 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXRL-Bench: A Benchmark for Evaluating and Comparing Explainable Reinforcement Learning Techniques
Feb 20, 2024



Reinforcement Learning (RL) has demonstrated substantial potential across diverse fields, yet understanding its decision-making process, especially in real-world scenarios where rationality and safety are paramount, is an ongoing challenge. This paper delves in to Explainable RL (XRL), a subfield of Explainable AI (XAI) aimed at unravelling the complexities of RL models. Our focus rests on state-explaining techniques, a crucial subset within XRL methods, as they reveal the underlying factors influencing an agent's actions at any given time. Despite their significant role, the lack of a unified evaluation framework hinders assessment of their accuracy and effectiveness. To address this, we introduce XRL-Bench, a unified standardized benchmark tailored for the evaluation and comparison of XRL methods, encompassing three main modules: standard RL environments, explainers based on state importance, and standard evaluators. XRL-Bench supports both tabular and image data for state explanation. We also propose TabularSHAP, an innovative and competitive XRL method. We demonstrate the practical utility of TabularSHAP in real-world online gaming services and offer an open-source benchmark platform for the straightforward implementation and evaluation of XRL methods. Our contributions facilitate the continued progression of XRL technology.
Towards Solving Fuzzy Tasks with Human Feedback: A Retrospective of the MineRL BASALT 2022 Competition
Mar 23, 2023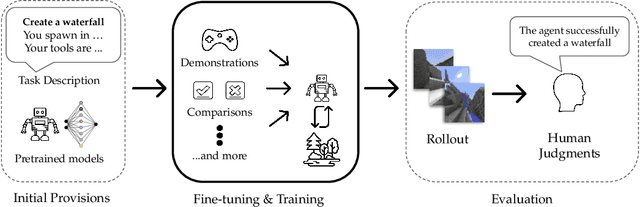

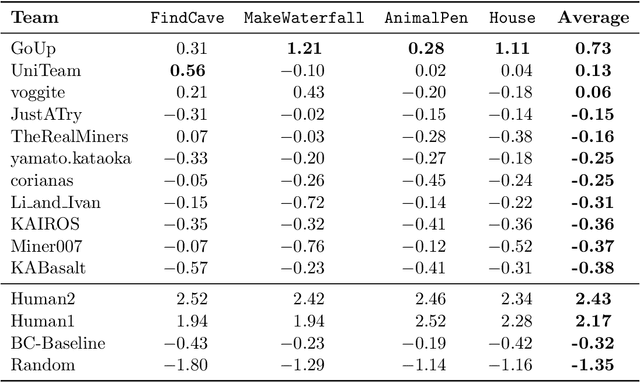
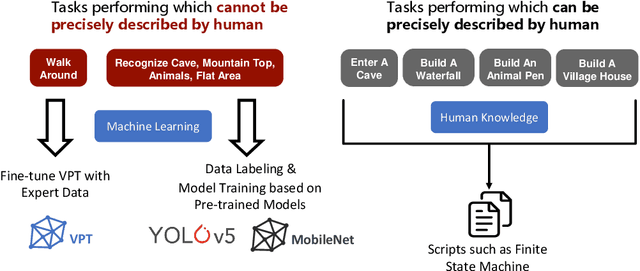
To facilitate research in the direction of fine-tuning foundation models from human feedback, we held the MineRL BASALT Competition on Fine-Tuning from Human Feedback at NeurIPS 2022. The BASALT challenge asks teams to compete to develop algorithms to solve tasks with hard-to-specify reward functions in Minecraft. Through this competition, we aimed to promote the development of algorithms that use human feedback as channels to learn the desired behavior. We describe the competition and provide an overview of the top solutions. We conclude by discussing the impact of the competition and future directions for improvement.
Reinforcement Learning Experience Reuse with Policy Residual Representation
May 31, 2019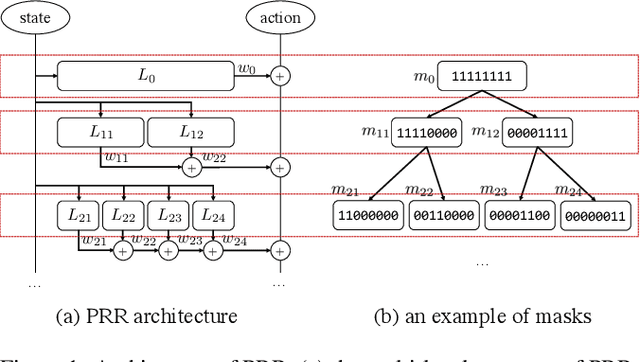

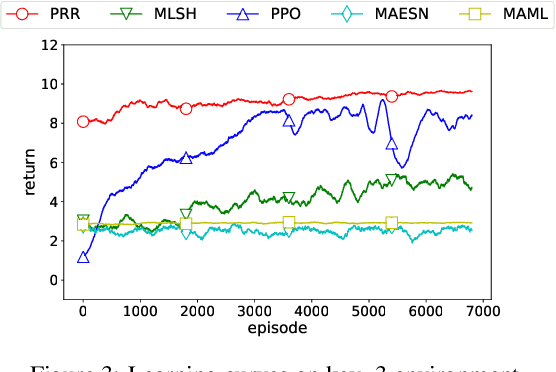
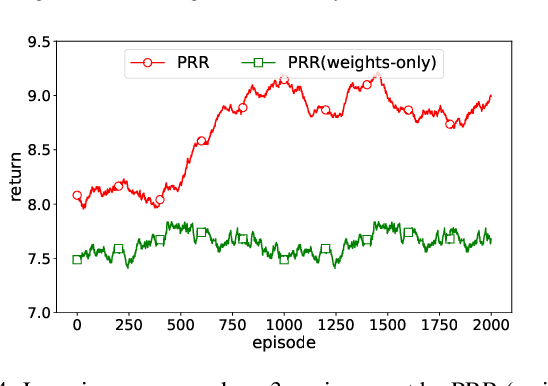
Experience reuse is key to sample-efficient reinforcement learning. One of the critical issues is how the experience is represented and stored. Previously, the experience can be stored in the forms of features, individual models, and the average model, each lying at a different granularity. However, new tasks may require experience across multiple granularities. In this paper, we propose the policy residual representation (PRR) network, which can extract and store multiple levels of experience. PRR network is trained on a set of tasks with a multi-level architecture, where a module in each level corresponds to a subset of the tasks. Therefore, the PRR network represents the experience in a spectrum-like way. When training on a new task, PRR can provide different levels of experience for accelerating the learning. We experiment with the PRR network on a set of grid world navigation tasks, locomotion tasks, and fighting tasks in a video game. The results show that the PRR network leads to better reuse of experience and thus outperforms some state-of-the-art approaches.