 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAM-VSR: Disentanglement of Appearance and Motion for Video Super-Resolution
Jul 01, 2025


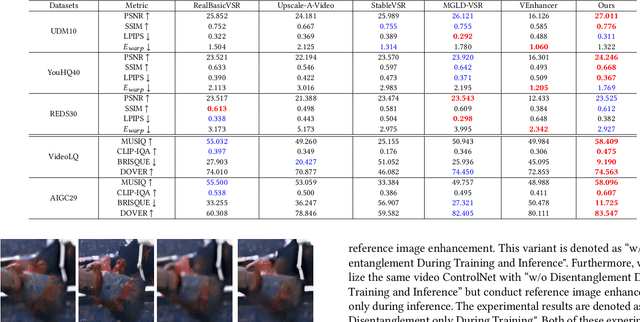
Real-world video super-resolution (VSR) presents significant challenges due to complex and unpredictable degradations. Although some recent methods utilize image diffusion models for VSR and have shown improved detail generation capabilities, they still struggle to produce temporally consistent frames. We attempt to use Stable Video Diffusion (SVD) combined with ControlNet to address this issue. However, due to the intrinsic image-animation characteristics of SVD, it is challenging to generate fine details using only low-quality videos. To tackle this problem, we propose DAM-VSR, an appearance and motion disentanglement framework for VSR. This framework disentangles VSR into appearance enhancement and motion control problems. Specifically, appearance enhancement is achieved through reference image super-resolution, while motion control is achieved through video ControlNet. This disentanglement fully leverages the generative prior of video diffusion models and the detail generation capabilities of image super-resolution models. Furthermore, equipped with the proposed motion-aligned bidirectional sampling strategy, DAM-VSR can conduct VSR on longer input videos. DAM-VSR achieves state-of-the-art performance on real-world data and AIGC data, demonstrating its powerful detail generation capabilities.
Empowering Economic Simulation for Massively Multiplayer Online Games through Generative Agent-Based Modeling
Jun 05, 2025Within the domain of Massively Multiplayer Online (MMO) economy research, Agent-Based Modeling (ABM) has emerged as a robust tool for analyzing game economics, evolving from rule-based agents to decision-making agents enhanced by reinforcement learning. Nevertheless, existing works encounter significant challenges when attempting to emulate human-like economic activities among agents, particularly regarding agent reliability, sociability, and interpretability. In this study, we take a preliminary step in introducing a novel approach using Large Language Models (LLMs) in MMO economy simulation. Leveraging LLMs' role-playing proficiency, generative capacity, and reasoning aptitude, we design LLM-driven agents with human-like decision-making and adaptability. These agents are equipped with the abilities of role-playing, perception, memory, and reasoning, addressing the aforementioned challenges effectively. Simulation experiments focusing on in-game economic activities demonstrate that LLM-empowered agents can promote emergent phenomena like role specialization and price fluctuations in line with market rules.
Digital Player: Evaluating Large Language Models based Human-like Agent in Games
Feb 28, 2025With the rapid advancement of Large Language Models (LLMs), LLM-based autonomous agents have shown the potential to function as digital employees, such as digital analysts, teachers, and programmers. In this paper, we develop an application-level testbed based on the open-source strategy game "Unciv", which has millions of active players, to enable researchers to build a "data flywheel" for studying human-like agents in the "digital players" task. This "Civilization"-like game features expansive decision-making spaces along with rich linguistic interactions such as diplomatic negotiations and acts of deception, posing significant challenges for LLM-based agents in terms of numerical reasoning and long-term planning. Another challenge for "digital players" is to generate human-like responses for social interaction, collaboration, and negotiation with human players. The open-source project can be found at https:/github.com/fuxiAIlab/CivAgent.
