 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGFamba: Learning Flow Factorized State Space for Visual Domain Generalization
Apr 10, 2025Domain generalization aims to learn a representation from the source domain, which can be generalized to arbitrary unseen target domains. A fundamental challenge for visual domain generalization is the domain gap caused by the dramatic style variation whereas the image content is stable. The realm of selective state space, exemplified by VMamba, demonstrates its global receptive field in representing the content. However, the way exploiting the domain-invariant property for selective state space is rarely explored. In this paper, we propose a novel Flow Factorized State Space model, dubbed as DG-Famba, for visual domain generalization. To maintain domain consistency, we innovatively map the style-augmented and the original state embeddings by flow factorization. In this latent flow space, each state embedding from a certain style is specified by a latent probability path. By aligning these probability paths in the latent space, the state embeddings are able to represent the same content distribution regardless of the style differences. Extensive experiments conducted on various visual domain generalization settings show its state-of-the-art performance.
Learning Fine-grained Domain Generalization via Hyperbolic State Space Hallucination
Apr 10, 2025Fine-grained domain generalization (FGDG) aims to learn a fine-grained representation that can be well generalized to unseen target domains when only trained on the source domain data. Compared with generic domain generalization, FGDG is particularly challenging in that the fine-grained category can be only discerned by some subtle and tiny patterns. Such patterns are particularly fragile under the cross-domain style shifts caused by illumination, color and etc. To push this frontier, this paper presents a novel Hyperbolic State Space Hallucination (HSSH) method. It consists of two key components, namely, state space hallucination (SSH) and hyperbolic manifold consistency (HMC). SSH enriches the style diversity for the state embeddings by firstly extrapolating and then hallucinating the source images. Then, the pre- and post- style hallucinate state embeddings are projected into the hyperbolic manifold. The hyperbolic state space models the high-order statistics, and allows a better discernment of the fine-grained patterns. Finally, the hyperbolic distance is minimized, so that the impact of style variation on fine-grained patterns can be eliminated. Experiments on three FGDG benchmarks demonstrate its state-of-the-art performance.
Cut the Deadwood Out: Post-Training Model Purification with Selective Module Substitution
Dec 29, 2024The success of DNNs often depends on training with large-scale datasets, but building such datasets is both expensive and challenging. Consequently, public datasets from open-source platforms like HuggingFace have become popular, posing significant risks of data poisoning attacks. Existing backdoor defenses in NLP primarily focus on identifying and removing poisoned samples; however, purifying a backdoored model with these sample-cleaning approaches typically requires expensive retraining. Therefore, we propose Greedy Module Substitution (GMS), which identifies and substitutes ''deadwood'' modules (i.e., components critical to backdoor pathways) in a backdoored model to purify it. Our method relaxes the common dependency of prior model purification methods on clean datasets or clean auxiliary models. When applied to RoBERTa-large under backdoor attacks, GMS demonstrates strong effectiveness across various settings, particularly against widely recognized challenging attacks like LWS, achieving a post-purification attack success rate (ASR) of 9.7% on SST-2 compared to 58.8% for the best baseline approach.
