 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization in LLM Problem Solving: The Case of the Shortest Path
Apr 16, 2026Whether language models can systematically generalize remains actively debated. Yet empirical performance is jointly shaped by multiple factors such as training data, training paradigms, and inference-time strategies, making failures difficult to interpret. We introduce a controlled synthetic environment based on shortest-path planning, a canonical composable sequential optimization problem. The setup enables clean separation of these factors and supports two orthogonal axes of generalization: spatial transfer to unseen maps and length scaling to longer-horizon problems. We find that models exhibit strong spatial transfer but consistently fail under length scaling due to recursive instability. We further analyze how distinct stages of the learning pipeline influence systematic problem-solving: for example, data coverage sets capability limits; reinforcement learning improves training stability but does not expand those limits; and inference-time scaling enhances performance but cannot rescue length-scaling failures.
Transformers Are Born Biased: Structural Inductive Biases at Random Initialization and Their Practical Consequences
Feb 05, 2026Transformers underpin modern large language models (LLMs) and are commonly assumed to be behaviorally unstructured at random initialization, with all meaningful preferences emerging only through large-scale training. We challenge this assumption by showing that randomly initialized transformers already exhibit strong and systematic structural biases. In particular, untrained models display extreme token preferences: across random input sequences, certain tokens are predicted with probabilities orders of magnitude larger. We provide a mechanistic explanation for this phenomenon by dissecting the transformer architecture at initialization. We show that extreme token preference arises from a contraction of token representations along a random seed-dependent direction. This contraction is driven by two interacting forces: (i) asymmetric nonlinear activations in MLP sublayers induce global (inter-sequence) representation concentration, and (ii) self-attention further amplifies this effect through local (intra-sequence) aggregation. Together, these mechanisms align hidden representations along a direction determined solely by the random initialization, producing highly non-uniform next-token predictions. Beyond mechanistic insight, we demonstrate that these initialization-induced biases persist throughout training, forming a stable and intrinsic model identity. Leveraging this property, we introduce SeedPrint, a fingerprinting method that can reliably distinguish models that differ only in their random initialization, even after extensive training and under substantial distribution shift. Finally, we identify a fundamental positional discrepancy inherent to the attention mechanism's intra-sequence contraction that is causally linked to the attention-sink phenomenon. This discovery provides a principled explanation for the emergence of sinks and offers a pathway for their control.
Mapping the Vanishing and Transformation of Urban Villages in China
Nov 17, 2025Urban villages (UVs), informal settlements embedded within China's urban fabric, have undergone widespread demolition and redevelopment in recent decades. However, there remains a lack of systematic evaluation of whether the demolished land has been effectively reused, raising concerns about the efficacy and sustainability of current redevelopment practices. To address the gap, this study proposes a deep learning-based framework to monitor the spatiotemporal changes of UVs in China. Specifically, semantic segmentation of multi-temporal remote sensing imagery is first used to map evolving UV boundaries, and then post-demolition land use is classified into six categories based on the "remained-demolished-redeveloped" phase: incomplete demolition, vacant land, construction sites, buildings, green spaces, and others. Four representative cities from China's four economic regions were selected as the study areas, i.e., Guangzhou (East), Zhengzhou (Central), Xi'an (West), and Harbin (Northeast). The results indicate: 1) UV redevelopment processes were frequently prolonged; 2) redevelopment transitions primarily occurred in peripheral areas, whereas urban cores remained relatively stable; and 3) three spatiotemporal transformation pathways, i.e., synchronized redevelopment, delayed redevelopment, and gradual optimization, were revealed. This study highlights the fragmented, complex and nonlinear nature of UV redevelopment, underscoring the need for tiered and context-sensitive planning strategies. By linking spatial dynamics with the context of redevelopment policies, the findings offer valuable empirical insights that support more inclusive, efficient, and sustainable urban renewal, while also contributing to a broader global understanding of informal settlement transformations.
* Appendix A. Supplementary data at https://ars.els-cdn.com/content/image/1-s2.0-S2210670725008418-mmc1.docx
Cut the Deadwood Out: Post-Training Model Purification with Selective Module Substitution
Dec 29, 2024The success of DNNs often depends on training with large-scale datasets, but building such datasets is both expensive and challenging. Consequently, public datasets from open-source platforms like HuggingFace have become popular, posing significant risks of data poisoning attacks. Existing backdoor defenses in NLP primarily focus on identifying and removing poisoned samples; however, purifying a backdoored model with these sample-cleaning approaches typically requires expensive retraining. Therefore, we propose Greedy Module Substitution (GMS), which identifies and substitutes ''deadwood'' modules (i.e., components critical to backdoor pathways) in a backdoored model to purify it. Our method relaxes the common dependency of prior model purification methods on clean datasets or clean auxiliary models. When applied to RoBERTa-large under backdoor attacks, GMS demonstrates strong effectiveness across various settings, particularly against widely recognized challenging attacks like LWS, achieving a post-purification attack success rate (ASR) of 9.7% on SST-2 compared to 58.8% for the best baseline approach.
