 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHEAT: A Large-scale Dataset for Detecting ChatGPT-writtEn AbsTracts
Paper and Code
Apr 24, 2023

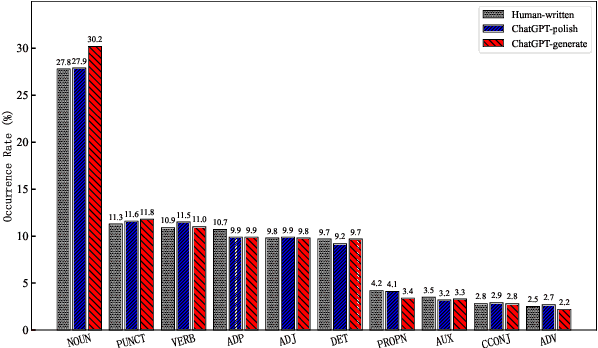
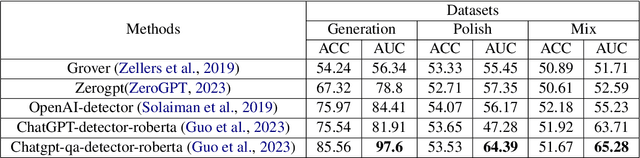
The powerful ability of ChatGPT has caused widespread concern in the academic community. Malicious users could synthesize dummy academic content through ChatGPT, which is extremely harmful to academic rigor and originality. The need to develop ChatGPT-written content detection algorithms call for large-scale datasets. In this paper, we initially investigate the possible negative impact of ChatGPT on academia,and present a large-scale CHatGPT-writtEn AbsTract dataset (CHEAT) to support the development of detection algorithms. In particular, the ChatGPT-written abstract dataset contains 35,304 synthetic abstracts, with Generation, Polish, and Mix as prominent representatives. Based on these data, we perform a thorough analysis of the existing text synthesis detection algorithms. We show that ChatGPT-written abstracts are detectable, while the detection difficulty increases with human involvement.