 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2PO: Diagnosing and Disentangling Bias Shortcuts in LLMs
Dec 29, 2025Bias in Large Language Models (LLMs) poses significant risks to trustworthiness, manifesting primarily as stereotypical biases (e.g., gender or racial stereotypes) and structural biases (e.g., lexical overlap or position preferences). However, prior paradigms typically address these in isolation, often mitigating one at the expense of exacerbating the other. To address this, we conduct a systematic exploration of these reasoning failures and identify a primary inducement: the latent spurious feature correlations within the input that drive these erroneous reasoning shortcuts. Driven by these findings, we introduce Causal-Contrastive Preference Optimization (C2PO), a unified alignment framework designed to tackle these specific failures by simultaneously discovering and suppressing these correlations directly within the optimization process. Specifically, C2PO leverages causal counterfactual signals to isolate bias-inducing features from valid reasoning paths, and employs a fairness-sensitive preference update mechanism to dynamically evaluate logit-level contributions and suppress shortcut features. Extensive experiments across multiple benchmarks covering stereotypical bias (BBQ, Unqover), structural bias (MNLI, HANS, Chatbot, MT-Bench), out-of-domain fairness (StereoSet, WinoBias), and general utility (MMLU, GSM8K) demonstrate that C2PO effectively mitigates stereotypical and structural biases while preserving robust general reasoning capabilities.
CLIP-FTI: Fine-Grained Face Template Inversion via CLIP-Driven Attribute Conditioning
Dec 17, 2025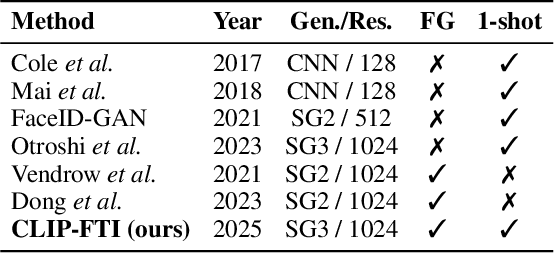
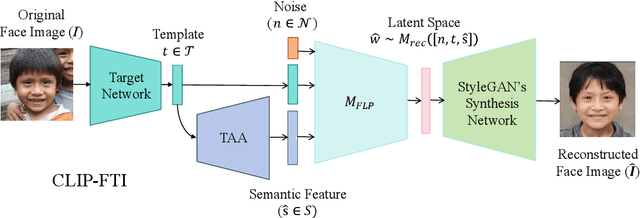
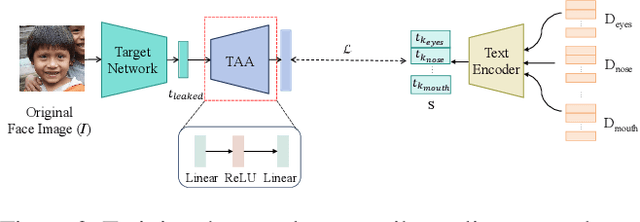
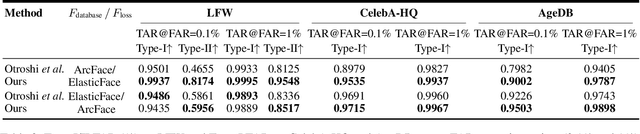
Face recognition systems store face templates for efficient matching. Once leaked, these templates pose a threat: inverting them can yield photorealistic surrogates that compromise privacy and enable impersonation. Although existing research has achieved relatively realistic face template inversion, the reconstructed facial images exhibit over-smoothed facial-part attributes (eyes, nose, mouth) and limited transferability. To address this problem, we present CLIP-FTI, a CLIP-driven fine-grained attribute conditioning framework for face template inversion. Our core idea is to use the CLIP model to obtain the semantic embeddings of facial features, in order to realize the reconstruction of specific facial feature attributes. Specifically, facial feature attribute embeddings extracted from CLIP are fused with the leaked template via a cross-modal feature interaction network and projected into the intermediate latent space of a pretrained StyleGAN. The StyleGAN generator then synthesizes face images with the same identity as the templates but with more fine-grained facial feature attributes. Experiments across multiple face recognition backbones and datasets show that our reconstructions (i) achieve higher identification accuracy and attribute similarity, (ii) recover sharper component-level attribute semantics, and (iii) improve cross-model attack transferability compared to prior reconstruction attacks. To the best of our knowledge, ours is the first method to use additional information besides the face template attack to realize face template inversion and obtains SOTA results.
