 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniSH: Unifying Scene and Human Reconstruction in a Feed-Forward Pass
Jan 03, 2026We present UniSH, a unified, feed-forward framework for joint metric-scale 3D scene and human reconstruction. A key challenge in this domain is the scarcity of large-scale, annotated real-world data, forcing a reliance on synthetic datasets. This reliance introduces a significant sim-to-real domain gap, leading to poor generalization, low-fidelity human geometry, and poor alignment on in-the-wild videos. To address this, we propose an innovative training paradigm that effectively leverages unlabeled in-the-wild data. Our framework bridges strong, disparate priors from scene reconstruction and HMR, and is trained with two core components: (1) a robust distillation strategy to refine human surface details by distilling high-frequency details from an expert depth model, and (2) a two-stage supervision scheme, which first learns coarse localization on synthetic data, then fine-tunes on real data by directly optimizing the geometric correspondence between the SMPL mesh and the human point cloud. This approach enables our feed-forward model to jointly recover high-fidelity scene geometry, human point clouds, camera parameters, and coherent, metric-scale SMPL bodies, all in a single forward pass. Extensive experiments demonstrate that our model achieves state-of-the-art performance on human-centric scene reconstruction and delivers highly competitive results on global human motion estimation, comparing favorably against both optimization-based frameworks and HMR-only methods. Project page: https://murphylmf.github.io/UniSH/
Visual-Aware CoT: Achieving High-Fidelity Visual Consistency in Unified Models
Dec 22, 2025Recently, the introduction of Chain-of-Thought (CoT) has largely improved the generation ability of unified models. However, it is observed that the current thinking process during generation mainly focuses on the text consistency with the text prompt, ignoring the \textbf{visual context consistency} with the visual reference images during the multi-modal generation, e.g., multi-reference generation. The lack of such consistency results in the failure in maintaining key visual features (like human ID, object attribute, style). To this end, we integrate the visual context consistency into the reasoning of unified models, explicitly motivating the model to sustain such consistency by 1) Adaptive Visual Planning: generating structured visual check list to figure out the visual element of needed consistency keeping, and 2) Iterative Visual Correction: performing self-reflection with the guidance of check lists and refining the generated result in an iterative manner. To achieve this, we use supervised finetuning to teach the model how to plan the visual checking, conduct self-reflection and self-refinement, and use flow-GRPO to further enhance the visual consistency through a customized visual checking reward. The experiments show that our method outperforms both zero-shot unified models and those with text CoTs in multi-modal generation, demonstrating higher visual context consistency.
CogniEdit: Dense Gradient Flow Optimization for Fine-Grained Image Editing
