 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral-Progressive Thought Flow for Lightweight Multimodal Reasoning
Jun 01, 2026Multimodal spatial reasoning often relies on long chains of intermediate textual and visual thoughts, where accumulating visual tokens and dense cross-modal attention incur substantial computation and memory overhead. To address this challenge, we propose Spectral-Progressive Thought Flow (SpecFlow), a novel lightweight multimodal spatial reasoning framework that represents intermediate visual thoughts in a fixed-size discrete cosine space. By exploiting strong energy compaction, SpecFlow preserves global layout and relational structure while introducing high-frequency details only when increased spatial precision is required. To align visual state evolution with linguistic intent, classifier-free guidance enables autoregressive textual thoughts to steer flow-based updates of the visual workspace/state without expanding the context. As a result, SpecFlow maintains a bounded visual workspace whose updates depend only on the current visual state and accumulated textual trace, enabling long-horizon inference with stable latency and memory usage independent of reasoning depth. Empirical results show that SpecFlow achieves competitive or superior reasoning performance while reducing computation and KV cache costs by up to 2.1 times.
MaCP: Minimal yet Mighty Adaptation via Hierarchical Cosine Projection
May 29, 2025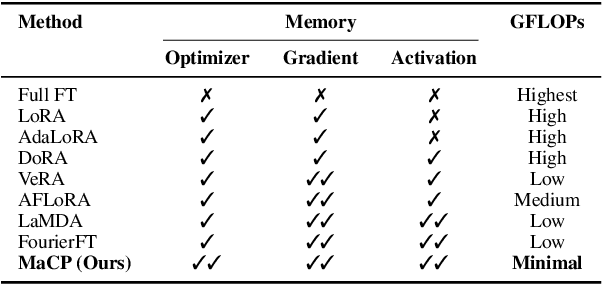
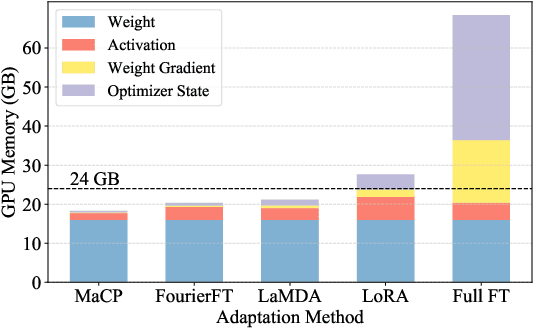
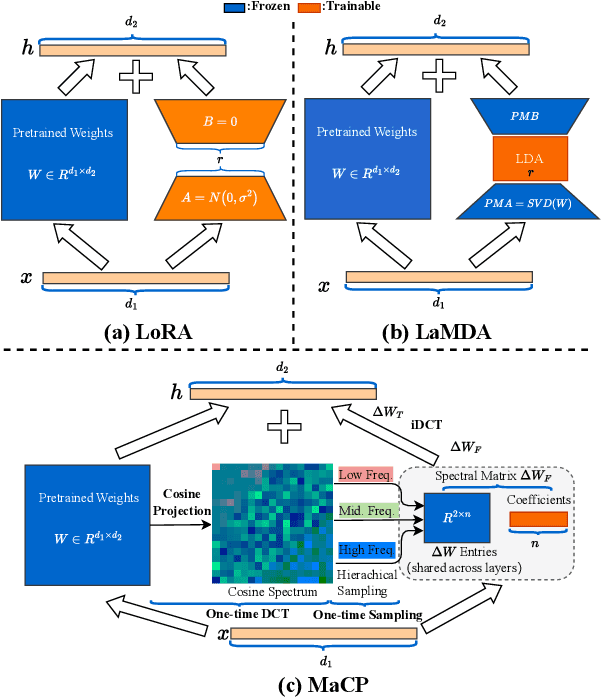
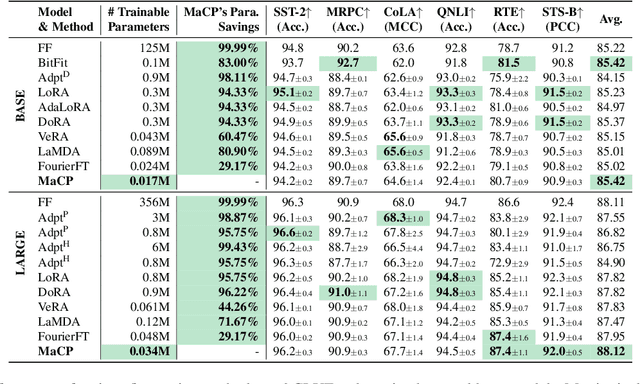
We present a new adaptation method MaCP, Minimal yet Mighty adaptive Cosine Projection, that achieves exceptional performance while requiring minimal parameters and memory for fine-tuning large foundation models. Its general idea is to exploit the superior energy compaction and decorrelation properties of cosine projection to improve both model efficiency and accuracy. Specifically, it projects the weight change from the low-rank adaptation into the discrete cosine space. Then, the weight change is partitioned over different levels of the discrete cosine spectrum, and each partition's most critical frequency components are selected. Extensive experiments demonstrate the effectiveness of MaCP across a wide range of single-modality tasks, including natural language understanding, natural language generation, text summarization, as well as multi-modality tasks such as image classification and video understanding. MaCP consistently delivers superior accuracy, significantly reduced computational complexity, and lower memory requirements compared to existing alternatives.