Scalable Frame-based Construction of Sociocultural NormBases for Socially-Aware Dialogues
Oct 04, 2024


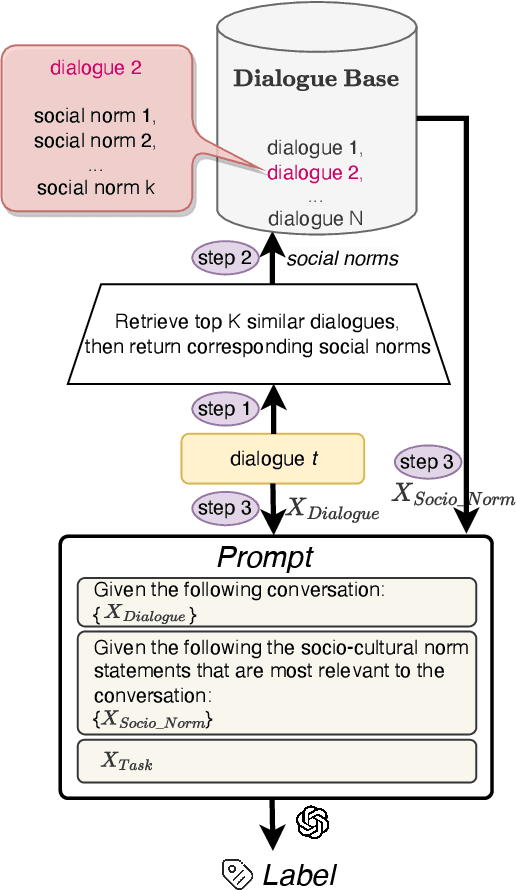
Sociocultural norms serve as guiding principles for personal conduct in social interactions, emphasizing respect, cooperation, and appropriate behavior, which is able to benefit tasks including conversational information retrieval, contextual information retrieval and retrieval-enhanced machine learning. We propose a scalable approach for constructing a Sociocultural Norm (SCN) Base using Large Language Models (LLMs) for socially aware dialogues. We construct a comprehensive and publicly accessible Chinese Sociocultural NormBase. Our approach utilizes socially aware dialogues, enriched with contextual frames, as the primary data source to constrain the generating process and reduce the hallucinations. This enables extracting of high-quality and nuanced natural-language norm statements, leveraging the pragmatic implications of utterances with respect to the situation. As real dialogue annotated with gold frames are not readily available, we propose using synthetic data. Our empirical results show: (i) the quality of the SCNs derived from synthetic data is comparable to that from real dialogues annotated with gold frames, and (ii) the quality of the SCNs extracted from real data, annotated with either silver (predicted) or gold frames, surpasses that without the frame annotations. We further show the effectiveness of the extracted SCNs in a RAG-based (Retrieval-Augmented Generation) model to reason about multiple downstream dialogue tasks.
* 17 pages
Learning Spectral-Decomposed Tokens for Domain Generalized Semantic Segmentation
Jul 29, 2024



The rapid development of Vision Foundation Model (VFM) brings inherent out-domain generalization for a variety of down-stream tasks. Among them, domain generalized semantic segmentation (DGSS) holds unique challenges as the cross-domain images share common pixel-wise content information but vary greatly in terms of the style. In this paper, we present a novel Spectral-dEcomposed Token (SET) learning framework to advance the frontier. Delving into further than existing fine-tuning token & frozen backbone paradigm, the proposed SET especially focuses on the way learning style-invariant features from these learnable tokens. Particularly, the frozen VFM features are first decomposed into the phase and amplitude components in the frequency space, which mainly contain the information of content and style, respectively, and then separately processed by learnable tokens for task-specific information extraction. After the decomposition, style variation primarily impacts the token-based feature enhancement within the amplitude branch. To address this issue, we further develop an attention optimization method to bridge the gap between style-affected representation and static tokens during inference. Extensive cross-domain experiments show its state-of-the-art performance.
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Jun 26, 2024



Automated software engineering has been greatly empowered by the recent advances in Large Language Models (LLMs) for programming. While current benchmarks have shown that LLMs can perform various software engineering tasks like human developers, the majority of their evaluations are limited to short and self-contained algorithmic tasks. Solving challenging and practical programming tasks requires the capability of utilizing diverse function calls as tools to efficiently implement functionalities like data analysis and web development. In addition, using multiple tools to solve a task needs compositional reasoning by accurately understanding complex instructions. Fulfilling both of these characteristics can pose a great challenge for LLMs. To assess how well LLMs can solve challenging and practical programming tasks, we introduce Bench, a benchmark that challenges LLMs to invoke multiple function calls as tools from 139 libraries and 7 domains for 1,140 fine-grained programming tasks. To evaluate LLMs rigorously, each programming task encompasses 5.6 test cases with an average branch coverage of 99%. In addition, we propose a natural-language-oriented variant of Bench, Benchi, that automatically transforms the original docstrings into short instructions only with essential information. Our extensive evaluation of 60 LLMs shows that LLMs are not yet capable of following complex instructions to use function calls precisely, with scores up to 60%, significantly lower than the human performance of 97%. The results underscore the need for further advancements in this area.