Dec 15, 2025Instruction-based image editing with diffusion models has achieved impressive results, yet existing methods struggle with fine-grained instructions specifying precise attributes such as colors, positions, and quantities. While recent approaches employ Group Relative Policy Optimization (GRPO) for alignment, they optimize only at individual sampling steps, providing sparse feedback that limits trajectory-level control. We propose a unified framework CogniEdit, combining multi-modal reasoning with dense reward optimization that propagates gradients across consecutive denoising steps, enabling trajectory-level gradient flow through the sampling process. Our method comprises three components: (1) Multi-modal Large Language Models for decomposing complex instructions into actionable directives, (2) Dynamic Token Focus Relocation that adaptively emphasizes fine-grained attributes, and (3) Dense GRPO-based optimization that propagates gradients across consecutive steps for trajectory-level supervision. Extensive experiments on benchmark datasets demonstrate that our CogniEdit achieves state-of-the-art performance in balancing fine-grained instruction following with visual quality and editability preservation
ReViSE: Towards Reason-Informed Video Editing in Unified Models with Self-Reflective Learning
Dec 11, 2025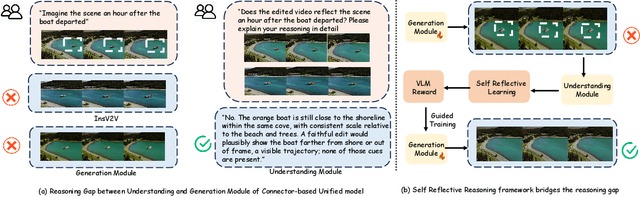
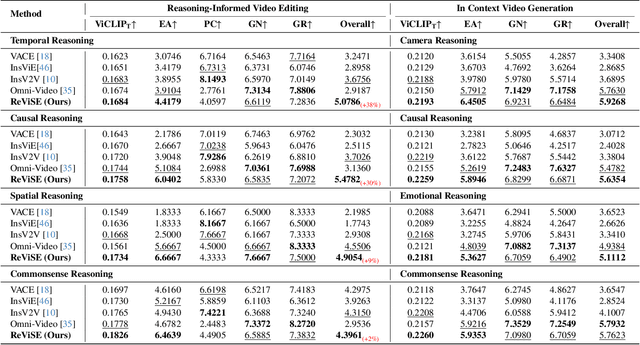

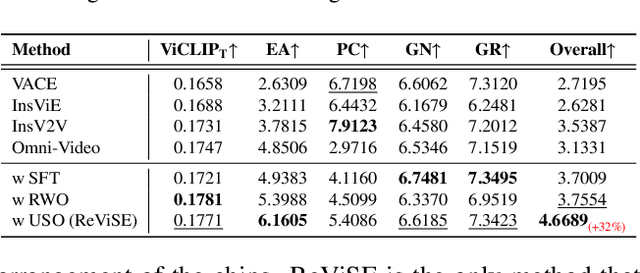
Video unified models exhibit strong capabilities in understanding and generation, yet they struggle with reason-informed visual editing even when equipped with powerful internal vision-language models (VLMs). We attribute this gap to two factors: 1) existing datasets are inadequate for training and evaluating reasoning-aware video editing, and 2) an inherent disconnect between the models' reasoning and editing capabilities, which prevents the rich understanding from effectively instructing the editing process. Bridging this gap requires an integrated framework that connects reasoning with visual transformation. To address this gap, we introduce the Reason-Informed Video Editing (RVE) task, which requires reasoning about physical plausibility and causal dynamics during editing. To support systematic evaluation, we construct RVE-Bench, a comprehensive benchmark with two complementary subsets: Reasoning-Informed Video Editing and In-Context Video Generation. These subsets cover diverse reasoning dimensions and real-world editing scenarios. Building upon this foundation, we propose the ReViSE, a Self-Reflective Reasoning (SRF) framework that unifies generation and evaluation within a single architecture. The model's internal VLM provides intrinsic feedback by assessing whether the edited video logically satisfies the given instruction. The differential feedback that refines the generator's reasoning behavior during training. Extensive experiments on RVE-Bench demonstrate that ReViSE significantly enhances editing accuracy and visual fidelity, achieving a 32% improvement of the Overall score in the reasoning-informed video editing subset over state-of-the-art methods.
InfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing
Aug 19, 2025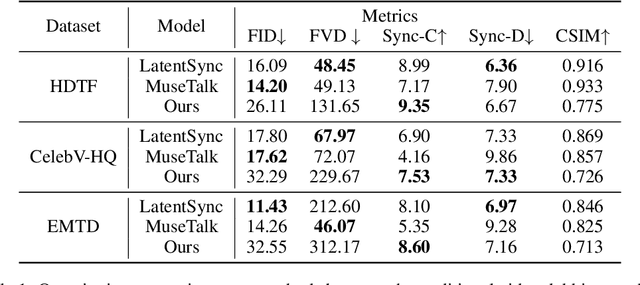

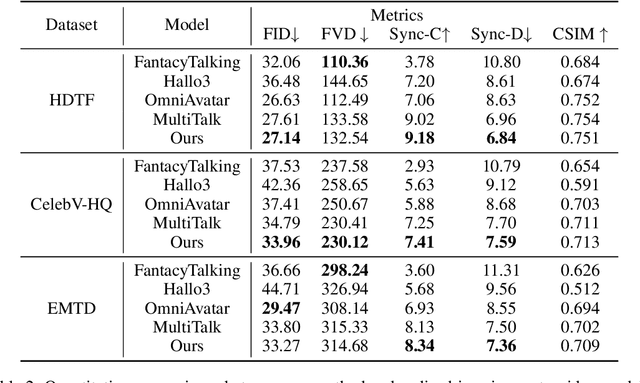
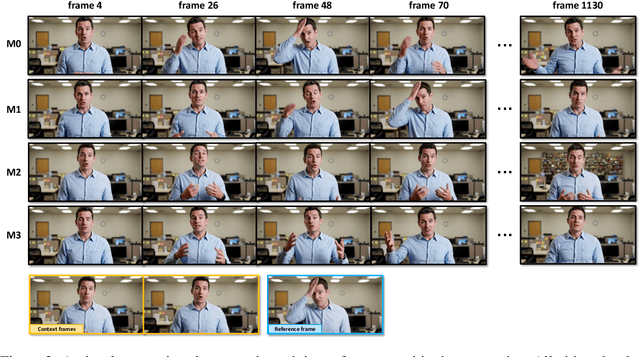
Recent breakthroughs in video AIGC have ushered in a transformative era for audio-driven human animation. However, conventional video dubbing techniques remain constrained to mouth region editing, resulting in discordant facial expressions and body gestures that compromise viewer immersion. To overcome this limitation, we introduce sparse-frame video dubbing, a novel paradigm that strategically preserves reference keyframes to maintain identity, iconic gestures, and camera trajectories while enabling holistic, audio-synchronized full-body motion editing. Through critical analysis, we identify why naive image-to-video models fail in this task, particularly their inability to achieve adaptive conditioning. Addressing this, we propose InfiniteTalk, a streaming audio-driven generator designed for infinite-length long sequence dubbing. This architecture leverages temporal context frames for seamless inter-chunk transitions and incorporates a simple yet effective sampling strategy that optimizes control strength via fine-grained reference frame positioning. Comprehensive evaluations on HDTF, CelebV-HQ, and EMTD datasets demonstrate state-of-the-art performance. Quantitative metrics confirm superior visual realism, emotional coherence, and full-body motion synchronization.