DGFamba: Learning Flow Factorized State Space for Visual Domain Generalization
Apr 10, 2025Domain generalization aims to learn a representation from the source domain, which can be generalized to arbitrary unseen target domains. A fundamental challenge for visual domain generalization is the domain gap caused by the dramatic style variation whereas the image content is stable. The realm of selective state space, exemplified by VMamba, demonstrates its global receptive field in representing the content. However, the way exploiting the domain-invariant property for selective state space is rarely explored. In this paper, we propose a novel Flow Factorized State Space model, dubbed as DG-Famba, for visual domain generalization. To maintain domain consistency, we innovatively map the style-augmented and the original state embeddings by flow factorization. In this latent flow space, each state embedding from a certain style is specified by a latent probability path. By aligning these probability paths in the latent space, the state embeddings are able to represent the same content distribution regardless of the style differences. Extensive experiments conducted on various visual domain generalization settings show its state-of-the-art performance.
Learning Fine-grained Domain Generalization via Hyperbolic State Space Hallucination
Apr 10, 2025



Fine-grained domain generalization (FGDG) aims to learn a fine-grained representation that can be well generalized to unseen target domains when only trained on the source domain data. Compared with generic domain generalization, FGDG is particularly challenging in that the fine-grained category can be only discerned by some subtle and tiny patterns. Such patterns are particularly fragile under the cross-domain style shifts caused by illumination, color and etc. To push this frontier, this paper presents a novel Hyperbolic State Space Hallucination (HSSH) method. It consists of two key components, namely, state space hallucination (SSH) and hyperbolic manifold consistency (HMC). SSH enriches the style diversity for the state embeddings by firstly extrapolating and then hallucinating the source images. Then, the pre- and post- style hallucinate state embeddings are projected into the hyperbolic manifold. The hyperbolic state space models the high-order statistics, and allows a better discernment of the fine-grained patterns. Finally, the hyperbolic distance is minimized, so that the impact of style variation on fine-grained patterns can be eliminated. Experiments on three FGDG benchmarks demonstrate its state-of-the-art performance.
SSH: Sparse Spectrum Adaptation via Discrete Hartley Transformation
Feb 08, 2025



Low-rank adaptation (LoRA) has been demonstrated effective in reducing the trainable parameter number when fine-tuning a large foundation model (LLM). However, it still encounters computational and memory challenges when scaling to larger models or addressing more complex task adaptation. In this work, we introduce Sparse Spectrum Adaptation via Discrete Hartley Transformation (SSH), a novel approach that significantly reduces the number of trainable parameters while enhancing model performance. It selects the most informative spectral components across all layers, under the guidance of the initial weights after a discrete Hartley transformation (DHT). The lightweight inverse DHT then projects the spectrum back into the spatial domain for updates. Extensive experiments across both single-modality tasks such as language understanding and generation and multi-modality tasks such as video-text understanding demonstrate that SSH outperforms existing parameter-efficient fine-tuning (PEFT) methods while achieving substantial reductions in computational cost and memory requirements.