Batch-in-Batch: a new adversarial training framework for initial perturbation and sample selection
Jun 06, 2024Adversarial training methods commonly generate independent initial perturbation for adversarial samples from a simple uniform distribution, and obtain the training batch for the classifier without selection. In this work, we propose a simple yet effective training framework called Batch-in-Batch (BB) to enhance models robustness. It involves specifically a joint construction of initial values that could simultaneously generates $m$ sets of perturbations from the original batch set to provide more diversity for adversarial samples; and also includes various sample selection strategies that enable the trained models to have smoother losses and avoid overconfident outputs. Through extensive experiments on three benchmark datasets (CIFAR-10, SVHN, CIFAR-100) with two networks (PreActResNet18 and WideResNet28-10) that are used in both the single-step (Noise-Fast Gradient Sign Method, N-FGSM) and multi-step (Projected Gradient Descent, PGD-10) adversarial training, we show that models trained within the BB framework consistently have higher adversarial accuracy across various adversarial settings, notably achieving over a 13% improvement on the SVHN dataset with an attack radius of 8/255 compared to the N-FGSM baseline model. Furthermore, experimental analysis of the efficiency of both the proposed initial perturbation method and sample selection strategies validates our insights. Finally, we show that our framework is cost-effective in terms of computational resources, even with a relatively large value of $m$.
Reprint: a randomized extrapolation based on principal components for data augmentation
Apr 26, 2022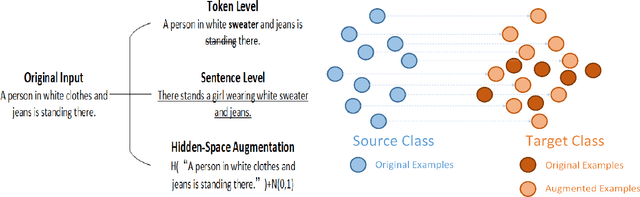
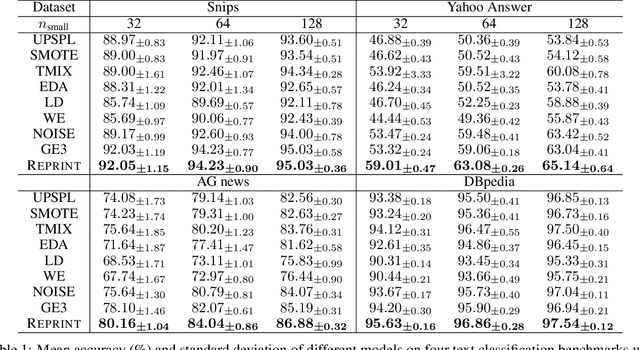
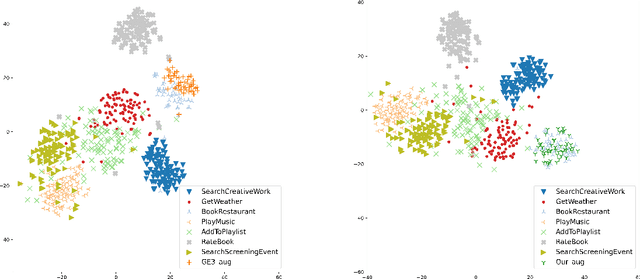

Data scarcity and data imbalance have attracted a lot of attention in many fields. Data augmentation, explored as an effective approach to tackle them, can improve the robustness and efficiency of classification models by generating new samples. This paper presents REPRINT, a simple and effective hidden-space data augmentation method for imbalanced data classification. Given hidden-space representations of samples in each class, REPRINT extrapolates, in a randomized fashion, augmented examples for target class by using subspaces spanned by principal components to summarize distribution structure of both source and target class. Consequently, the examples generated would diversify the target while maintaining the original geometry of target distribution. Besides, this method involves a label refinement component which allows to synthesize new soft labels for augmented examples. Compared with different NLP data augmentation approaches under a range of data imbalanced scenarios on four text classification benchmark, REPRINT shows prominent improvements. Moreover, through comprehensive ablation studies, we show that label refinement is better than label-preserving for augmented examples, and that our method suggests stable and consistent improvements in terms of suitable choices of principal components. Moreover, REPRINT is appealing for its easy-to-use since it contains only one hyperparameter determining the dimension of subspace and requires low computational resource.