The Stronger the Diffusion Model, the Easier the Backdoor: Data Poisoning to Induce Copyright Breaches Without Adjusting Finetuning Pipeline
Jan 07, 2024The commercialization of diffusion models, renowned for their ability to generate high-quality images that are often indistinguishable from real ones, brings forth potential copyright concerns. Although attempts have been made to impede unauthorized access to copyrighted material during training and to subsequently prevent DMs from generating copyrighted images, the effectiveness of these solutions remains unverified. This study explores the vulnerabilities associated with copyright protection in DMs by introducing a backdoor data poisoning attack (SilentBadDiffusion) against text-to-image diffusion models. Our attack method operates without requiring access to or control over the diffusion model's training or fine-tuning processes; it merely involves the insertion of poisoning data into the clean training dataset. This data, comprising poisoning images equipped with prompts, is generated by leveraging the powerful capabilities of multimodal large language models and text-guided image inpainting techniques. Our experimental results and analysis confirm the method's effectiveness. By integrating a minor portion of non-copyright-infringing stealthy poisoning data into the clean dataset-rendering it free from suspicion-we can prompt the finetuned diffusion models to produce copyrighted content when activated by specific trigger prompts. These findings underline potential pitfalls in the prevailing copyright protection strategies and underscore the necessity for increased scrutiny and preventative measures against the misuse of DMs.
Towards Regulatable AI Systems: Technical Gaps and Policy Opportunities
Jun 22, 2023There is increasing attention being given to how to regulate AI systems. As governing bodies grapple with what values to encapsulate into regulation, we consider the technical half of the question: To what extent can AI experts vet an AI system for adherence to regulatory requirements? We investigate this question through two public sector procurement checklists, identifying what we can do now, what we should be able to do with technical innovation in AI, and what requirements necessitate a more interdisciplinary approach.
A Screen-Shooting Resilient Document Image Watermarking Scheme using Deep Neural Network
Mar 10, 2022
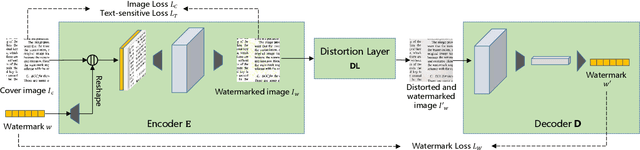
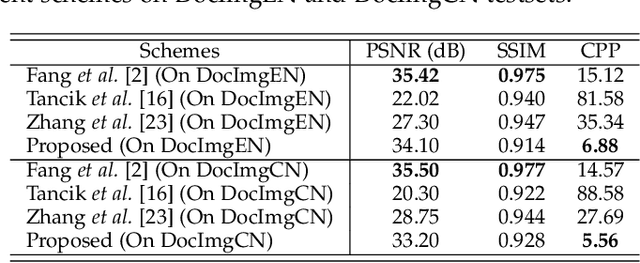

With the advent of the screen-reading era, the confidential documents displayed on the screen can be easily captured by a camera without leaving any traces. Thus, this paper proposes a novel screen-shooting resilient watermarking scheme for document image using deep neural network. By applying this scheme, when the watermarked image is displayed on the screen and captured by a camera, the watermark can be still extracted from the captured photographs. Specifically, our scheme is an end-to-end neural network with an encoder to embed watermark and a decoder to extract watermark. During the training process, a distortion layer between encoder and decoder is added to simulate the distortions introduced by screen-shooting process in real scenes, such as camera distortion, shooting distortion, light source distortion. Besides, an embedding strength adjustment strategy is designed to improve the visual quality of the watermarked image with little loss of extraction accuracy. The experimental results show that the scheme has higher robustness and visual quality than other three recent state-of-the-arts. Specially, even if the shooting distances and angles are in extreme, our scheme can also obtain high extraction accuracy.
Multi-view analysis of unregistered medical images using cross-view transformers
Mar 21, 2021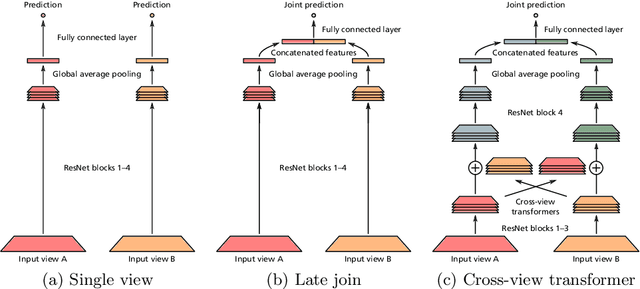

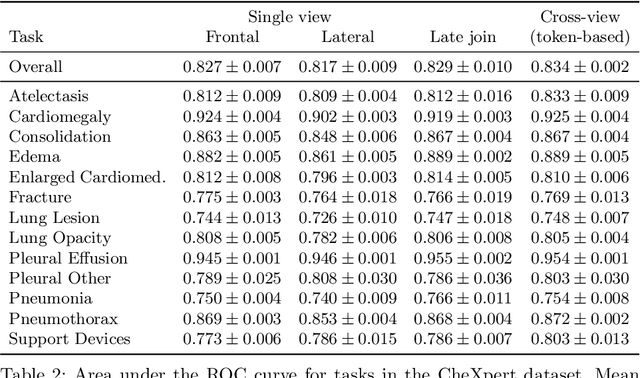
Multi-view medical image analysis often depends on the combination of information from multiple views. However, differences in perspective or other forms of misalignment can make it difficult to combine views effectively, as registration is not always possible. Without registration, views can only be combined at a global feature level, by joining feature vectors after global pooling. We present a novel cross-view transformer method to transfer information between unregistered views at the level of spatial feature maps. We demonstrate this method on multi-view mammography and chest X-ray datasets. On both datasets, we find that a cross-view transformer that links spatial feature maps can outperform a baseline model that joins feature vectors after global pooling.