Parameter-Efficient Fine-Tuning via Selective Discrete Cosine Transform
Oct 09, 2024In the era of large language models, parameter-efficient fine-tuning (PEFT) has been extensively studied. However, these approaches usually rely on the space domain, which encounters storage challenges especially when handling extensive adaptations or larger models. The frequency domain, in contrast, is more effective in compressing trainable parameters while maintaining the expressive capability. In this paper, we propose a novel Selective Discrete Cosine Transformation (sDCTFT) fine-tuning scheme to push this frontier. Its general idea is to exploit the superior energy compaction and decorrelation properties of DCT to improve both model efficiency and accuracy. Specifically, it projects the weight change from the low-rank adaptation into the discrete cosine space. Then, the weight change is partitioned over different levels of the discrete cosine spectrum, and the most critical frequency components in each partition are selected. Extensive experiments on four benchmark datasets demonstrate the superior accuracy, reduced computational cost, and lower storage requirements of the proposed method over the prior arts. For instance, when performing instruction tuning on the LLaMA3.1-8B model, sDCTFT outperforms LoRA with just 0.05M trainable parameters compared to LoRA's 38.2M, and surpasses FourierFT with 30\% less trainable parameters. The source code will be publicly available.
Learning Spectral-Decomposed Tokens for Domain Generalized Semantic Segmentation
Jul 29, 2024



The rapid development of Vision Foundation Model (VFM) brings inherent out-domain generalization for a variety of down-stream tasks. Among them, domain generalized semantic segmentation (DGSS) holds unique challenges as the cross-domain images share common pixel-wise content information but vary greatly in terms of the style. In this paper, we present a novel Spectral-dEcomposed Token (SET) learning framework to advance the frontier. Delving into further than existing fine-tuning token & frozen backbone paradigm, the proposed SET especially focuses on the way learning style-invariant features from these learnable tokens. Particularly, the frozen VFM features are first decomposed into the phase and amplitude components in the frequency space, which mainly contain the information of content and style, respectively, and then separately processed by learnable tokens for task-specific information extraction. After the decomposition, style variation primarily impacts the token-based feature enhancement within the amplitude branch. To address this issue, we further develop an attention optimization method to bridge the gap between style-affected representation and static tokens during inference. Extensive cross-domain experiments show its state-of-the-art performance.
Modeling Weather Uncertainty for Multi-weather Co-Presence Estimation
Mar 29, 2024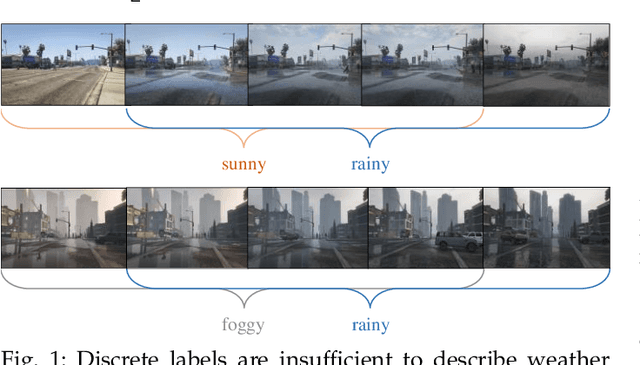
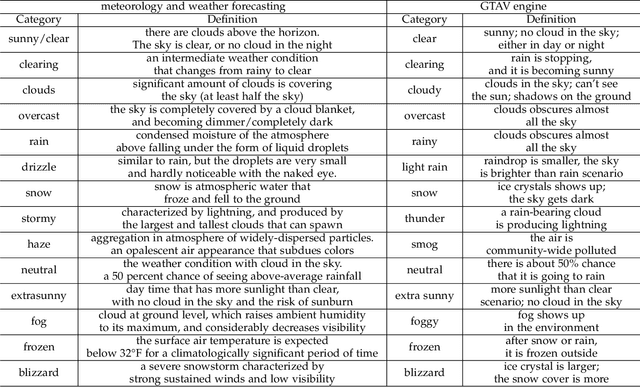
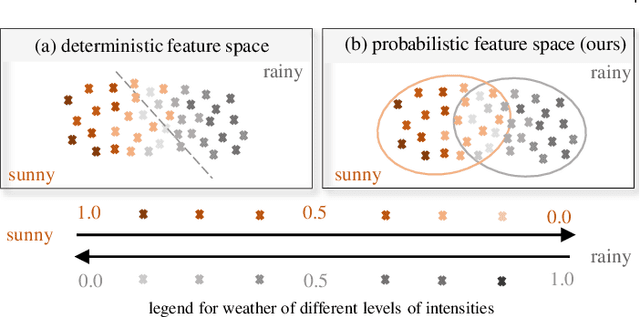
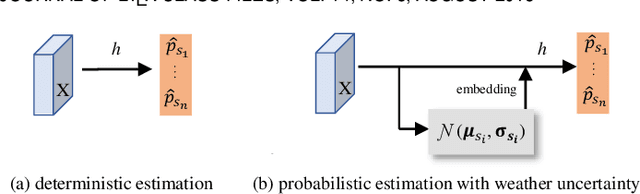
