaches by upto 19.78% on both top-1 accuracy and Rank-1 retrieval metric.
Attention Awareness Multiple Instance Neural Network
May 27, 2022Multiple instance learning is qualified for many pattern recognition tasks with weakly annotated data. The combination of artificial neural network and multiple instance learning offers an end-to-end solution and has been widely utilized. However, challenges remain in two-folds. Firstly, current MIL pooling operators are usually pre-defined and lack flexibility to mine key instances. Secondly, in current solutions, the bag-level representation can be inaccurate or inaccessible. To this end, we propose an attention awareness multiple instance neural network framework in this paper. It consists of an instance-level classifier, a trainable MIL pooling operator based on spatial attention and a bag-level classification layer. Exhaustive experiments on a series of pattern recognition tasks demonstrate that our framework outperforms many state-of-the-art MIL methods and validates the effectiveness of our proposed attention MIL pooling operators.
Learning Instance Representation Banks for Aerial Scene Classification
May 27, 2022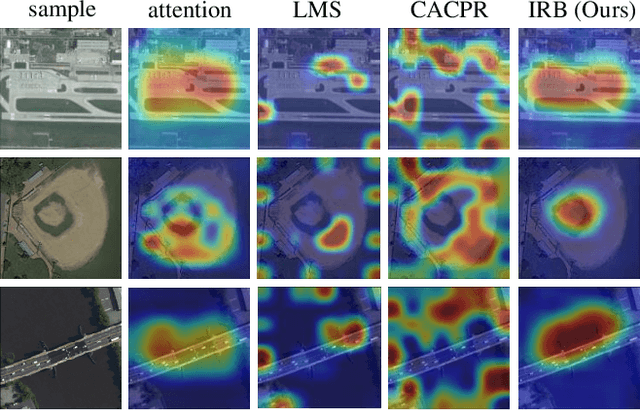
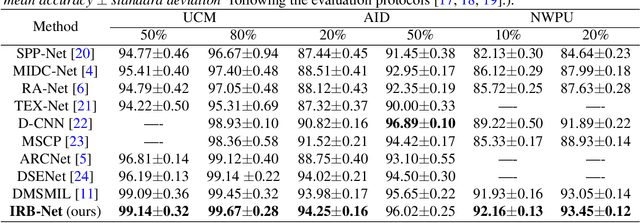

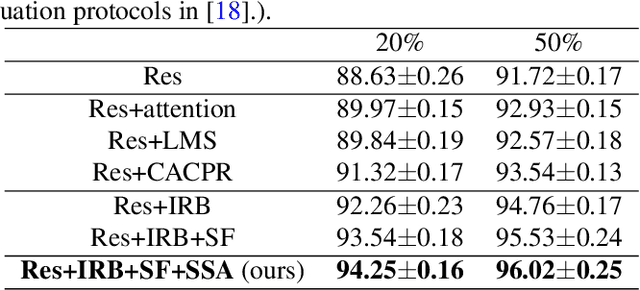
Aerial scenes are more complicated in terms of object distribution and spatial arrangement than natural scenes due to the bird view, and thus remain challenging to learn discriminative scene representation. Recent solutions design \textit{local semantic descriptors} so that region of interests (RoIs) can be properly highlighted. However, each local descriptor has limited description capability and the overall scene representation remains to be refined. In this paper, we solve this problem by designing a novel representation set named \textit{instance representation bank} (IRB), which unifies multiple local descriptors under the multiple instance learning (MIL) formulation. This unified framework is not trivial as all the local semantic descriptors can be aligned to the same scene scheme, enhancing the scene representation capability. Specifically, our IRB learning framework consists of a backbone, an instance representation bank, a semantic fusion module and a scene scheme alignment loss function. All the components are organized in an end-to-end manner. Extensive experiments on three aerial scene benchmarks demonstrate that our proposed method outperforms the state-of-the-art approaches by a large margin.
A Multi-Stage Duplex Fusion ConvNet for Aerial Scene Classification
Mar 29, 2022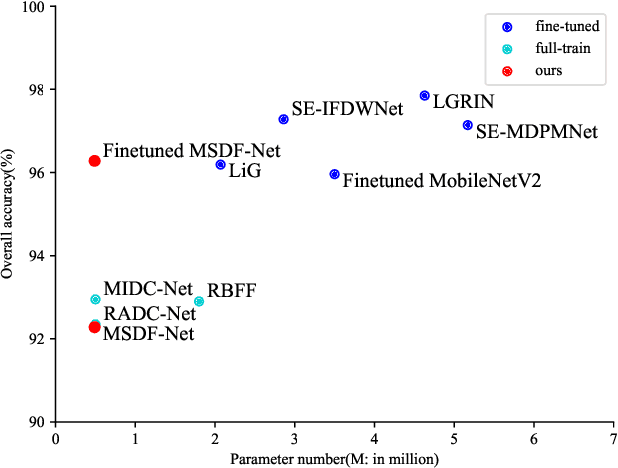

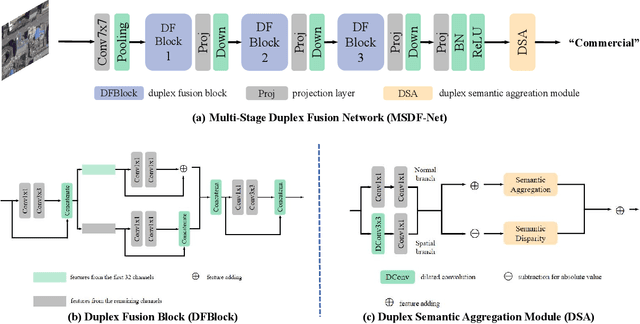

Existing deep learning based methods effectively prompt the performance of aerial scene classification. However, due to the large amount of parameters and computational cost, it is rather difficult to apply these methods to multiple real-time remote sensing applications such as on-board data preception on drones and satellites. In this paper, we address this task by developing a light-weight ConvNet named multi-stage duplex fusion network (MSDF-Net). The key idea is to use parameters as little as possible while obtaining as strong as possible scene representation capability. To this end, a residual-dense duplex fusion strategy is developed to enhance the feature propagation while re-using parameters as much as possible, and is realized by our duplex fusion block (DFblock). Specifically, our MSDF-Net consists of multi-stage structures with DFblock. Moreover, duplex semantic aggregation (DSA) module is developed to mine the remote sensing scene information from extracted convolutional features, which also contains two parallel branches for semantic description. Extensive experiments are conducted on three widely-used aerial scene classification benchmarks, and reflect that our MSDF-Net can achieve a competitive performance against the recent state-of-art while reducing up to 80% parameter numbers. Particularly, an accuracy of 92.96% is achieved on AID with only 0.49M parameters.