Youling: an AI-Assisted Lyrics Creation System
Jan 18, 2022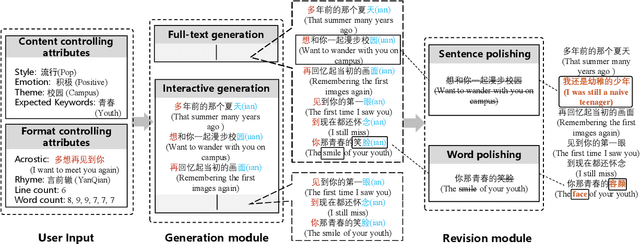
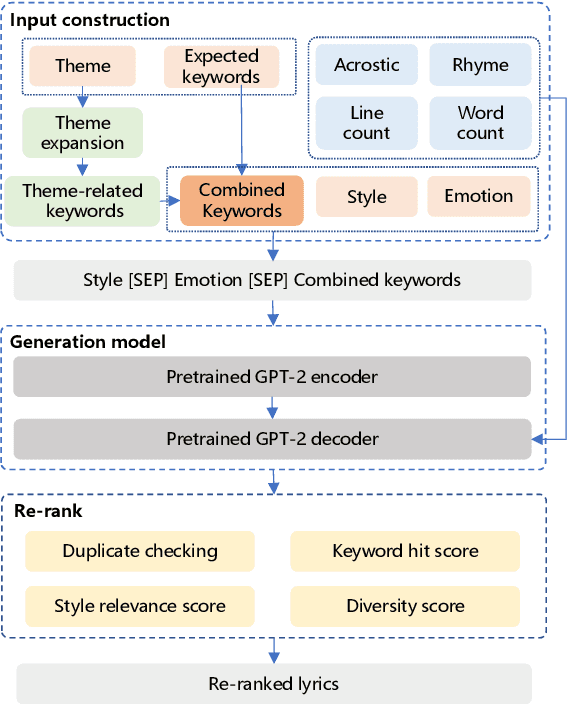
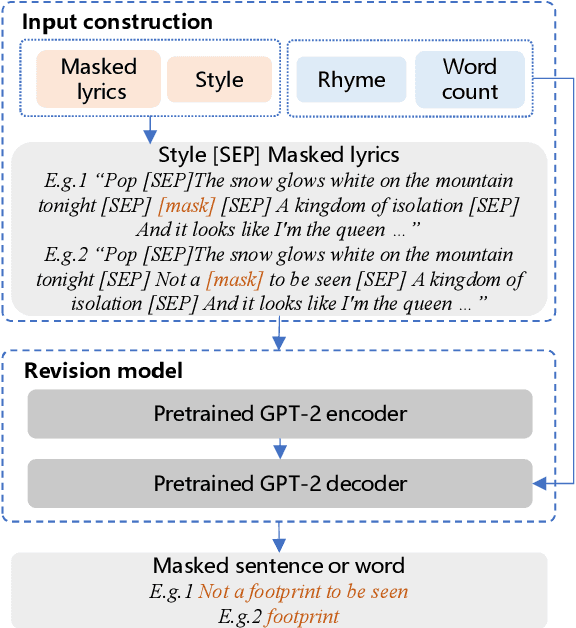
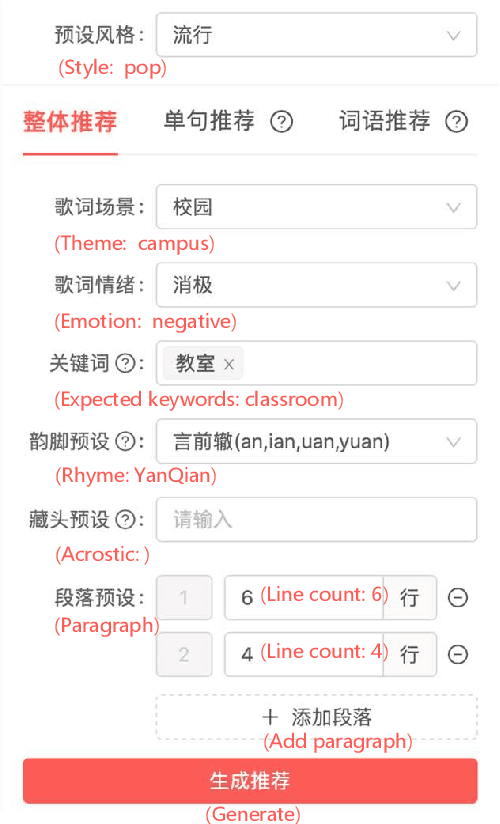
Recently, a variety of neural models have been proposed for lyrics generation. However, most previous work completes the generation process in a single pass with little human intervention. We believe that lyrics creation is a creative process with human intelligence centered. AI should play a role as an assistant in the lyrics creation process, where human interactions are crucial for high-quality creation. This paper demonstrates \textit{Youling}, an AI-assisted lyrics creation system, designed to collaborate with music creators. In the lyrics generation process, \textit{Youling} supports traditional one pass full-text generation mode as well as an interactive generation mode, which allows users to select the satisfactory sentences from generated candidates conditioned on preceding context. The system also provides a revision module which enables users to revise undesired sentences or words of lyrics repeatedly. Besides, \textit{Youling} allows users to use multifaceted attributes to control the content and format of generated lyrics. The demo video of the system is available at https://youtu.be/DFeNpHk0pm4.