Images from outdoor scenes may be taken under various weather conditions. It is well studied that weather impacts the performance of computer vision algorithms and needs to be handled properly. However, existing algorithms model weather condition as a discrete status and estimate it using multi-label classification. The fact is that, physically, specifically in meteorology, weather are modeled as a continuous and transitional status. Instead of directly implementing hard classification as existing multi-weather classification methods do, we consider the physical formulation of multi-weather conditions and model the impact of physical-related parameter on learning from the image appearance. In this paper, we start with solid revisit of the physics definition of weather and how it can be described as a continuous machine learning and computer vision task. Namely, we propose to model the weather uncertainty, where the level of probability and co-existence of multiple weather conditions are both considered. A Gaussian mixture model is used to encapsulate the weather uncertainty and a uncertainty-aware multi-weather learning scheme is proposed based on prior-posterior learning. A novel multi-weather co-presence estimation transformer (MeFormer) is proposed. In addition, a new multi-weather co-presence estimation (MePe) dataset, along with 14 fine-grained weather categories and 16,078 samples, is proposed to benchmark both conventional multi-label weather classification task and multi-weather co-presence estimation task. Large scale experiments show that the proposed method achieves state-of-the-art performance and substantial generalization capabilities on both the conventional multi-label weather classification task and the proposed multi-weather co-presence estimation task. Besides, modeling weather uncertainty also benefits adverse-weather semantic segmentation.
Constraint Latent Space Matters: An Anti-anomalous Waveform Transformation Solution from Photoplethysmography to Arterial Blood Pressure
Feb 23, 2024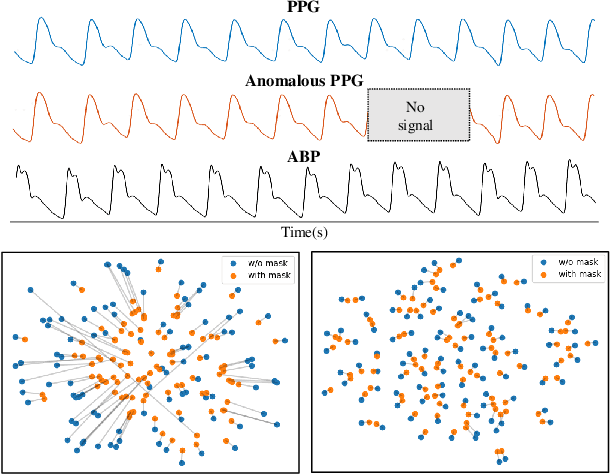
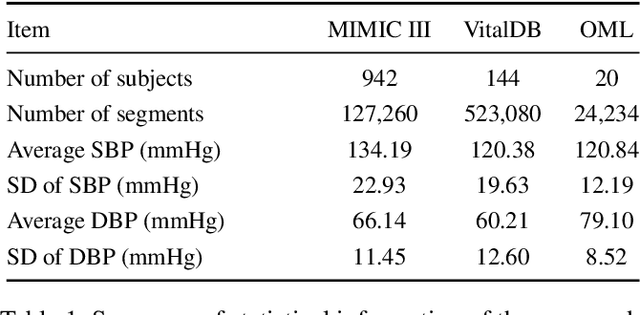
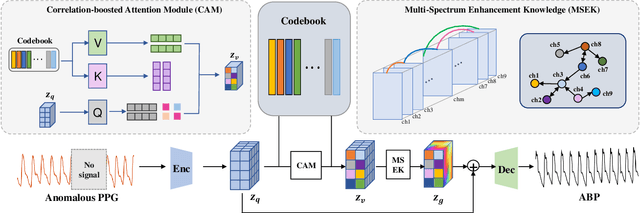
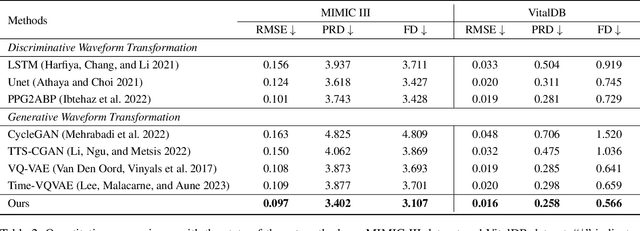
Arterial blood pressure (ABP) holds substantial promise for proactive cardiovascular health management. Notwithstanding its potential, the invasive nature of ABP measurements confines their utility primarily to clinical environments, limiting their applicability for continuous monitoring beyond medical facilities. The conversion of photoplethysmography (PPG) signals into ABP equivalents has garnered significant attention due to its potential in revolutionizing cardiovascular disease management. Recent strides in PPG-to-ABP prediction encompass the integration of generative and discriminative models. Despite these advances, the efficacy of these models is curtailed by the latent space shift predicament, stemming from alterations in PPG data distribution across disparate hardware and individuals, potentially leading to distorted ABP waveforms. To tackle this problem, we present an innovative solution named the Latent Space Constraint Transformer (LSCT), leveraging a quantized codebook to yield robust latent spaces by employing multiple discretizing bases. To facilitate improved reconstruction, the Correlation-boosted Attention Module (CAM) is introduced to systematically query pertinent bases on a global scale. Furthermore, to enhance expressive capacity, we propose the Multi-Spectrum Enhancement Knowledge (MSEK), which fosters local information flow within the channels of latent code and provides additional embedding for reconstruction. Through comprehensive experimentation on both publicly available datasets and a private downstream task dataset, the proposed approach demonstrates noteworthy performance enhancements compared to existing methods. Extensive ablation studies further substantiate the effectiveness of each introduced module.