Fine-Grained DINO Tuning with Dual Supervision for Face Forgery Detection
Nov 15, 2025The proliferation of sophisticated deepfakes poses significant threats to information integrity. While DINOv2 shows promise for detection, existing fine-tuning approaches treat it as generic binary classification, overlooking distinct artifacts inherent to different deepfake methods. To address this, we propose a DeepFake Fine-Grained Adapter (DFF-Adapter) for DINOv2. Our method incorporates lightweight multi-head LoRA modules into every transformer block, enabling efficient backbone adaptation. DFF-Adapter simultaneously addresses authenticity detection and fine-grained manipulation type classification, where classifying forgery methods enhances artifact sensitivity. We introduce a shared branch propagating fine-grained manipulation cues to the authenticity head. This enables multi-task cooperative optimization, explicitly enhancing authenticity discrimination with manipulation-specific knowledge. Utilizing only 3.5M trainable parameters, our parameter-efficient approach achieves detection accuracy comparable to or even surpassing that of current complex state-of-the-art methods.
Unlocking the Capabilities of Vision-Language Models for Generalizable and Explainable Deepfake Detection
Mar 19, 2025Current vision-language models (VLMs) have demonstrated remarkable capabilities in understanding multimodal data, but their potential remains underexplored for deepfake detection due to the misaligned of their knowledge and forensics patterns. To this end, we present a novel paradigm that unlocks VLMs' potential capabilities through three components: (1) A knowledge-guided forgery adaptation module that aligns VLM's semantic space with forensic features through contrastive learning with external manipulation knowledge; (2) A multi-modal prompt tuning framework that jointly optimizes visual-textual embeddings for both localization and explainability; (3) An iterative refinement strategy enabling multi-turn dialog for evidence-based reasoning. Our framework includes a VLM-based Knowledge-guided Forgery Detector (KFD), a VLM image encoder, and a Large Language Model (LLM). The VLM image encoder extracts visual prompt embeddings from images, while the LLM receives visual and question prompt embeddings for inference. The KFD is used to calculate correlations between image features and pristine/deepfake class embeddings, enabling forgery classification and localization. The outputs from these components are used to construct forgery prompt embeddings. Finally, we feed these prompt embeddings into the LLM to generate textual detection responses to assist judgment. Extensive experiments on multiple benchmarks, including FF++, CDF2, DFD, DFDCP, and DFDC, demonstrate that our scheme surpasses state-of-the-art methods in generalization performance, while also supporting multi-turn dialogue capabilities.
DFREC: DeepFake Identity Recovery Based on Identity-aware Masked Autoencoder
Dec 10, 2024Recent advances in deepfake forensics have primarily focused on improving the classification accuracy and generalization performance. Despite enormous progress in detection accuracy across a wide variety of forgery algorithms, existing algorithms lack intuitive interpretability and identity traceability to help with forensic investigation. In this paper, we introduce a novel DeepFake Identity Recovery scheme (DFREC) to fill this gap. DFREC aims to recover the pair of source and target faces from a deepfake image to facilitate deepfake identity tracing and reduce the risk of deepfake attack. It comprises three key components: an Identity Segmentation Module (ISM), a Source Identity Reconstruction Module (SIRM), and a Target Identity Reconstruction Module (TIRM). The ISM segments the input face into distinct source and target face information, and the SIRM reconstructs the source face and extracts latent target identity features with the segmented source information. The background context and latent target identity features are synergetically fused by a Masked Autoencoder in the TIRM to reconstruct the target face. We evaluate DFREC on six different high-fidelity face-swapping attacks on FaceForensics++, CelebaMegaFS and FFHQ-E4S datasets, which demonstrate its superior recovery performance over state-of-the-art deepfake recovery algorithms. In addition, DFREC is the only scheme that can recover both pristine source and target faces directly from the forgery image with high fadelity.
