 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHLA: Restoring Expressivity of Linear Attention via Token-Level Multi-Head
Jan 12, 2026While the Transformer architecture dominates many fields, its quadratic self-attention complexity hinders its use in large-scale applications. Linear attention offers an efficient alternative, but its direct application often degrades performance, with existing fixes typically re-introducing computational overhead through extra modules (e.g., depthwise separable convolution) that defeat the original purpose. In this work, we identify a key failure mode in these methods: global context collapse, where the model loses representational diversity. To address this, we propose Multi-Head Linear Attention (MHLA), which preserves this diversity by computing attention within divided heads along the token dimension. We prove that MHLA maintains linear complexity while recovering much of the expressive power of softmax attention, and verify its effectiveness across multiple domains, achieving a 3.6\% improvement on ImageNet classification, a 6.3\% gain on NLP, a 12.6\% improvement on image generation, and a 41\% enhancement on video generation under the same time complexity.
Semantic segmentation with reward
May 23, 2025In real-world scenarios, pixel-level labeling is not always available. Sometimes, we need a semantic segmentation network, and even a visual encoder can have a high compatibility, and can be trained using various types of feedback beyond traditional labels, such as feedback that indicates the quality of the parsing results. To tackle this issue, we proposed RSS (Reward in Semantic Segmentation), the first practical application of reward-based reinforcement learning on pure semantic segmentation offered in two granular levels (pixel-level and image-level). RSS incorporates various novel technologies, such as progressive scale rewards (PSR) and pair-wise spatial difference (PSD), to ensure that the reward facilitates the convergence of the semantic segmentation network, especially under image-level rewards. Experiments and visualizations on benchmark datasets demonstrate that the proposed RSS can successfully ensure the convergence of the semantic segmentation network on two levels of rewards. Additionally, the RSS, which utilizes an image-level reward, outperforms existing weakly supervised methods that also rely solely on image-level signals during training.
VPNeXt -- Rethinking Dense Decoding for Plain Vision Transformer
Feb 25, 2025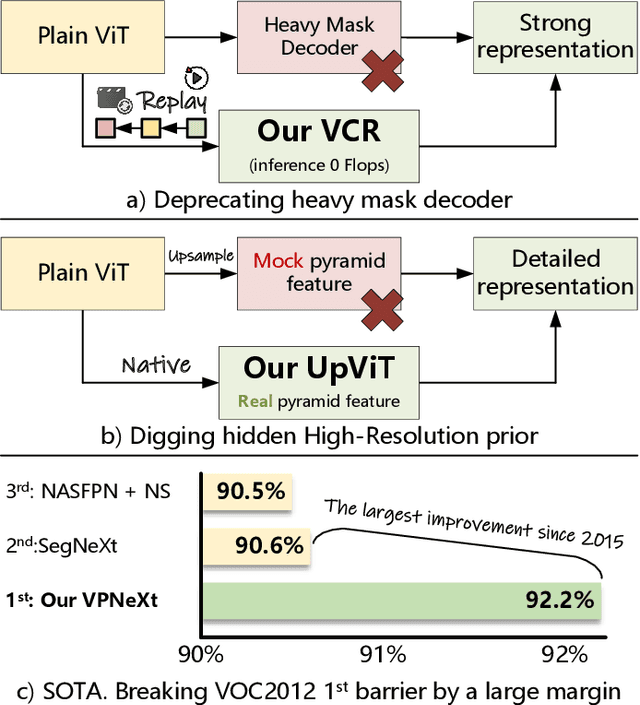



We present VPNeXt, a new and simple model for the Plain Vision Transformer (ViT). Unlike the many related studies that share the same homogeneous paradigms, VPNeXt offers a fresh perspective on dense representation based on ViT. In more detail, the proposed VPNeXt addressed two concerns about the existing paradigm: (1) Is it necessary to use a complex Transformer Mask Decoder architecture to obtain good representations? (2) Does the Plain ViT really need to depend on the mock pyramid feature for upsampling? For (1), we investigated the potential underlying reasons that contributed to the effectiveness of the Transformer Decoder and introduced the Visual Context Replay (VCR) to achieve similar effects efficiently. For (2), we introduced the ViTUp module. This module fully utilizes the previously overlooked ViT real pyramid feature to achieve better upsampling results compared to the earlier mock pyramid feature. This represents the first instance of such functionality in the field of semantic segmentation for Plain ViT. We performed ablation studies on related modules to verify their effectiveness gradually. We conducted relevant comparative experiments and visualizations to show that VPNeXt achieved state-of-the-art performance with a simple and effective design. Moreover, the proposed VPNeXt significantly exceeded the long-established mIoU wall/barrier of the VOC2012 dataset, setting a new state-of-the-art by a large margin, which also stands as the largest improvement since 2015.
