 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdAgent: Multi-Agent Managed Multi-Source Annotation System
Sep 17, 2025High-quality annotated data is a cornerstone of modern Natural Language Processing (NLP). While recent methods begin to leverage diverse annotation sources-including Large Language Models (LLMs), Small Language Models (SLMs), and human experts-they often focus narrowly on the labeling step itself. A critical gap remains in the holistic process control required to manage these sources dynamically, addressing complex scheduling and quality-cost trade-offs in a unified manner. Inspired by real-world crowdsourcing companies, we introduce CrowdAgent, a multi-agent system that provides end-to-end process control by integrating task assignment, data annotation, and quality/cost management. It implements a novel methodology that rationally assigns tasks, enabling LLMs, SLMs, and human experts to advance synergistically in a collaborative annotation workflow. We demonstrate the effectiveness of CrowdAgent through extensive experiments on six diverse multimodal classification tasks. The source code and video demo are available at https://github.com/QMMMS/CrowdAgent.
Fast-DataShapley: Neural Modeling for Training Data Valuation
Jun 05, 2025The value and copyright of training data are crucial in the artificial intelligence industry. Service platforms should protect data providers' legitimate rights and fairly reward them for their contributions. Shapley value, a potent tool for evaluating contributions, outperforms other methods in theory, but its computational overhead escalates exponentially with the number of data providers. Recent works based on Shapley values attempt to mitigate computation complexity by approximation algorithms. However, they need to retrain for each test sample, leading to intolerable costs. We propose Fast-DataShapley, a one-pass training method that leverages the weighted least squares characterization of the Shapley value to train a reusable explainer model with real-time reasoning speed. Given new test samples, no retraining is required to calculate the Shapley values of the training data. Additionally, we propose three methods with theoretical guarantees to reduce training overhead from two aspects: the approximate calculation of the utility function and the group calculation of the training data. We analyze time complexity to show the efficiency of our methods. The experimental evaluations on various image datasets demonstrate superior performance and efficiency compared to baselines. Specifically, the performance is improved to more than 2.5 times, and the explainer's training speed can be increased by two orders of magnitude.
Empowering Economic Simulation for Massively Multiplayer Online Games through Generative Agent-Based Modeling
Jun 05, 2025Within the domain of Massively Multiplayer Online (MMO) economy research, Agent-Based Modeling (ABM) has emerged as a robust tool for analyzing game economics, evolving from rule-based agents to decision-making agents enhanced by reinforcement learning. Nevertheless, existing works encounter significant challenges when attempting to emulate human-like economic activities among agents, particularly regarding agent reliability, sociability, and interpretability. In this study, we take a preliminary step in introducing a novel approach using Large Language Models (LLMs) in MMO economy simulation. Leveraging LLMs' role-playing proficiency, generative capacity, and reasoning aptitude, we design LLM-driven agents with human-like decision-making and adaptability. These agents are equipped with the abilities of role-playing, perception, memory, and reasoning, addressing the aforementioned challenges effectively. Simulation experiments focusing on in-game economic activities demonstrate that LLM-empowered agents can promote emergent phenomena like role specialization and price fluctuations in line with market rules.
MVP-Shapley: Feature-based Modeling for Evaluating the Most Valuable Player in Basketball
Jun 05, 2025The burgeoning growth of the esports and multiplayer online gaming community has highlighted the critical importance of evaluating the Most Valuable Player (MVP). The establishment of an explainable and practical MVP evaluation method is very challenging. In our study, we specifically focus on play-by-play data, which records related events during the game, such as assists and points. We aim to address the challenges by introducing a new MVP evaluation framework, denoted as \oursys, which leverages Shapley values. This approach encompasses feature processing, win-loss model training, Shapley value allocation, and MVP ranking determination based on players' contributions. Additionally, we optimize our algorithm to align with expert voting results from the perspective of causality. Finally, we substantiated the efficacy of our method through validation using the NBA dataset and the Dunk City Dynasty dataset and implemented online deployment in the industry.
Prompt Candidates, then Distill: A Teacher-Student Framework for LLM-driven Data Annotation
Jun 04, 2025Recently, Large Language Models (LLMs) have demonstrated significant potential for data annotation, markedly reducing the labor costs associated with downstream applications. However, existing methods mostly adopt an aggressive strategy by prompting LLM to determine a single gold label for each unlabeled sample. Due to the inherent uncertainty within LLMs, they often produce incorrect labels for difficult samples, severely compromising the data quality for downstream applications. Motivated by ambiguity aversion in human behaviors, we propose a novel candidate annotation paradigm wherein large language models are encouraged to output all possible labels when incurring uncertainty. To ensure unique labels are provided for downstream tasks, we develop a teacher-student framework CanDist that distills candidate annotations with a Small Language Model (SLM). We further provide a rigorous justification demonstrating that distilling candidate annotations from the teacher LLM offers superior theoretical guarantees compared to directly using single annotations. Extensive experiments across six text classification tasks validate the effectiveness of our proposed method. The source code is available at https://github.com/MingxuanXia/CanDist.
Digital Player: Evaluating Large Language Models based Human-like Agent in Games
Feb 28, 2025With the rapid advancement of Large Language Models (LLMs), LLM-based autonomous agents have shown the potential to function as digital employees, such as digital analysts, teachers, and programmers. In this paper, we develop an application-level testbed based on the open-source strategy game "Unciv", which has millions of active players, to enable researchers to build a "data flywheel" for studying human-like agents in the "digital players" task. This "Civilization"-like game features expansive decision-making spaces along with rich linguistic interactions such as diplomatic negotiations and acts of deception, posing significant challenges for LLM-based agents in terms of numerical reasoning and long-term planning. Another challenge for "digital players" is to generate human-like responses for social interaction, collaboration, and negotiation with human players. The open-source project can be found at https:/github.com/fuxiAIlab/CivAgent.
A Flexible Plug-and-Play Module for Generating Variable-Length
Dec 12, 2024Deep supervised hashing has become a pivotal technique in large-scale image retrieval, offering significant benefits in terms of storage and search efficiency. However, existing deep supervised hashing models predominantly focus on generating fixed-length hash codes. This approach fails to address the inherent trade-off between efficiency and effectiveness when using hash codes of varying lengths. To determine the optimal hash code length for a specific task, multiple models must be trained for different lengths, leading to increased training time and computational overhead. Furthermore, the current paradigm overlooks the potential relationships between hash codes of different lengths, limiting the overall effectiveness of the models. To address these challenges, we propose the Nested Hash Layer (NHL), a plug-and-play module designed for existing deep supervised hashing models. The NHL framework introduces a novel mechanism to simultaneously generate hash codes of varying lengths in a nested manner. To tackle the optimization conflicts arising from the multiple learning objectives associated with different code lengths, we further propose an adaptive weights strategy that dynamically monitors and adjusts gradients during training. Additionally, recognizing that the structural information in longer hash codes can provide valuable guidance for shorter hash codes, we develop a long-short cascade self-distillation method within the NHL to enhance the overall quality of the generated hash codes. Extensive experiments demonstrate that NHL not only accelerates the training process but also achieves superior retrieval performance across various deep hashing models. Our code is publicly available at https://github.com/hly1998/NHL.
Rank Aggregation in Crowdsourcing for Listwise Annotations
Oct 10, 2024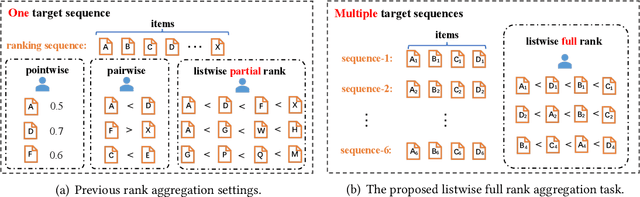