Joint Face Completion and Super-resolution using Multi-scale Feature Relation Learning
Feb 29, 2020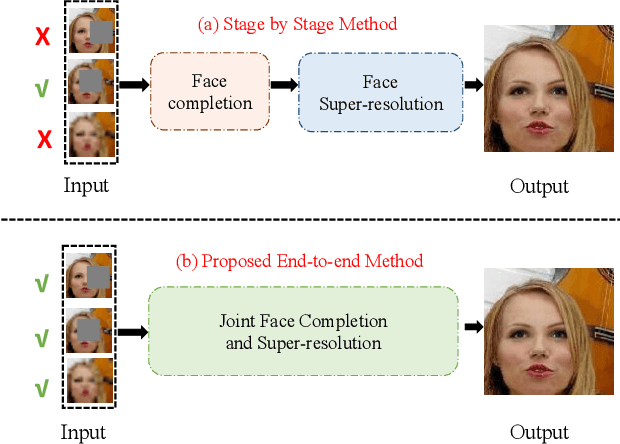
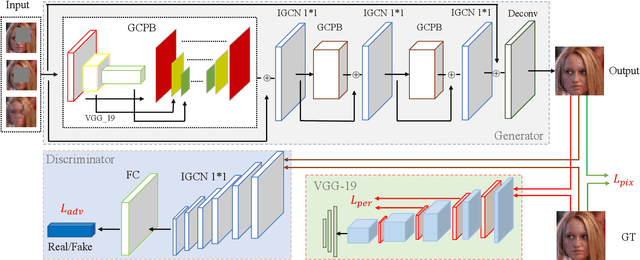
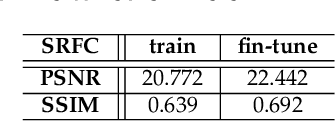
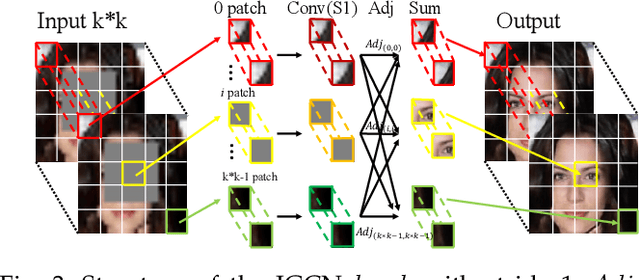
Previous research on face restoration often focused on repairing a specific type of low-quality facial images such as low-resolution (LR) or occluded facial images. However, in the real world, both the above-mentioned forms of image degradation often coexist. Therefore, it is important to design a model that can repair LR occluded images simultaneously. This paper proposes a multi-scale feature graph generative adversarial network (MFG-GAN) to implement the face restoration of images in which both degradation modes coexist, and also to repair images with a single type of degradation. Based on the GAN, the MFG-GAN integrates the graph convolution and feature pyramid network to restore occluded low-resolution face images to non-occluded high-resolution face images. The MFG-GAN uses a set of customized losses to ensure that high-quality images are generated. In addition, we designed the network in an end-to-end format. Experimental results on the public-domain CelebA and Helen databases show that the proposed approach outperforms state-of-the-art methods in performing face super-resolution (up to 4x or 8x) and face completion simultaneously. Cross-database testing also revealed that the proposed approach has good generalizability.
