 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimum-Violation Temporal Logic Planning for Heterogeneous Robots under Robot Skill Failures
Oct 22, 2024In this paper, we consider teams of robots with heterogeneous skills (e.g., sensing and manipulation) tasked with collaborative missions described by Linear Temporal Logic (LTL) formulas. These LTL-encoded tasks require robots to apply their skills to specific regions and objects in a temporal and logical order. While existing temporal logic planning algorithms can synthesize correct-by-construction paths, they typically lack reactivity to unexpected failures of robot skills, which can compromise mission performance. This paper addresses this challenge by proposing a reactive LTL planning algorithm that adapts to unexpected failures during deployment. Specifically, the proposed algorithm reassigns sub-tasks to robots based on their functioning skills and locally revises team plans to accommodate these new assignments and ensure mission completion. The main novelty of the proposed algorithm is its ability to handle cases where mission completion becomes impossible due to limited functioning robots. Instead of reporting mission failure, the algorithm strategically prioritizes the most crucial sub-tasks and locally revises the team's plans, as per user-specified priorities, to minimize mission violations. We provide theoretical conditions under which the proposed framework computes the minimum violation task reassignments and team plans. We provide numerical and hardware experiments to demonstrate the efficiency of the proposed method.
GOOD: Towards Domain Generalized Orientated Object Detection
Feb 20, 2024
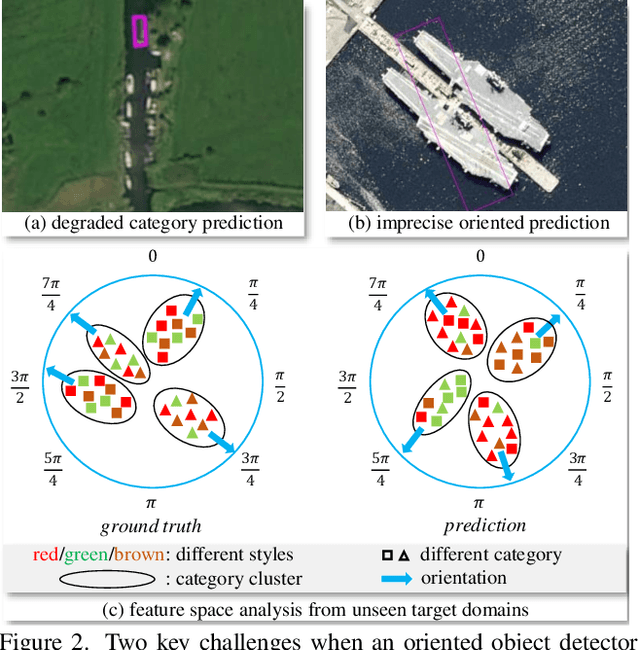
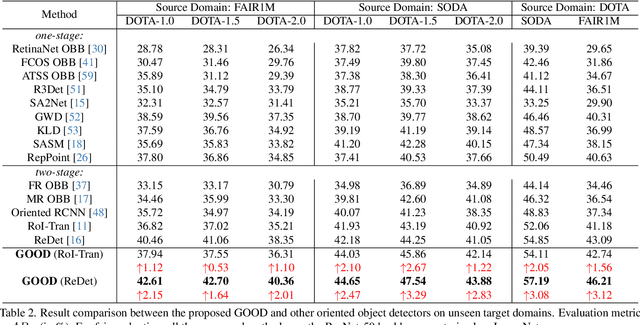
Oriented object detection has been rapidly developed in the past few years, but most of these methods assume the training and testing images are under the same statistical distribution, which is far from reality. In this paper, we propose the task of domain generalized oriented object detection, which intends to explore the generalization of oriented object detectors on arbitrary unseen target domains. Learning domain generalized oriented object detectors is particularly challenging, as the cross-domain style variation not only negatively impacts the content representation, but also leads to unreliable orientation predictions. To address these challenges, we propose a generalized oriented object detector (GOOD). After style hallucination by the emerging contrastive language-image pre-training (CLIP), it consists of two key components, namely, rotation-aware content consistency learning (RAC) and style consistency learning (SEC). The proposed RAC allows the oriented object detector to learn stable orientation representation from style-diversified samples. The proposed SEC further stabilizes the generalization ability of content representation from different image styles. Extensive experiments on multiple cross-domain settings show the state-of-the-art performance of GOOD. Source code will be publicly available.
