 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeID-Eraser: Proactive Defense Against Face Swapping via Identity Perturbation
Apr 23, 2026Deepfake technologies have rapidly advanced with modern generative AI, and face swapping in particular poses serious threats to privacy and digital security. Existing proactive defenses mostly rely on pixel-level perturbations, which are ineffective against contemporary swapping models that extract robust high-level identity embeddings. We propose ID-Eraser, a feature-space proactive defense that removes identifiable facial information to prevent malicious face swapping. By injecting learnable perturbations into identity embeddings and reconstructing natural-looking protection images through a Face Revive Generator (FRG), ID-Eraser produces visually realistic results for humans while rendering the protected identities unusable for Deepfake models. Experiments show that ID-Eraser substantially disrupts identity recognition across diverse face recognition and swapping systems under strict black-box settings, achieving the lowest Top-1 accuracy (0.30) with the best FID (1.64) and LPIPS (0.020). Compared with swaps generated from clean inputs, the identity similarity of protected swaps drops sharply to an average of 0.504 across five representative face swapping models. ID-Eraser further demonstrates strong cross-dataset generalization, robustness to common distortions, and practical effectiveness on commercial APIs, reducing Tencent API similarity from 0.76 to 0.36.
LBFTI: Layer-Based Facial Template Inversion for Identity-Preserving Fine-Grained Face Reconstruction
Apr 20, 2026In face recognition systems, facial templates are widely adopted for identity authentication due to their compliance with the data minimization principle. However, facial template inversion technologies have posed a severe privacy leakage risk by enabling face reconstruction from templates. This paper proposes a Layer-Based Facial Template Inversion (LBFTI) method to reconstruct identity-preserving fine-grained face images. Our scheme decomposes face images into three layers: foreground layers (including eyebrows, eyes, nose, and mouth), midground layers (skin), and background layers (other parts). LBFTI leverages dedicated generators to produce these layers, adopting a rigorous three-stage training strategy: (1) independent refined generation of foreground and midground layers, (2) fusion of foreground and midground layers with template secondary injection to produce complete panoramic face images with background layers, and (3) joint fine-tuning of all modules to optimize inter-layer coordination and identity consistency. Experiments demonstrate that our LBFTI not only outperforms state-of-the-art methods in machine authentication performance, with a 25.3% improvement in TAR, but also achieves better similarity in human perception, as validated by both quantitative metrics and a questionnaire survey.
High-Fidelity Face Content Recovery via Tamper-Resilient Versatile Watermarking
Mar 25, 2026The proliferation of AIGC-driven face manipulation and deepfakes poses severe threats to media provenance, integrity, and copyright protection. Prior versatile watermarking systems typically rely on embedding explicit localization payloads, which introduces a fidelity--functionality trade-off: larger localization signals degrade visual quality and often reduce decoding robustness under strong generative edits. Moreover, existing methods rarely support content recovery, limiting their forensic value when original evidence must be reconstructed. To address these challenges, we present VeriFi, a versatile watermarking framework that unifies copyright protection, pixel-level manipulation localization, and high-fidelity face content recovery. VeriFi makes three key contributions: (1) it embeds a compact semantic latent watermark that serves as an content-preserving prior, enabling faithful restoration even after severe manipulations; (2) it achieves fine-grained localization without embedding localization-specific artifacts by correlating image features with decoded provenance signals; and (3) it introduces an AIGC attack simulator that combines latent-space mixing with seamless blending to improve robustness to realistic deepfake pipelines. Extensive experiments on CelebA-HQ and FFHQ show that VeriFi consistently outperforms strong baselines in watermark robustness, localization accuracy, and recovery quality, providing a practical and verifiable defense for deepfake forensics.