Rank aggregation through crowdsourcing has recently gained significant attention, particularly in the context of listwise ranking annotations. However, existing methods primarily focus on a single problem and partial ranks, while the aggregation of listwise full ranks across numerous problems remains largely unexplored. This scenario finds relevance in various applications, such as model quality assessment and reinforcement learning with human feedback. In light of practical needs, we propose LAC, a Listwise rank Aggregation method in Crowdsourcing, where the global position information is carefully measured and included. In our design, an especially proposed annotation quality indicator is employed to measure the discrepancy between the annotated rank and the true rank. We also take the difficulty of the ranking problem itself into consideration, as it directly impacts the performance of annotators and consequently influences the final results. To our knowledge, LAC is the first work to directly deal with the full rank aggregation problem in listwise crowdsourcing, and simultaneously infer the difficulty of problems, the ability of annotators, and the ground-truth ranks in an unsupervised way. To evaluate our method, we collect a real-world business-oriented dataset for paragraph ranking. Experimental results on both synthetic and real-world benchmark datasets demonstrate the effectiveness of our proposed LAC method.
A Dataset for the Validation of Truth Inference Algorithms Suitable for Online Deployment
Mar 10, 2024



For the purpose of efficient and cost-effective large-scale data labeling, crowdsourcing is increasingly being utilized. To guarantee the quality of data labeling, multiple annotations need to be collected for each data sample, and truth inference algorithms have been developed to accurately infer the true labels. Despite previous studies having released public datasets to evaluate the efficacy of truth inference algorithms, these have typically focused on a single type of crowdsourcing task and neglected the temporal information associated with workers' annotation activities. These limitations significantly restrict the practical applicability of these algorithms, particularly in the context of long-term and online truth inference. In this paper, we introduce a substantial crowdsourcing annotation dataset collected from a real-world crowdsourcing platform. This dataset comprises approximately two thousand workers, one million tasks, and six million annotations. The data was gathered over a period of approximately six months from various types of tasks, and the timestamps of each annotation were preserved. We analyze the characteristics of the dataset from multiple perspectives and evaluate the effectiveness of several representative truth inference algorithms on this dataset. We anticipate that this dataset will stimulate future research on tracking workers' abilities over time in relation to different types of tasks, as well as enhancing online truth inference.
XRL-Bench: A Benchmark for Evaluating and Comparing Explainable Reinforcement Learning Techniques
Feb 20, 2024



Reinforcement Learning (RL) has demonstrated substantial potential across diverse fields, yet understanding its decision-making process, especially in real-world scenarios where rationality and safety are paramount, is an ongoing challenge. This paper delves in to Explainable RL (XRL), a subfield of Explainable AI (XAI) aimed at unravelling the complexities of RL models. Our focus rests on state-explaining techniques, a crucial subset within XRL methods, as they reveal the underlying factors influencing an agent's actions at any given time. Despite their significant role, the lack of a unified evaluation framework hinders assessment of their accuracy and effectiveness. To address this, we introduce XRL-Bench, a unified standardized benchmark tailored for the evaluation and comparison of XRL methods, encompassing three main modules: standard RL environments, explainers based on state importance, and standard evaluators. XRL-Bench supports both tabular and image data for state explanation. We also propose TabularSHAP, an innovative and competitive XRL method. We demonstrate the practical utility of TabularSHAP in real-world online gaming services and offer an open-source benchmark platform for the straightforward implementation and evaluation of XRL methods. Our contributions facilitate the continued progression of XRL technology.