 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextualize Visual Prompt for Image Editing via Diffusion Bridge
Jan 07, 2025



Visual prompt, a pair of before-and-after edited images, can convey indescribable imagery transformations and prosper in image editing. However, current visual prompt methods rely on a pretrained text-guided image-to-image generative model that requires a triplet of text, before, and after images for retraining over a text-to-image model. Such crafting triplets and retraining processes limit the scalability and generalization of editing. In this paper, we present a framework based on any single text-to-image model without reliance on the explicit image-to-image model thus enhancing the generalizability and scalability. Specifically, by leveraging the probability-flow ordinary equation, we construct a diffusion bridge to transfer the distribution between before-and-after images under the text guidance. By optimizing the text via the bridge, the framework adaptively textualizes the editing transformation conveyed by visual prompts into text embeddings without other models. Meanwhile, we introduce differential attention control during text optimization, which disentangles the text embedding from the invariance of the before-and-after images and makes it solely capture the delicate transformation and generalize to edit various images. Experiments on real images validate competitive results on the generalization, contextual coherence, and high fidelity for delicate editing with just one image pair as the visual prompt.
Harnessing Large Vision and Language Models in Agriculture: A Review
Jul 29, 2024Large models can play important roles in many domains. Agriculture is another key factor affecting the lives of people around the world. It provides food, fabric, and coal for humanity. However, facing many challenges such as pests and diseases, soil degradation, global warming, and food security, how to steadily increase the yield in the agricultural sector is a problem that humans still need to solve. Large models can help farmers improve production efficiency and harvest by detecting a series of agricultural production tasks such as pests and diseases, soil quality, and seed quality. It can also help farmers make wise decisions through a variety of information, such as images, text, etc. Herein, we delve into the potential applications of large models in agriculture, from large language model (LLM) and large vision model (LVM) to large vision-language models (LVLM). After gaining a deeper understanding of multimodal large language models (MLLM), it can be recognized that problems such as agricultural image processing, agricultural question answering systems, and agricultural machine automation can all be solved by large models. Large models have great potential in the field of agriculture. We outline the current applications of agricultural large models, and aims to emphasize the importance of large models in the domain of agriculture. In the end, we envisage a future in which famers use MLLM to accomplish many tasks in agriculture, which can greatly improve agricultural production efficiency and yield.
LIPE: Learning Personalized Identity Prior for Non-rigid Image Editing
Jun 25, 2024



Although recent years have witnessed significant advancements in image editing thanks to the remarkable progress of text-to-image diffusion models, the problem of non-rigid image editing still presents its complexities and challenges. Existing methods often fail to achieve consistent results due to the absence of unique identity characteristics. Thus, learning a personalized identity prior might help with consistency in the edited results. In this paper, we explore a novel task: learning the personalized identity prior for text-based non-rigid image editing. To address the problems in jointly learning prior and editing the image, we present LIPE, a two-stage framework designed to customize the generative model utilizing a limited set of images of the same subject, and subsequently employ the model with learned prior for non-rigid image editing. Experimental results demonstrate the advantages of our approach in various editing scenarios over past related leading methods in qualitative and quantitative ways.
FreeDiff: Progressive Frequency Truncation for Image Editing with Diffusion Models
Apr 18, 2024



Precise image editing with text-to-image models has attracted increasing interest due to their remarkable generative capabilities and user-friendly nature. However, such attempts face the pivotal challenge of misalignment between the intended precise editing target regions and the broader area impacted by the guidance in practice. Despite excellent methods leveraging attention mechanisms that have been developed to refine the editing guidance, these approaches necessitate modifications through complex network architecture and are limited to specific editing tasks. In this work, we re-examine the diffusion process and misalignment problem from a frequency perspective, revealing that, due to the power law of natural images and the decaying noise schedule, the denoising network primarily recovers low-frequency image components during the earlier timesteps and thus brings excessive low-frequency signals for editing. Leveraging this insight, we introduce a novel fine-tuning free approach that employs progressive $\textbf{Fre}$qu$\textbf{e}$ncy truncation to refine the guidance of $\textbf{Diff}$usion models for universal editing tasks ($\textbf{FreeDiff}$). Our method achieves comparable results with state-of-the-art methods across a variety of editing tasks and on a diverse set of images, highlighting its potential as a versatile tool in image editing applications.
Tuning-Free Adaptive Style Incorporation for Structure-Consistent Text-Driven Style Transfer
Apr 10, 2024

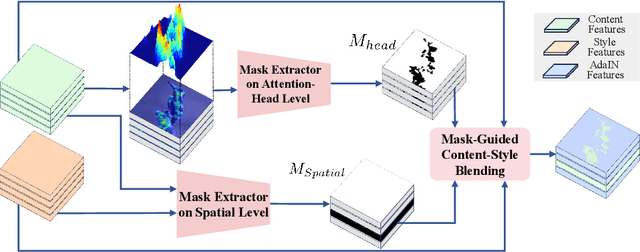

In this work, we target the task of text-driven style transfer in the context of text-to-image (T2I) diffusion models. The main challenge is consistent structure preservation while enabling effective style transfer effects. The past approaches in this field directly concatenate the content and style prompts for a prompt-level style injection, leading to unavoidable structure distortions. In this work, we propose a novel solution to the text-driven style transfer task, namely, Adaptive Style Incorporation~(ASI), to achieve fine-grained feature-level style incorporation. It consists of the Siamese Cross-Attention~(SiCA) to decouple the single-track cross-attention to a dual-track structure to obtain separate content and style features, and the Adaptive Content-Style Blending (AdaBlending) module to couple the content and style information from a structure-consistent manner. Experimentally, our method exhibits much better performance in both structure preservation and stylized effects.
InstructBrush: Learning Attention-based Instruction Optimization for Image Editing
Mar 27, 2024



In recent years, instruction-based image editing methods have garnered significant attention in image editing. However, despite encompassing a wide range of editing priors, these methods are helpless when handling editing tasks that are challenging to accurately describe through language. We propose InstructBrush, an inversion method for instruction-based image editing methods to bridge this gap. It extracts editing effects from exemplar image pairs as editing instructions, which are further applied for image editing. Two key techniques are introduced into InstructBrush, Attention-based Instruction Optimization and Transformation-oriented Instruction Initialization, to address the limitations of the previous method in terms of inversion effects and instruction generalization. To explore the ability of instruction inversion methods to guide image editing in open scenarios, we establish a TransformationOriented Paired Benchmark (TOP-Bench), which contains a rich set of scenes and editing types. The creation of this benchmark paves the way for further exploration of instruction inversion. Quantitatively and qualitatively, our approach achieves superior performance in editing and is more semantically consistent with the target editing effects.