DocRefine: An Intelligent Framework for Scientific Document Understanding and Content Optimization based on Multimodal Large Model Agents
Aug 09, 2025The exponential growth of scientific literature in PDF format necessitates advanced tools for efficient and accurate document understanding, summarization, and content optimization. Traditional methods fall short in handling complex layouts and multimodal content, while direct application of Large Language Models (LLMs) and Vision-Language Large Models (LVLMs) lacks precision and control for intricate editing tasks. This paper introduces DocRefine, an innovative framework designed for intelligent understanding, content refinement, and automated summarization of scientific PDF documents, driven by natural language instructions. DocRefine leverages the power of advanced LVLMs (e.g., GPT-4o) by orchestrating a sophisticated multi-agent system comprising six specialized and collaborative agents: Layout & Structure Analysis, Multimodal Content Understanding, Instruction Decomposition, Content Refinement, Summarization & Generation, and Fidelity & Consistency Verification. This closed-loop feedback architecture ensures high semantic accuracy and visual fidelity. Evaluated on the comprehensive DocEditBench dataset, DocRefine consistently outperforms state-of-the-art baselines across various tasks, achieving overall scores of 86.7% for Semantic Consistency Score (SCS), 93.9% for Layout Fidelity Index (LFI), and 85.0% for Instruction Adherence Rate (IAR). These results demonstrate DocRefine's superior capability in handling complex multimodal document editing, preserving semantic integrity, and maintaining visual consistency, marking a significant advancement in automated scientific document processing.
DAM-VSR: Disentanglement of Appearance and Motion for Video Super-Resolution
Jul 01, 2025


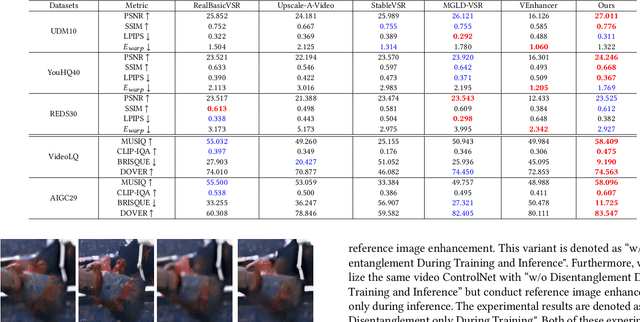
Real-world video super-resolution (VSR) presents significant challenges due to complex and unpredictable degradations. Although some recent methods utilize image diffusion models for VSR and have shown improved detail generation capabilities, they still struggle to produce temporally consistent frames. We attempt to use Stable Video Diffusion (SVD) combined with ControlNet to address this issue. However, due to the intrinsic image-animation characteristics of SVD, it is challenging to generate fine details using only low-quality videos. To tackle this problem, we propose DAM-VSR, an appearance and motion disentanglement framework for VSR. This framework disentangles VSR into appearance enhancement and motion control problems. Specifically, appearance enhancement is achieved through reference image super-resolution, while motion control is achieved through video ControlNet. This disentanglement fully leverages the generative prior of video diffusion models and the detail generation capabilities of image super-resolution models. Furthermore, equipped with the proposed motion-aligned bidirectional sampling strategy, DAM-VSR can conduct VSR on longer input videos. DAM-VSR achieves state-of-the-art performance on real-world data and AIGC data, demonstrating its powerful detail generation capabilities.