XLSR-MamBo: Scaling the Hybrid Mamba-Attention Backbone for Audio Deepfake Detection
Jan 06, 2026Advanced speech synthesis technologies have enabled highly realistic speech generation, posing security risks that motivate research into audio deepfake detection (ADD). While state space models (SSMs) offer linear complexity, pure causal SSMs architectures often struggle with the content-based retrieval required to capture global frequency-domain artifacts. To address this, we explore the scaling properties of hybrid architectures by proposing XLSR-MamBo, a modular framework integrating an XLSR front-end with synergistic Mamba-Attention backbones. We systematically evaluate four topological designs using advanced SSM variants, Mamba, Mamba2, Hydra, and Gated DeltaNet. Experimental results demonstrate that the MamBo-3-Hydra-N3 configuration achieves competitive performance compared to other state-of-the-art systems on the ASVspoof 2021 LA, DF, and In-the-Wild benchmarks. This performance benefits from Hydra's native bidirectional modeling, which captures holistic temporal dependencies more efficiently than the heuristic dual-branch strategies employed in prior works. Furthermore, evaluations on the DFADD dataset demonstrate robust generalization to unseen diffusion- and flow-matching-based synthesis methods. Crucially, our analysis reveals that scaling backbone depth effectively mitigates the performance variance and instability observed in shallower models. These results demonstrate the hybrid framework's ability to capture artifacts in spoofed speech signals, providing an effective method for ADD.
CLIP-FTI: Fine-Grained Face Template Inversion via CLIP-Driven Attribute Conditioning
Dec 17, 2025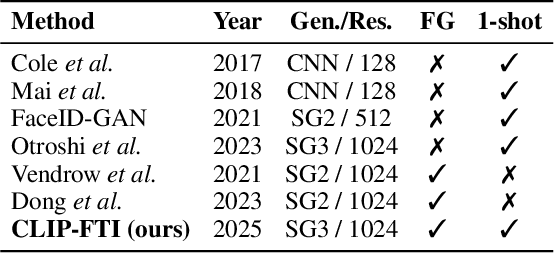
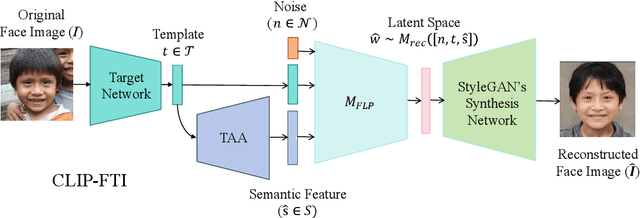
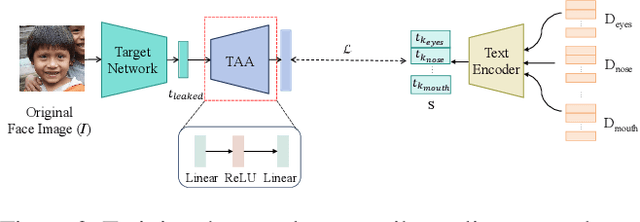
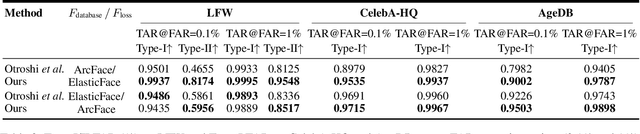
Face recognition systems store face templates for efficient matching. Once leaked, these templates pose a threat: inverting them can yield photorealistic surrogates that compromise privacy and enable impersonation. Although existing research has achieved relatively realistic face template inversion, the reconstructed facial images exhibit over-smoothed facial-part attributes (eyes, nose, mouth) and limited transferability. To address this problem, we present CLIP-FTI, a CLIP-driven fine-grained attribute conditioning framework for face template inversion. Our core idea is to use the CLIP model to obtain the semantic embeddings of facial features, in order to realize the reconstruction of specific facial feature attributes. Specifically, facial feature attribute embeddings extracted from CLIP are fused with the leaked template via a cross-modal feature interaction network and projected into the intermediate latent space of a pretrained StyleGAN. The StyleGAN generator then synthesizes face images with the same identity as the templates but with more fine-grained facial feature attributes. Experiments across multiple face recognition backbones and datasets show that our reconstructions (i) achieve higher identification accuracy and attribute similarity, (ii) recover sharper component-level attribute semantics, and (iii) improve cross-model attack transferability compared to prior reconstruction attacks. To the best of our knowledge, ours is the first method to use additional information besides the face template attack to realize face template inversion and obtains SOTA results.
