 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Propagation Transformer for Graph Representation Learning
May 19, 2023



This paper presents a novel transformer architecture for graph representation learning. The core insight of our method is to fully consider the information propagation among nodes and edges in a graph when building the attention module in the transformer blocks. Specifically, we propose a new attention mechanism called Graph Propagation Attention (GPA). It explicitly passes the information among nodes and edges in three ways, i.e. node-to-node, node-to-edge, and edge-to-node, which is essential for learning graph-structured data. On this basis, we design an effective transformer architecture named Graph Propagation Transformer (GPTrans) to further help learn graph data. We verify the performance of GPTrans in a wide range of graph learning experiments on several benchmark datasets. These results show that our method outperforms many state-of-the-art transformer-based graph models with better performance. The code will be released at https://github.com/czczup/GPTrans.
Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method
Dec 22, 2022



As the quality of optical sensors improves, there is a need for processing large-scale images. In particular, the ability of devices to capture ultra-high definition (UHD) images and video places new demands on the image processing pipeline. In this paper, we consider the task of low-light image enhancement (LLIE) and introduce a large-scale database consisting of images at 4K and 8K resolution. We conduct systematic benchmarking studies and provide a comparison of current LLIE algorithms. As a second contribution, we introduce LLFormer, a transformer-based low-light enhancement method. The core components of LLFormer are the axis-based multi-head self-attention and cross-layer attention fusion block, which significantly reduces the linear complexity. Extensive experiments on the new dataset and existing public datasets show that LLFormer outperforms state-of-the-art methods. We also show that employing existing LLIE methods trained on our benchmark as a pre-processing step significantly improves the performance of downstream tasks, e.g., face detection in low-light conditions. The source code and pre-trained models are available at https://github.com/TaoWangzj/LLFormer.
Learning Second Order Local Anomaly for General Face Forgery Detection
Sep 30, 2022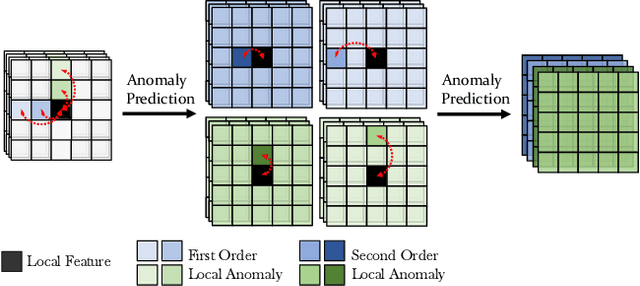
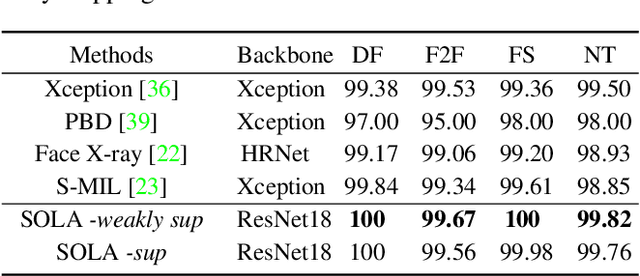
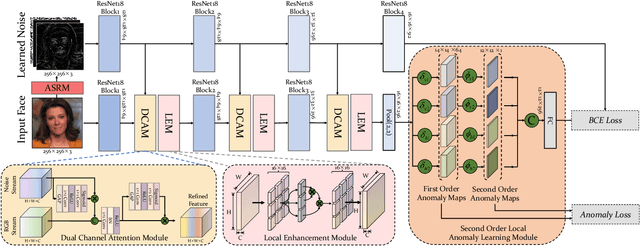
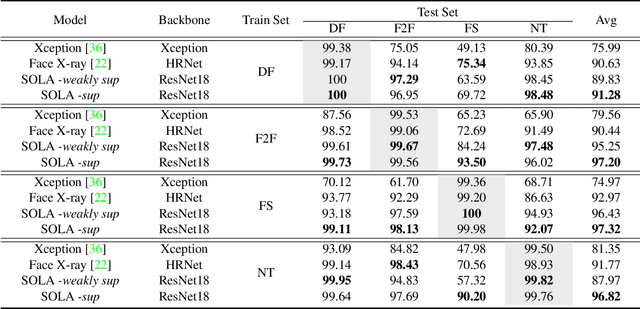
In this work, we propose a novel method to improve the generalization ability of CNN-based face forgery detectors. Our method considers the feature anomalies of forged faces caused by the prevalent blending operations in face forgery algorithms. Specifically, we propose a weakly supervised Second Order Local Anomaly (SOLA) learning module to mine anomalies in local regions using deep feature maps. SOLA first decomposes the neighborhood of local features by different directions and distances and then calculates the first and second order local anomaly maps which provide more general forgery traces for the classifier. We also propose a Local Enhancement Module (LEM) to improve the discrimination between local features of real and forged regions, so as to ensure accuracy in calculating anomalies. Besides, an improved Adaptive Spatial Rich Model (ASRM) is introduced to help mine subtle noise features via learnable high pass filters. With neither pixel level annotations nor external synthetic data, our method using a simple ResNet18 backbone achieves competitive performances compared with state-of-the-art works when evaluated on unseen forgeries.