S-INF: Towards Realistic Indoor Scene Synthesis via Scene Implicit Neural Field
Dec 23, 2024Learning-based methods have become increasingly popular in 3D indoor scene synthesis (ISS), showing superior performance over traditional optimization-based approaches. These learning-based methods typically model distributions on simple yet explicit scene representations using generative models. However, due to the oversimplified explicit representations that overlook detailed information and the lack of guidance from multimodal relationships within the scene, most learning-based methods struggle to generate indoor scenes with realistic object arrangements and styles. In this paper, we introduce a new method, Scene Implicit Neural Field (S-INF), for indoor scene synthesis, aiming to learn meaningful representations of multimodal relationships, to enhance the realism of indoor scene synthesis. S-INF assumes that the scene layout is often related to the object-detailed information. It disentangles the multimodal relationships into scene layout relationships and detailed object relationships, fusing them later through implicit neural fields (INFs). By learning specialized scene layout relationships and projecting them into S-INF, we achieve a realistic generation of scene layout. Additionally, S-INF captures dense and detailed object relationships through differentiable rendering, ensuring stylistic consistency across objects. Through extensive experiments on the benchmark 3D-FRONT dataset, we demonstrate that our method consistently achieves state-of-the-art performance under different types of ISS.
TAVP: Task-Adaptive Visual Prompt for Cross-domain Few-shot Segmentation
Sep 09, 2024



Under the backdrop of large-scale pre-training, large visual models (LVM) have demonstrated significant potential in image understanding. The recent emergence of the Segment Anything Model (SAM) has brought a qualitative shift in the field of image segmentation, supporting flexible interactive cues and strong learning capabilities. However, its performance often falls short in cross-domain and few-shot applications. Transferring prior knowledge from foundation models to new applications while preserving learning capabilities is worth exploring. This work proposes a task-adaptive prompt framework based on SAM, a new paradigm for Cross-dominan few-shot segmentation (CD-FSS). First, a Multi-level Feature Fusion (MFF) was used for integrated feature extraction. Besides, an additional Class Domain Task-Adaptive Auto-Prompt (CDTAP) module was combined with the segmentation branch for class-domain agnostic feature extraction and high-quality learnable prompt production. This significant advancement uses a unique generative approach to prompts alongside a comprehensive model structure and specialized prototype computation. While ensuring that the prior knowledge of SAM is not discarded, the new branch disentangles category and domain information through prototypes, guiding it in adapting the CD-FSS. We have achieved the best results on three benchmarks compared to the recent state-of-the-art (SOTA) methods. Comprehensive experiments showed that after task-specific and weighted guidance, the abundant feature information of SAM can be better learned for CD-FSS.
Beyond Viewpoint: Robust 3D Object Recognition under Arbitrary Views through Joint Multi-Part Representation
Jul 04, 2024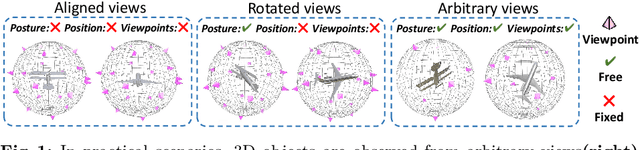
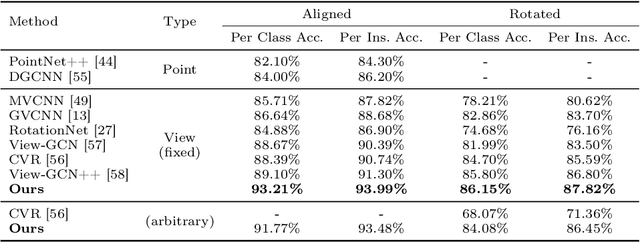
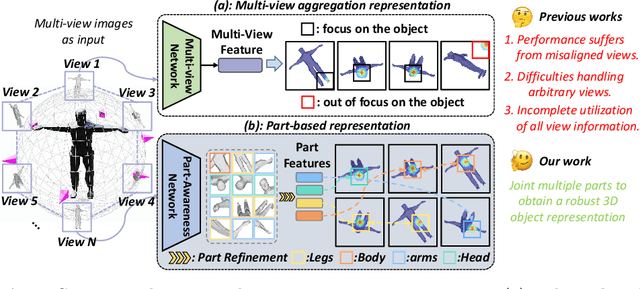
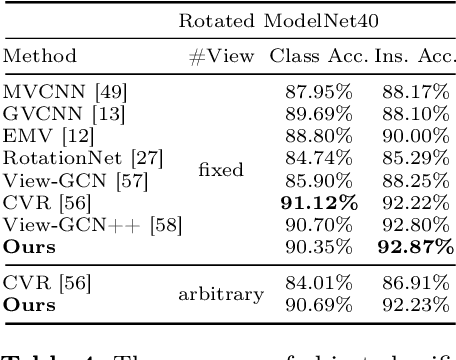
Existing view-based methods excel at recognizing 3D objects from predefined viewpoints, but their exploration of recognition under arbitrary views is limited. This is a challenging and realistic setting because each object has different viewpoint positions and quantities, and their poses are not aligned. However, most view-based methods, which aggregate multiple view features to obtain a global feature representation, hard to address 3D object recognition under arbitrary views. Due to the unaligned inputs from arbitrary views, it is challenging to robustly aggregate features, leading to performance degradation. In this paper, we introduce a novel Part-aware Network (PANet), which is a part-based representation, to address these issues. This part-based representation aims to localize and understand different parts of 3D objects, such as airplane wings and tails. It has properties such as viewpoint invariance and rotation robustness, which give it an advantage in addressing the 3D object recognition problem under arbitrary views. Our results on benchmark datasets clearly demonstrate that our proposed method outperforms existing view-based aggregation baselines for the task of 3D object recognition under arbitrary views, even surpassing most fixed viewpoint methods.