Attention Awareness Multiple Instance Neural Network
May 27, 2022Multiple instance learning is qualified for many pattern recognition tasks with weakly annotated data. The combination of artificial neural network and multiple instance learning offers an end-to-end solution and has been widely utilized. However, challenges remain in two-folds. Firstly, current MIL pooling operators are usually pre-defined and lack flexibility to mine key instances. Secondly, in current solutions, the bag-level representation can be inaccurate or inaccessible. To this end, we propose an attention awareness multiple instance neural network framework in this paper. It consists of an instance-level classifier, a trainable MIL pooling operator based on spatial attention and a bag-level classification layer. Exhaustive experiments on a series of pattern recognition tasks demonstrate that our framework outperforms many state-of-the-art MIL methods and validates the effectiveness of our proposed attention MIL pooling operators.
Learning Instance Representation Banks for Aerial Scene Classification
May 27, 2022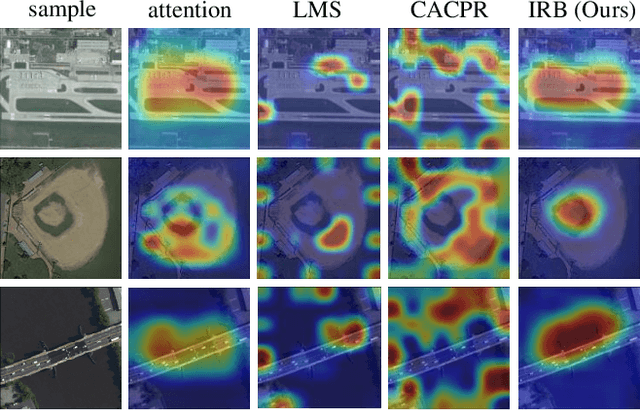
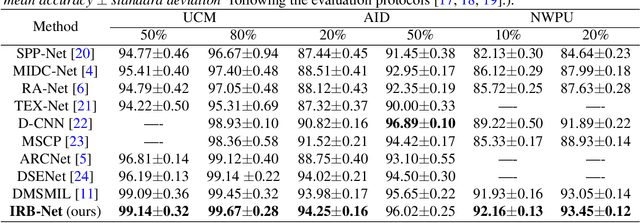

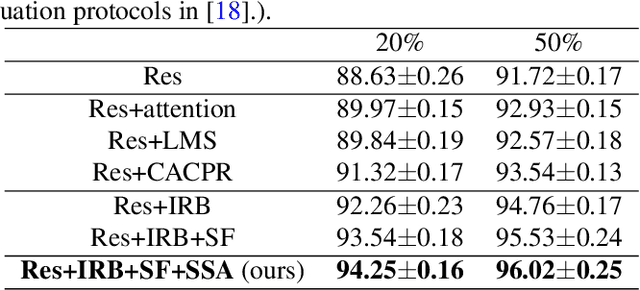
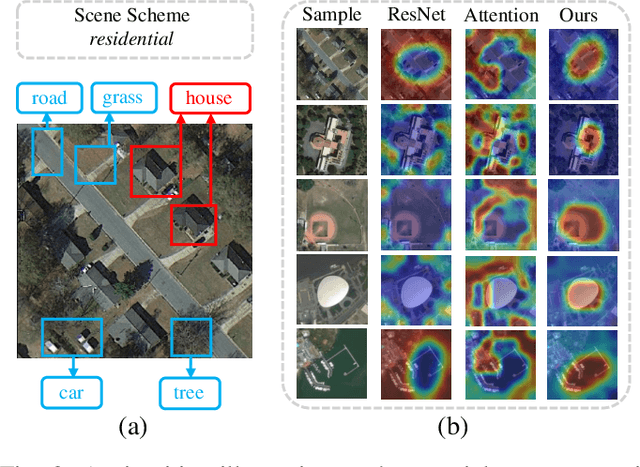
Aerial scenes are more complicated in terms of object distribution and spatial arrangement than natural scenes due to the bird view, and thus remain challenging to learn discriminative scene representation. Recent solutions design \textit{local semantic descriptors} so that region of interests (RoIs) can be properly highlighted. However, each local descriptor has limited description capability and the overall scene representation remains to be refined. In this paper, we solve this problem by designing a novel representation set named \textit{instance representation bank} (IRB), which unifies multiple local descriptors under the multiple instance learning (MIL) formulation. This unified framework is not trivial as all the local semantic descriptors can be aligned to the same scene scheme, enhancing the scene representation capability. Specifically, our