Fine-Grained DINO Tuning with Dual Supervision for Face Forgery Detection
Nov 15, 2025The proliferation of sophisticated deepfakes poses significant threats to information integrity. While DINOv2 shows promise for detection, existing fine-tuning approaches treat it as generic binary classification, overlooking distinct artifacts inherent to different deepfake methods. To address this, we propose a DeepFake Fine-Grained Adapter (DFF-Adapter) for DINOv2. Our method incorporates lightweight multi-head LoRA modules into every transformer block, enabling efficient backbone adaptation. DFF-Adapter simultaneously addresses authenticity detection and fine-grained manipulation type classification, where classifying forgery methods enhances artifact sensitivity. We introduce a shared branch propagating fine-grained manipulation cues to the authenticity head. This enables multi-task cooperative optimization, explicitly enhancing authenticity discrimination with manipulation-specific knowledge. Utilizing only 3.5M trainable parameters, our parameter-efficient approach achieves detection accuracy comparable to or even surpassing that of current complex state-of-the-art methods.
Unlocking the Capabilities of Vision-Language Models for Generalizable and Explainable Deepfake Detection
Mar 19, 2025Current vision-language models (VLMs) have demonstrated remarkable capabilities in understanding multimodal data, but their potential remains underexplored for deepfake detection due to the misaligned of their knowledge and forensics patterns. To this end, we present a novel paradigm that unlocks VLMs' potential capabilities through three components: (1) A knowledge-guided forgery adaptation module that aligns VLM's semantic space with forensic features through contrastive learning with external manipulation knowledge; (2) A multi-modal prompt tuning framework that jointly optimizes visual-textual embeddings for both localization and explainability; (3) An iterative refinement strategy enabling multi-turn dialog for evidence-based reasoning. Our framework includes a VLM-based Knowledge-guided Forgery Detector (KFD), a VLM image encoder, and a Large Language Model (LLM). The VLM image encoder extracts visual prompt embeddings from images, while the LLM receives visual and question prompt embeddings for inference. The KFD is used to calculate correlations between image features and pristine/deepfake class embeddings, enabling forgery classification and localization. The outputs from these components are used to construct forgery prompt embeddings. Finally, we feed these prompt embeddings into the LLM to generate textual detection responses to assist judgment. Extensive experiments on multiple benchmarks, including FF++, CDF2, DFD, DFDCP, and DFDC, demonstrate that our scheme surpasses state-of-the-art methods in generalization performance, while also supporting multi-turn dialogue capabilities.
DFREC: DeepFake Identity Recovery Based on Identity-aware Masked Autoencoder
Dec 10, 2024Recent advances in deepfake forensics have primarily focused on improving the classification accuracy and generalization performance. Despite enormous progress in detection accuracy across a wide variety of forgery algorithms, existing algorithms lack intuitive interpretability and identity traceability to help with forensic investigation. In this paper, we introduce a novel DeepFake Identity Recovery scheme (DFREC) to fill this gap. DFREC aims to recover the pair of source and target faces from a deepfake image to facilitate deepfake identity tracing and reduce the risk of deepfake attack. It comprises three key components: an Identity Segmentation Module (ISM), a Source Identity Reconstruction Module (SIRM), and a Target Identity Reconstruction Module (TIRM). The ISM segments the input face into distinct source and target face information, and the SIRM reconstructs the source face and extracts latent target identity features with the segmented source information. The background context and latent target identity features are synergetically fused by a Masked Autoencoder in the TIRM to reconstruct the target face. We evaluate DFREC on six different high-fidelity face-swapping attacks on FaceForensics++, CelebaMegaFS and FFHQ-E4S datasets, which demonstrate its superior recovery performance over state-of-the-art deepfake recovery algorithms. In addition, DFREC is the only scheme that can recover both pristine source and target faces directly from the forgery image with high fadelity.