UNIC: Unified In-Context Video Editing
Jun 04, 2025

Recent advances in text-to-video generation have sparked interest in generative video editing tasks. Previous methods often rely on task-specific architectures (e.g., additional adapter modules) or dedicated customizations (e.g., DDIM inversion), which limit the integration of versatile editing conditions and the unification of various editing tasks. In this paper, we introduce UNified In-Context Video Editing (UNIC), a simple yet effective framework that unifies diverse video editing tasks within a single model in an in-context manner. To achieve this unification, we represent the inputs of various video editing tasks as three types of tokens: the source video tokens, the noisy video latent, and the multi-modal conditioning tokens that vary according to the specific editing task. Based on this formulation, our key insight is to integrate these three types into a single consecutive token sequence and jointly model them using the native attention operations of DiT, thereby eliminating the need for task-specific adapter designs. Nevertheless, direct task unification under this framework is challenging, leading to severe token collisions and task confusion due to the varying video lengths and diverse condition modalities across tasks. To address these, we introduce task-aware RoPE to facilitate consistent temporal positional encoding, and condition bias that enables the model to clearly differentiate different editing tasks. This allows our approach to adaptively perform different video editing tasks by referring the source video and varying condition tokens "in context", and support flexible task composition. To validate our method, we construct a unified video editing benchmark containing six representative video editing tasks. Results demonstrate that our unified approach achieves superior performance on each task and exhibits emergent task composition abilities.
Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation
May 28, 2025



Audio-driven human animation methods, such as talking head and talking body generation, have made remarkable progress in generating synchronized facial movements and appealing visual quality videos. However, existing methods primarily focus on single human animation and struggle with multi-stream audio inputs, facing incorrect binding problems between audio and persons. Additionally, they exhibit limitations in instruction-following capabilities. To solve this problem, in this paper, we propose a novel task: Multi-Person Conversational Video Generation, and introduce a new framework, MultiTalk, to address the challenges during multi-person generation. Specifically, for audio injection, we investigate several schemes and propose the Label Rotary Position Embedding (L-RoPE) method to resolve the audio and person binding problem. Furthermore, during training, we observe that partial parameter training and multi-task training are crucial for preserving the instruction-following ability of the base model. MultiTalk achieves superior performance compared to other methods on several datasets, including talking head, talking body, and multi-person datasets, demonstrating the powerful generation capabilities of our approach.
LlamaSeg: Image Segmentation via Autoregressive Mask Generation
May 26, 2025We present LlamaSeg, a visual autoregressive framework that unifies multiple image segmentation tasks via natural language instructions. We reformulate image segmentation as a visual generation problem, representing masks as "visual" tokens and employing a LLaMA-style Transformer to predict them directly from image inputs. By adhering to the next-token prediction paradigm, our approach naturally integrates segmentation tasks into autoregressive architectures. To support large-scale training, we introduce a data annotation pipeline and construct the SA-OVRS dataset, which contains 2M segmentation masks annotated with over 5,800 open-vocabulary labels or diverse textual descriptions, covering a wide spectrum of real-world scenarios. This enables our model to localize objects in images based on text prompts and to generate fine-grained masks. To more accurately evaluate the quality of masks produced by visual generative models, we further propose a composite metric that combines Intersection over Union (IoU) with Average Hausdorff Distance (AHD), offering a more precise assessment of contour fidelity. Experimental results demonstrate that our method surpasses existing generative models across multiple datasets and yields more detailed segmentation masks.