Tuning-Free Adaptive Style Incorporation for Structure-Consistent Text-Driven Style Transfer
Apr 10, 2024

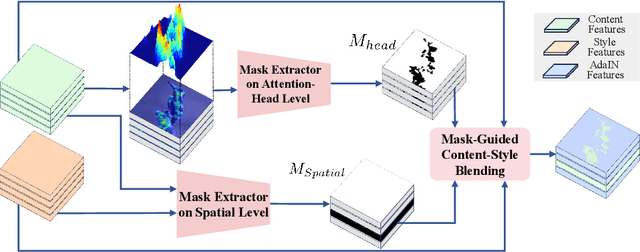

In this work, we target the task of text-driven style transfer in the context of text-to-image (T2I) diffusion models. The main challenge is consistent structure preservation while enabling effective style transfer effects. The past approaches in this field directly concatenate the content and style prompts for a prompt-level style injection, leading to unavoidable structure distortions. In this work, we propose a novel solution to the text-driven style transfer task, namely, Adaptive Style Incorporation~(ASI), to achieve fine-grained feature-level style incorporation. It consists of the Siamese Cross-Attention~(SiCA) to decouple the single-track cross-attention to a dual-track structure to obtain separate content and style features, and the Adaptive Content-Style Blending (AdaBlending) module to couple the content and style information from a structure-consistent manner. Experimentally, our method exhibits much better performance in both structure preservation and stylized effects.
XRL-Bench: A Benchmark for Evaluating and Comparing Explainable Reinforcement Learning Techniques
Feb 20, 2024



Reinforcement Learning (RL) has demonstrated substantial potential across diverse fields, yet understanding its decision-making process, especially in real-world scenarios where rationality and safety are paramount, is an ongoing challenge. This paper delves in to Explainable RL (XRL), a subfield of Explainable AI (XAI) aimed at unravelling the complexities of RL models. Our focus rests on state-explaining techniques, a crucial subset within XRL methods, as they reveal the underlying factors influencing an agent's actions at any given time. Despite their significant role, the lack of a unified evaluation framework hinders assessment of their accuracy and effectiveness. To address this, we introduce XRL-Bench, a unified standardized benchmark tailored for the evaluation and comparison of XRL methods, encompassing three main modules: standard RL environments, explainers based on state importance, and standard evaluators. XRL-Bench supports both tabular and image data for state explanation. We also propose TabularSHAP, an innovative and competitive XRL method. We demonstrate the practical utility of TabularSHAP in real-world online gaming services and offer an open-source benchmark platform for the straightforward implementation and evaluation of XRL methods. Our contributions facilitate the continued progression of XRL technology.
SSR: SAM is a Strong Regularizer for domain adaptive semantic segmentation
Jan 26, 2024


We introduced SSR, which utilizes SAM (segment-anything) as a strong regularizer during training, to greatly enhance the robustness of the image encoder for handling various domains. Specifically, given the fact that SAM is pre-trained with a large number of images over the internet, which cover a diverse variety of domains, the feature encoding extracted by the SAM is obviously less dependent on specific domains when compared to the traditional ImageNet pre-trained image encoder. Meanwhile, the ImageNet pre-trained image encoder is still a mature choice of backbone for the semantic segmentation task, especially when the SAM is category-irrelevant. As a result, our SSR provides a simple yet highly effective design. It uses the ImageNet pre-trained image encoder as the backbone, and the intermediate feature of each stage (ie there are 4 stages in MiT-B5) is regularized by SAM during training. After extensive experimentation on GTA5$\rightarrow$Cityscapes, our SSR significantly improved performance over the baseline without introducing any extra inference overhead.