CHEAT: A Large-scale Dataset for Detecting ChatGPT-writtEn AbsTracts
Apr 24, 2023

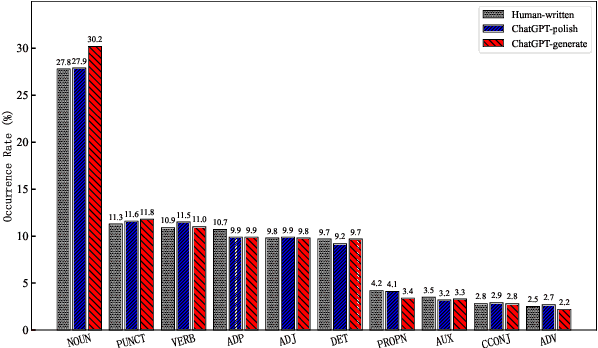
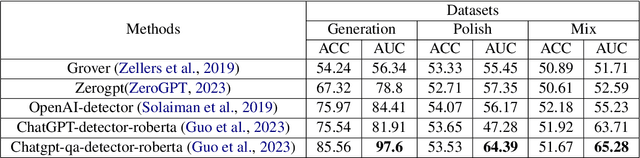
The powerful ability of ChatGPT has caused widespread concern in the academic community. Malicious users could synthesize dummy academic content through ChatGPT, which is extremely harmful to academic rigor and originality. The need to develop ChatGPT-written content detection algorithms call for large-scale datasets. In this paper, we initially investigate the possible negative impact of ChatGPT on academia,and present a large-scale CHatGPT-writtEn AbsTract dataset (CHEAT) to support the development of detection algorithms. In particular, the ChatGPT-written abstract dataset contains 35,304 synthetic abstracts, with Generation, Polish, and Mix as prominent representatives. Based on these data, we perform a thorough analysis of the existing text synthesis detection algorithms. We show that ChatGPT-written abstracts are detectable, while the detection difficulty increases with human involvement.
Learning Second Order Local Anomaly for General Face Forgery Detection
Sep 30, 2022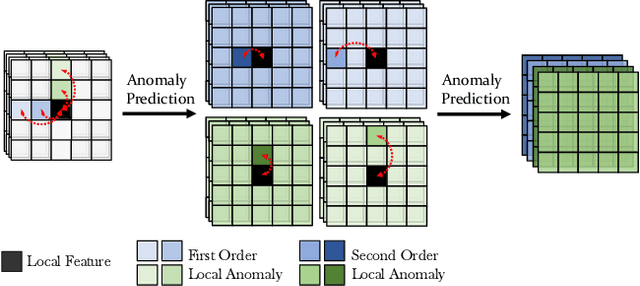
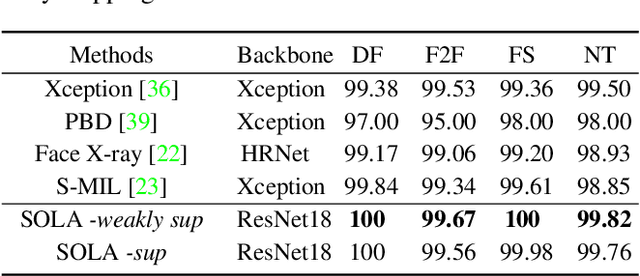
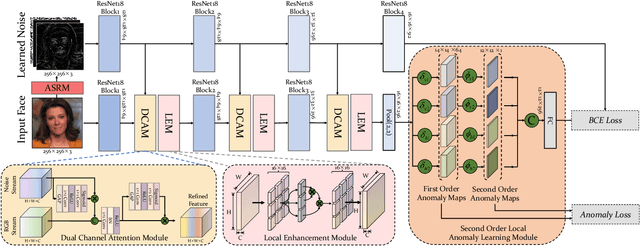
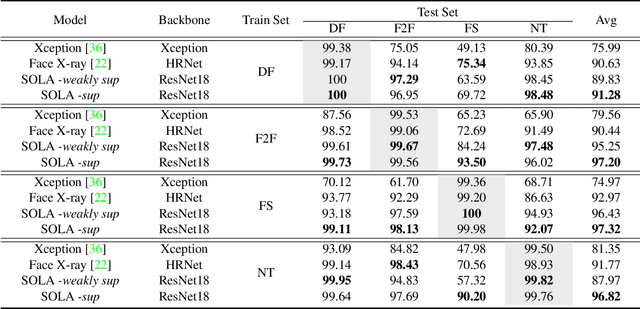
In this work, we propose a novel method to improve the generalization ability of CNN-based face forgery detectors. Our method considers the feature anomalies of forged faces caused by the prevalent blending operations in face forgery algorithms. Specifically, we propose a weakly supervised Second Order Local Anomaly (SOLA) learning module to mine anomalies in local regions using deep feature maps. SOLA first decomposes the neighborhood of local features by different directions and distances and then calculates the first and second order local anomaly maps which provide more general forgery traces for the classifier. We also propose a Local Enhancement Module (LEM) to improve the discrimination between local features of real and forged regions, so as to ensure accuracy in calculating anomalies. Besides, an improved Adaptive Spatial Rich Model (ASRM) is introduced to help mine subtle noise features via learnable high pass filters. With neither pixel level annotations nor external synthetic data, our method using a simple ResNet18 backbone achieves competitive performances compared with state-of-the-art works when evaluated on unseen forgeries.