IRB learning framework consists of a backbone, an instance representation bank, a semantic fusion module and a scene scheme alignment loss function. All the components are organized in an end-to-end manner. Extensive experiments on three aerial scene benchmarks demonstrate that our proposed method outperforms the state-of-the-art approaches by a large margin.
All Grains, One Scheme : Learning Multi-grain Instance Representation for Aerial Scene Classification
May 06, 2022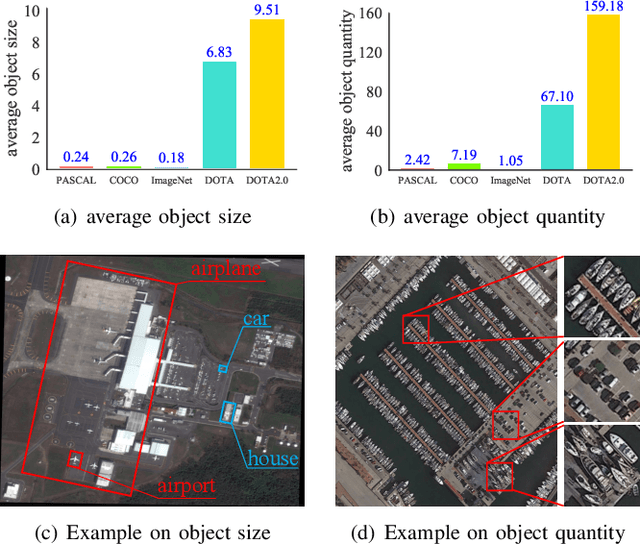
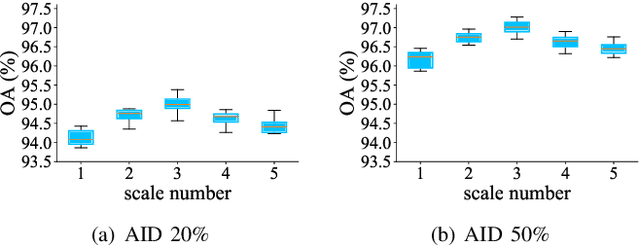
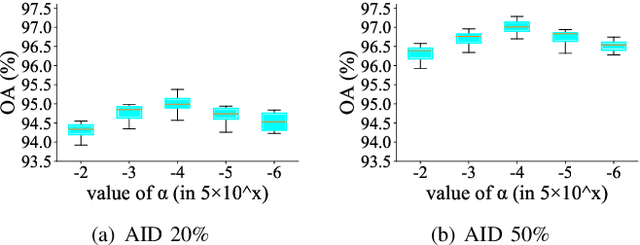
Aerial scene classification remains challenging as: 1) the size of key objects in determining the scene scheme varies greatly; 2) many objects irrelevant to the scene scheme are often flooded in the image. Hence, how to effectively perceive the region of interests (RoIs) from a variety of sizes and build more discriminative representation from such complicated object distribution is vital to understand an aerial scene. In this paper, we propose a novel all grains, one scheme (AGOS) framework to tackle these challenges. To the best of our knowledge, it is the first work to extend the classic multiple instance learning into multi-grain formulation. Specially, it consists of a multi-grain perception module (MGP), a multi-branch multi-instance representation module (MBMIR) and a self-aligned semantic fusion (SSF) module. Firstly, our MGP preserves the differential dilated convolutional features from the backbone, which magnifies the discriminative information from multi-grains. Then, our MBMIR highlights the key instances in the multi-grain representation under the MIL formulation. Finally, our SSF allows our framework to learn the same scene scheme from multi-grain instance representations and fuses them, so that the entire framework is optimized as a whole. Notably, our AGOS is flexible and can be easily adapted to existing CNNs in a plug-and-play manner. Extensive experiments on UCM, AID and NWPU benchmarks demonstrate that our AGOS achieves a comparable performance against the state-of-the-art methods.