Controllable Descendant Face Synthesis
Feb 26, 2020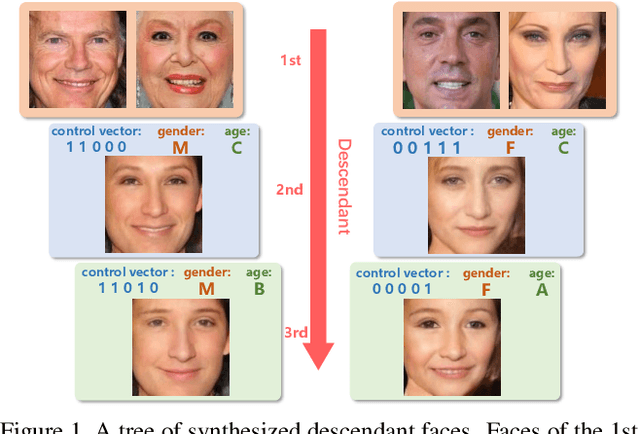
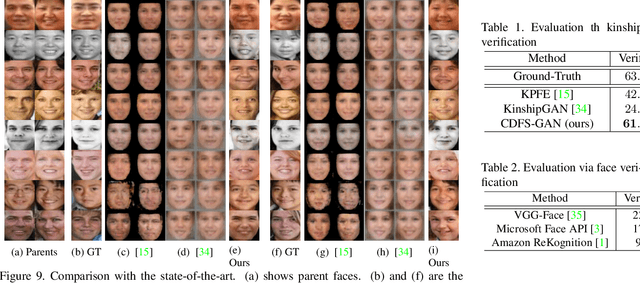


Kinship face synthesis is an interesting topic raised to answer questions like "what will your future children look like?". Published approaches to this topic are limited. Most of the existing methods train models for one-versus-one kin relation, which only consider one parent face and one child face by directly using an auto-encoder without any explicit control over the resemblance of the synthesized face to the parent face. In this paper, we propose a novel method for controllable descendant face synthesis, which models two-versus-one kin relation between two parent faces and one child face. Our model consists of an inheritance module and an attribute enhancement module, where the former is designed for accurate control over the resemblance between the synthesized face and parent faces, and the latter is designed for control over age and gender. As there is no large scale database with father-mother-child kinship annotation, we propose an effective strategy to train the model without using the ground truth descendant faces. No carefully designed image pairs are required for learning except only age and gender labels of training faces. We conduct comprehensive experimental evaluations on three public benchmark databases, which demonstrates encouraging results.
Facial Expression Restoration Based on Improved Graph Convolutional Networks
Oct 23, 2019
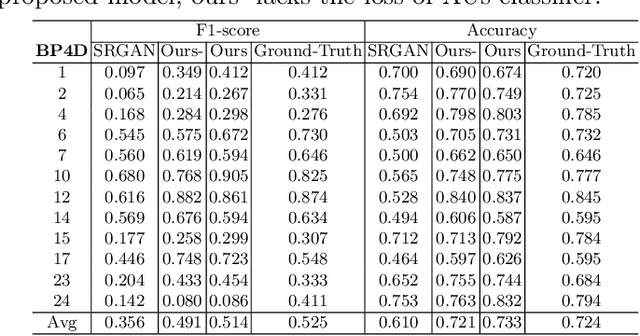
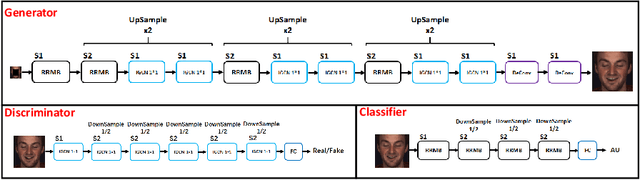

Facial expression analysis in the wild is challenging when the facial image is with low resolution or partial occlusion. Considering the correlations among different facial local regions under different facial expressions, this paper proposes a novel facial expression restoration method based on generative adversarial network by integrating an improved graph convolutional network (IGCN) and region relation modeling block (RRMB). Unlike conventional graph convolutional networks taking vectors as input features, IGCN can use tensors of face patches as inputs. It is better to retain the structure information of face patches. The proposed RRMB is designed to address facial generative tasks including inpainting and super-resolution with facial action units detection, which aims to restore facial expression as the ground-truth. Extensive experiments conducted on BP4D and DISFA benchmarks demonstrate the effectiveness of our proposed method through quantitative and qualitative evaluations.
