 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning-Free Adaptive Style Incorporation for Structure-Consistent Text-Driven Style Transfer
Paper and Code
Apr 10, 2024

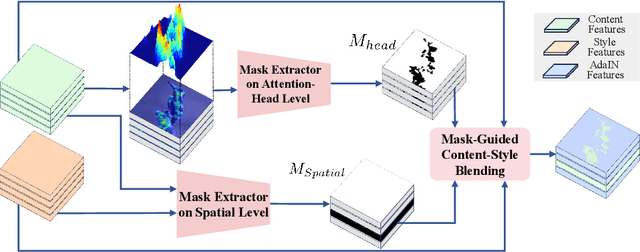

In this work, we target the task of text-driven style transfer in the context of text-to-image (T2I) diffusion models. The main challenge is consistent structure preservation while enabling effective style transfer effects. The past approaches in this field directly concatenate the content and style prompts for a prompt-level style injection, leading to unavoidable structure distortions. In this work, we propose a novel solution to the text-driven style transfer task, namely, Adaptive Style Incorporation~(ASI), to achieve fine-grained feature-level style incorporation. It consists of the Siamese Cross-Attention~(SiCA) to decouple the single-track cross-attention to a dual-track structure to obtain separate content and style features, and the Adaptive Content-Style Blending (AdaBlending) module to couple the content and style information from a structure-consistent manner. Experimentally, our method exhibits much better performance in both structure preservation and stylized effects.