A Multi-Stage Duplex Fusion ConvNet for Aerial Scene Classification
Mar 29, 2022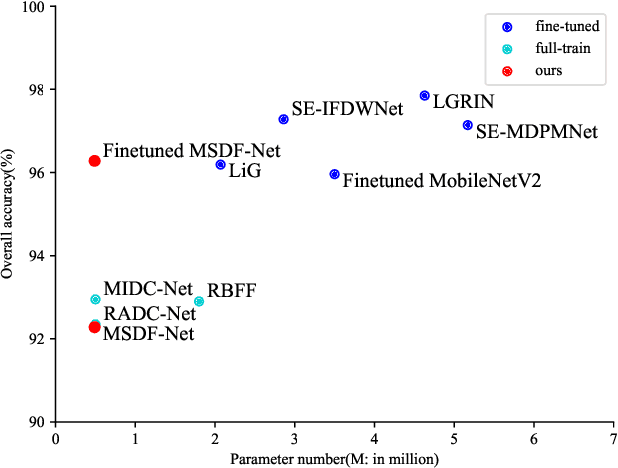

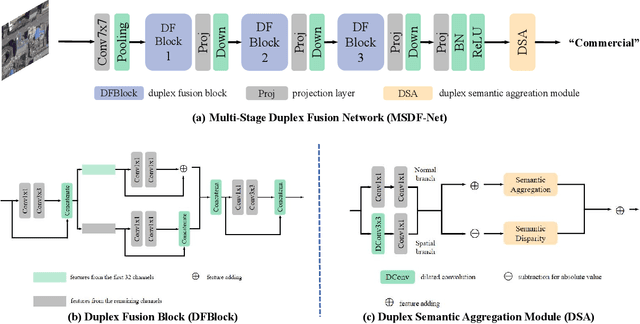

Existing deep learning based methods effectively prompt the performance of aerial scene classification. However, due to the large amount of parameters and computational cost, it is rather difficult to apply these methods to multiple real-time remote sensing applications such as on-board data preception on drones and satellites. In this paper, we address this task by developing a light-weight ConvNet named multi-stage duplex fusion network (MSDF-Net). The key idea is to use parameters as little as possible while obtaining as strong as possible scene representation capability. To this end, a residual-dense duplex fusion strategy is developed to enhance the feature propagation while re-using parameters as much as possible, and is realized by our duplex fusion block (DFblock). Specifically, our MSDF-Net consists of multi-stage structures with DFblock. Moreover, duplex semantic aggregation (DSA) module is developed to mine the remote sensing scene information from extracted convolutional features, which also contains two parallel branches for semantic description. Extensive experiments are conducted on three widely-used aerial scene classification benchmarks, and reflect that our MSDF-Net can achieve a competitive performance against the recent state-of-art while reducing up to 80% parameter numbers. Particularly, an accuracy of 92.96% is achieved on AID with only 0.49M parameters.