SCAR: Efficient Instruction-Tuning for Large Language Models via Style Consistency-Aware Response Ranking
Jun 16, 2024



Recent studies have shown that maintaining a consistent response style by human experts and enhancing data quality in training sets can significantly improve the performance of fine-tuned Large Language Models (LLMs) while reducing the number of training examples needed. However, the precise definition of style and the relationship between style, data quality, and LLM performance remains unclear. This research decomposes response style into presentation and composition styles and finds that, among training data of similar quality, those with higher style consistency lead to better LLM performance. Inspired by this, we introduce Style Consistency-Aware Response Ranking (SCAR), which automatically prioritizes instruction-response pairs in the training set based on their response stylistic consistency. By selecting the most style-consistent examples, ranging from the top 25% to 0.7% of the full dataset, the fine-tuned LLMs can match or even surpass the performance of models trained on the entire dataset in coding and open-ended question-answering benchmarks. Code and data are available at https://github.com/zhuang-li/SCAR .
IMO: Greedy Layer-Wise Sparse Representation Learning for Out-of-Distribution Text Classification with Pre-trained Models
Apr 21, 2024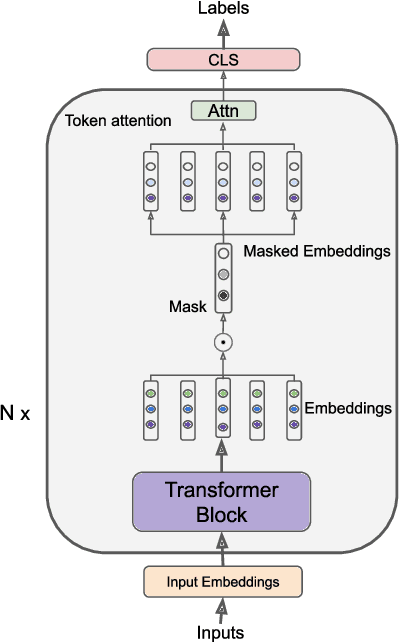
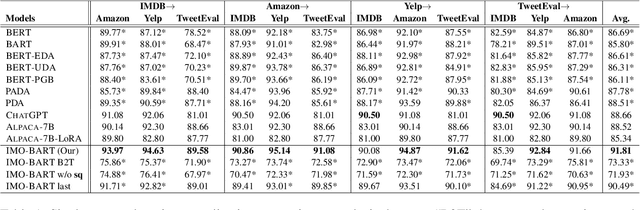
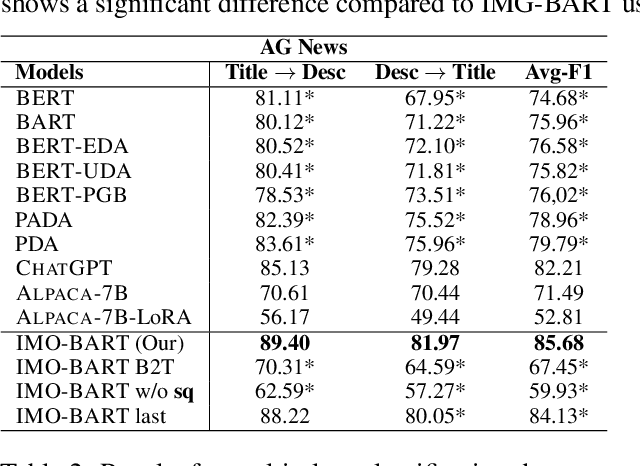
Machine learning models have made incredible progress, but they still struggle when applied to examples from unseen domains. This study focuses on a specific problem of domain generalization, where a model is trained on one source domain and tested on multiple target domains that are unseen during training. We propose IMO: Invariant features Masks for Out-of-Distribution text classification, to achieve OOD generalization by learning invariant features. During training, IMO would learn sparse mask layers to remove irrelevant features for prediction, where the remaining features keep invariant. Additionally, IMO has an attention module at the token level to focus on tokens that are useful for prediction. Our comprehensive experiments show that IMO substantially outperforms strong baselines in terms of various evaluation metrics and settings.