Hierarchical Invariance for Robust and Interpretable Vision Tasks at Larger Scales
Feb 23, 2024
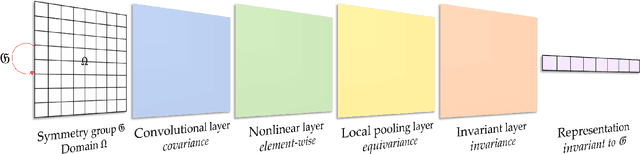
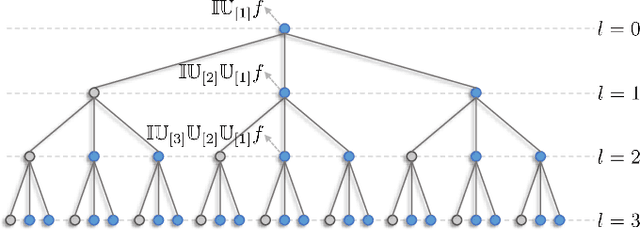
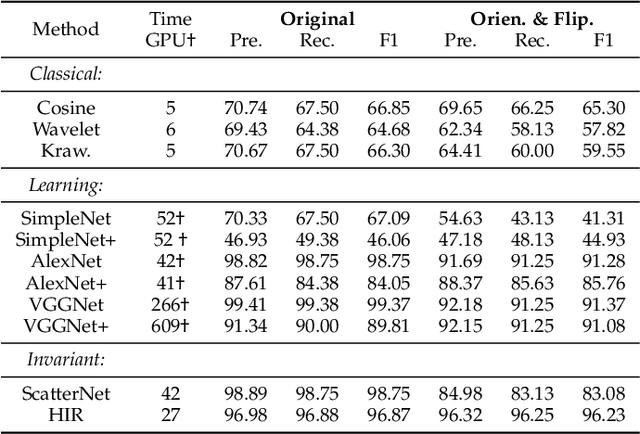
Developing robust and interpretable vision systems is a crucial step towards trustworthy artificial intelligence. In this regard, a promising paradigm considers embedding task-required invariant structures, e.g., geometric invariance, in the fundamental image representation. However, such invariant representations typically exhibit limited discriminability, limiting their applications in larger-scale trustworthy vision tasks. For this open problem, we conduct a systematic investigation of hierarchical invariance, exploring this topic from theoretical, practical, and application perspectives. At the theoretical level, we show how to construct over-complete invariants with a Convolutional Neural Networks (CNN)-like hierarchical architecture yet in a fully interpretable manner. The general blueprint, specific definitions, invariant properties, and numerical implementations are provided. At the practical level, we discuss how to customize this theoretical framework into a given task. With the over-completeness, discriminative features w.r.t. the task can be adaptively formed in a Neural Architecture Search (NAS)-like manner. We demonstrate the above arguments with accuracy, invariance, and efficiency results on texture, digit, and parasite classification experiments. Furthermore, at the application level, our representations are explored in real-world forensics tasks on adversarial perturbations and Artificial Intelligence Generated Content (AIGC). Such applications reveal that the proposed strategy not only realizes the theoretically promised invariance, but also exhibits competitive discriminability even in the era of deep learning. For robust and interpretable vision tasks at larger scales, hierarchical invariant representation can be considered as an effective alternative to traditional CNN and invariants.
Robust Retraining-free GAN Fingerprinting via Personalized Normalization
Nov 09, 2023In recent years, there has been significant growth in the commercial applications of generative models, licensed and distributed by model developers to users, who in turn use them to offer services. In this scenario, there is a need to track and identify the responsible user in the presence of a violation of the license agreement or any kind of malicious usage. Although there are methods enabling Generative Adversarial Networks (GANs) to include invisible watermarks in the images they produce, generating a model with a different watermark, referred to as a fingerprint, for each user is time- and resource-consuming due to the need to retrain the model to include the desired fingerprint. In this paper, we propose a retraining-free GAN fingerprinting method that allows model developers to easily generate model copies with the same functionality but different fingerprints. The generator is modified by inserting additional Personalized Normalization (PN) layers whose parameters (scaling and bias) are generated by two dedicated shallow networks (ParamGen Nets) taking the fingerprint as input. A watermark decoder is trained simultaneously to extract the fingerprint from the generated images. The proposed method can embed different fingerprints inside the GAN by just changing the input of the ParamGen Nets and performing a feedforward pass, without finetuning or retraining. The performance of the proposed method in terms of robustness against both model-level and image-level attacks is also superior to the state-of-the-art.