GOOD: Towards Domain Generalized Orientated Object Detection
Feb 20, 2024
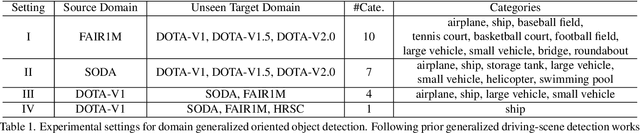
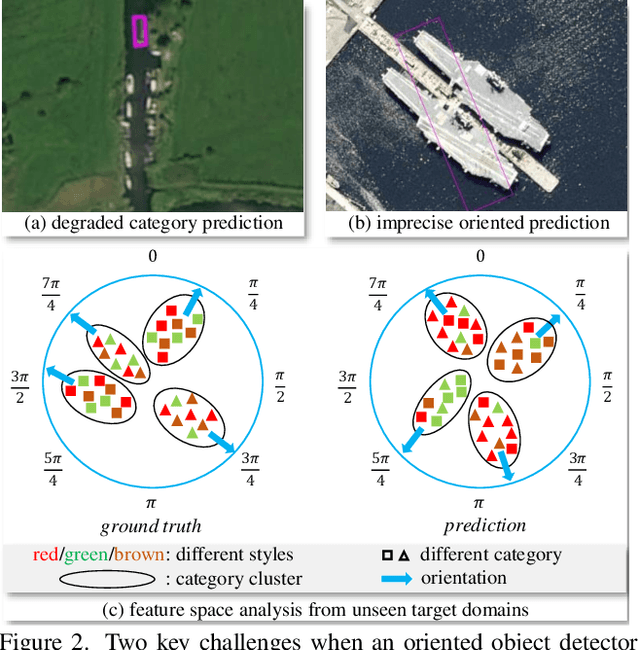
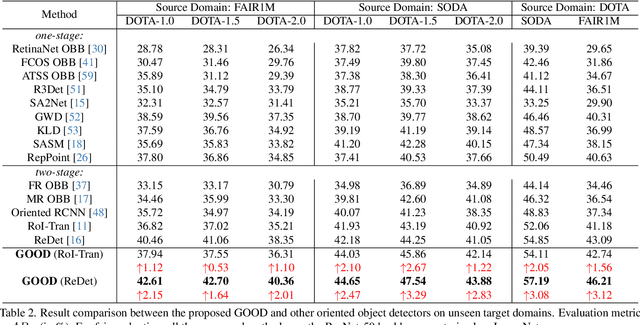
Oriented object detection has been rapidly developed in the past few years, but most of these methods assume the training and testing images are under the same statistical distribution, which is far from reality. In this paper, we propose the task of domain generalized oriented object detection, which intends to explore the generalization of oriented object detectors on arbitrary unseen target domains. Learning domain generalized oriented object detectors is particularly challenging, as the cross-domain style variation not only negatively impacts the content representation, but also leads to unreliable orientation predictions. To address these challenges, we propose a generalized oriented object detector (GOOD). After style hallucination by the emerging contrastive language-image pre-training (CLIP), it consists of two key components, namely, rotation-aware content consistency learning (RAC) and style consistency learning (SEC). The proposed RAC allows the oriented object detector to learn stable orientation representation from style-diversified samples. The proposed SEC further stabilizes the generalization ability of content representation from different image styles. Extensive experiments on multiple cross-domain settings show the state-of-the-art performance of GOOD. Source code will be publicly available.