GOOD: Towards Domain Generalized Orientated Object Detection
Feb 20, 2024
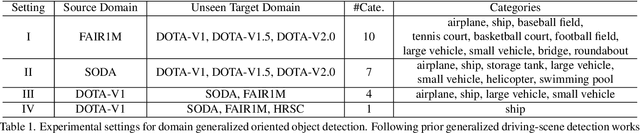
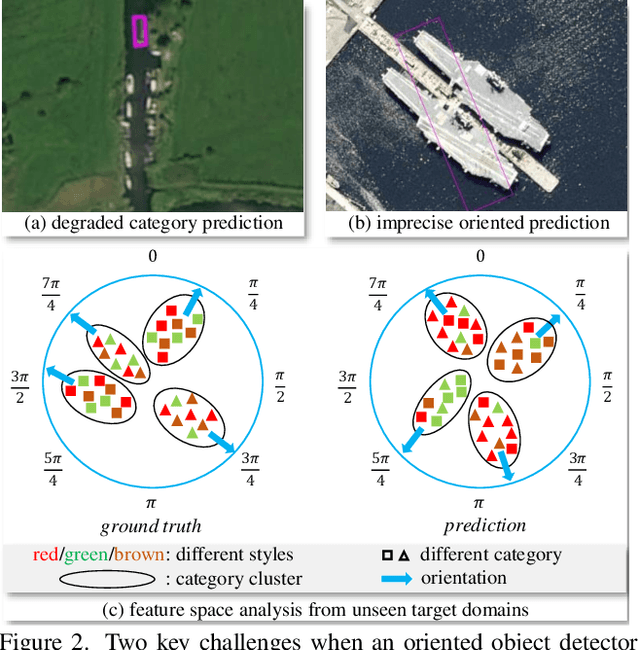
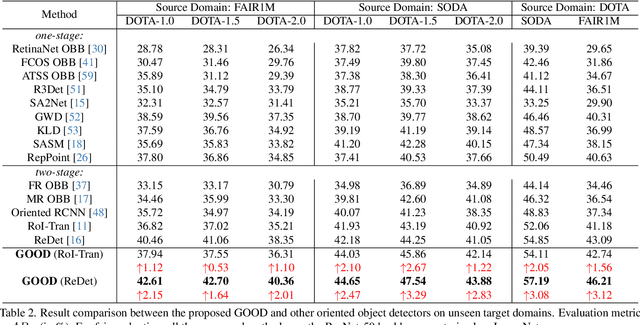
Oriented object detection has been rapidly developed in the past few years, but most of these methods assume the training and testing images are under the same statistical distribution, which is far from reality. In this paper, we propose the task of domain generalized oriented object detection, which intends to explore the generalization of oriented object detectors on arbitrary unseen target domains. Learning domain generalized oriented object detectors is particularly challenging, as the cross-domain style variation not only negatively impacts the content representation, but also leads to unreliable orientation predictions. To address these challenges, we propose a generalized oriented object detector (GOOD). After style hallucination by the emerging contrastive language-image pre-training (CLIP), it consists of two key components, namely, rotation-aware content consistency learning (RAC) and style consistency learning (SEC). The proposed RAC allows the oriented object detector to learn stable orientation representation from style-diversified samples. The proposed SEC further stabilizes the generalization ability of content representation from different image styles. Extensive experiments on multiple cross-domain settings show the state-of-the-art performance of GOOD. Source code will be publicly available.
RENOVI: A Benchmark Towards Remediating Norm Violations in Socio-Cultural Conversations
Feb 17, 2024



Norm violations occur when individuals fail to conform to culturally accepted behaviors, which may lead to potential conflicts. Remediating norm violations requires social awareness and cultural sensitivity of the nuances at play. To equip interactive AI systems with a remediation ability, we offer ReNoVi - a large-scale corpus of 9,258 multi-turn dialogues annotated with social norms, as well as define a sequence of tasks to help understand and remediate norm violations step by step. ReNoVi consists of two parts: 512 human-authored dialogues (real data), and 8,746 synthetic conversations generated by ChatGPT through prompt learning. While collecting sufficient human-authored data is costly, synthetic conversations provide suitable amounts of data to help mitigate the scarcity of training data, as well as the chance to assess the alignment between LLMs and humans in the awareness of social norms. We thus harness the power of ChatGPT to generate synthetic training data for our task. To ensure the quality of both human-authored and synthetic data, we follow a quality control protocol during data collection. Our experimental results demonstrate the importance of remediating norm violations in socio-cultural conversations, as well as the improvement in performance obtained from synthetic data.