Beyond Prototypes: Semantic Anchor Regularization for Better Representation Learning
Dec 19, 2023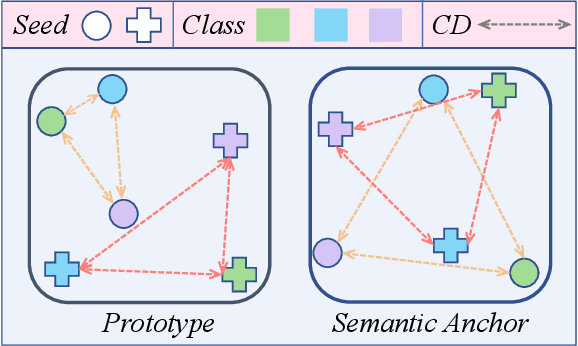
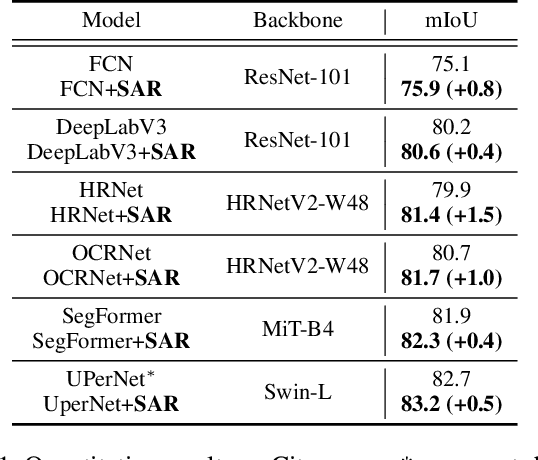
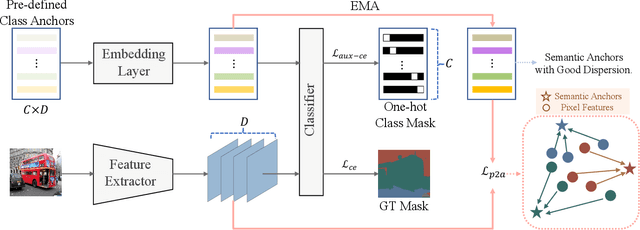
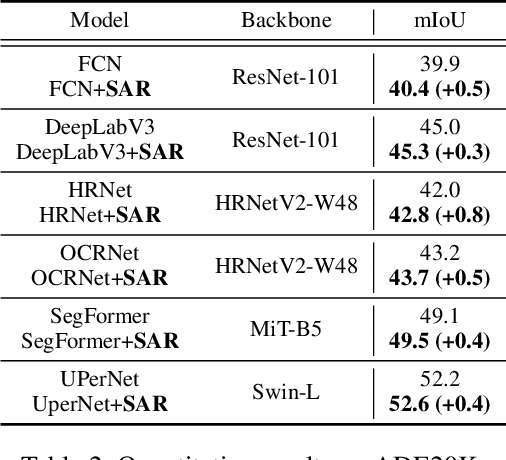
One of the ultimate goals of representation learning is to achieve compactness within a class and well-separability between classes. Many outstanding metric-based and prototype-based methods following the Expectation-Maximization paradigm, have been proposed for this objective. However, they inevitably introduce biases into the learning process, particularly with long-tail distributed training data. In this paper, we reveal that the class prototype is not necessarily to be derived from training features and propose a novel perspective to use pre-defined class anchors serving as feature centroid to unidirectionally guide feature learning. However, the pre-defined anchors may have a large semantic distance from the pixel features, which prevents them from being directly applied. To address this issue and generate feature centroid independent from feature learning, a simple yet effective Semantic Anchor Regularization (SAR) is proposed. SAR ensures the interclass separability of semantic anchors in the semantic space by employing a classifier-aware auxiliary cross-entropy loss during training via disentanglement learning. By pulling the learned features to these semantic anchors, several advantages can be attained: 1) the intra-class compactness and naturally inter-class separability, 2) induced bias or errors from feature learning can be avoided, and 3) robustness to the long-tailed problem. The proposed SAR can be used in a plug-and-play manner in the existing models. Extensive experiments demonstrate that the SAR performs better than previous sophisticated prototype-based methods. The implementation is available at https://github.com/geyanqi/SAR.