A Quasi-Bayesian Perspective to Online Clustering
May 25, 2018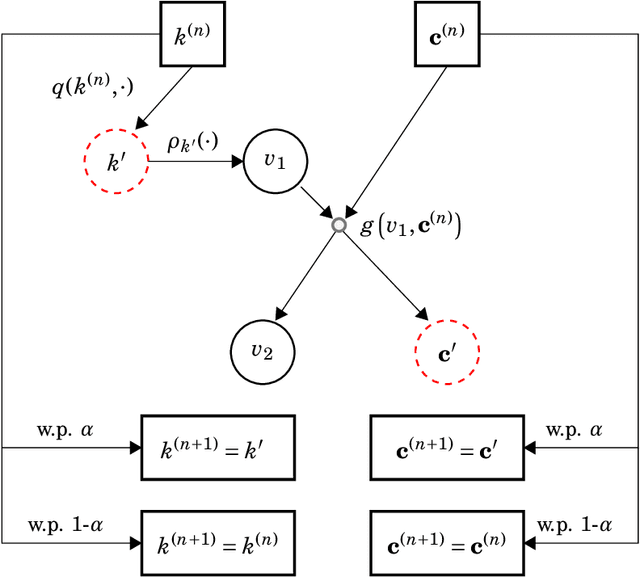
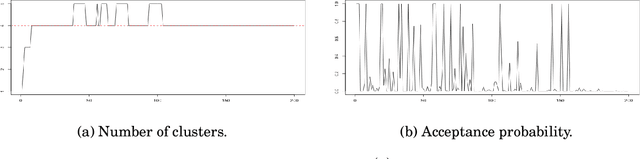
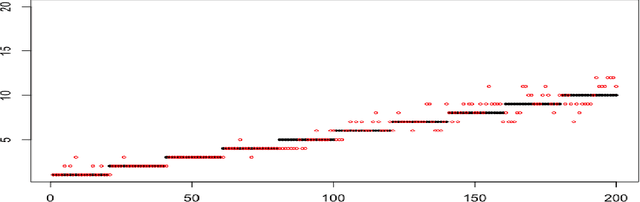
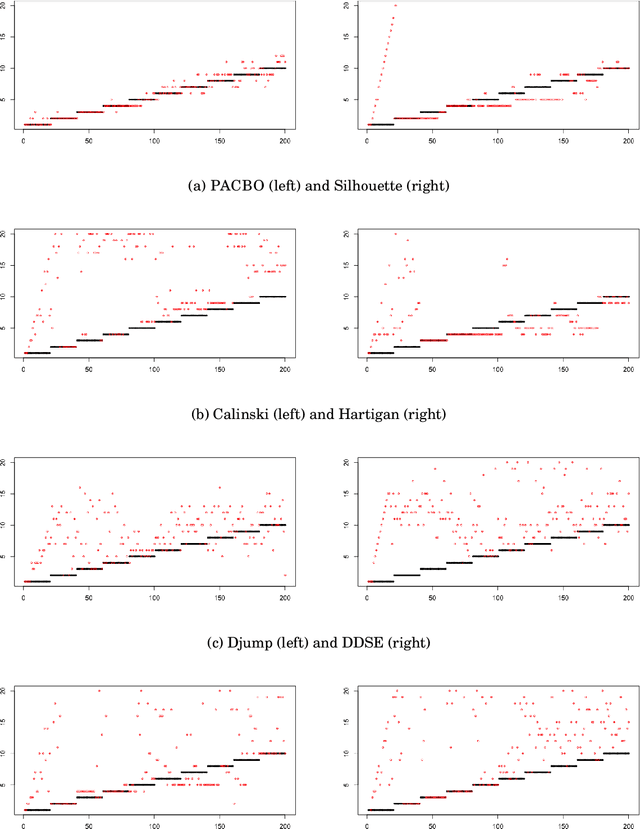
When faced with high frequency streams of data, clustering raises theoretical and algorithmic pitfalls. We introduce a new and adaptive online clustering algorithm relying on a quasi-Bayesian approach, with a dynamic (i.e., time-dependent) estimation of the (unknown and changing) number of clusters. We prove that our approach is supported by minimax regret bounds. We also provide an RJMCMC-flavored implementation (called PACBO, see https://cran.r-project.org/web/packages/PACBO/index.html) for which we give a convergence guarantee. Finally, numerical experiments illustrate the potential of our procedure.