 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Priors Backfire: On the Vulnerability of Unlearnable Examples to Pretraining
Mar 05, 2026Unlearnable Examples (UEs) serve as a data protection strategy that generates imperceptible perturbations to mislead models into learning spurious correlations instead of underlying semantics. In this paper, we uncover a fundamental vulnerability of UEs that emerges when learning starts from a pretrained model. Crucially, our empirical analysis shows that even when data are protected by carefully crafted perturbations, pretraining priors still furnish rich semantic representations that allow the model to circumvent the shortcuts introduced by UEs and capture genuine features, thereby nullifying unlearnability. To address this, we propose BAIT (Binding Artificial perturbations to Incorrect Targets), a novel bi-level optimization formulation. Specifically, the inner level aims at associating the perturbed samples with real labels to simulate standard data-label alignment, while the outer level actively disrupts this alignment by enforcing a mislabel-perturbation binding that maps samples to designated incorrect targets. This mechanism effectively overrides the semantic guidance of priors, forcing the model to rely on the injected perturbations and consequently preventing the acquisition of true semantics. Extensive experiments on standard benchmarks and multiple pretrained backbones demonstrate that BAIT effectively mitigates the influence of pretraining priors and maintains data unlearnability.
Graph Domain Adaptation via Homophily-Agnostic Reconstructing Structure
Feb 07, 2026Graph Domain Adaptation (GDA) transfers knowledge from labeled source graphs to unlabeled target graphs, addressing the challenge of label scarcity. However, existing GDA methods typically assume that both source and target graphs exhibit homophily, leading existing methods to perform poorly when heterophily is present. Furthermore, the lack of labels in the target graph makes it impossible to assess its homophily level beforehand. To address this challenge, we propose a novel homophily-agnostic approach that effectively transfers knowledge between graphs with varying degrees of homophily. Specifically, we adopt a divide-and-conquer strategy that first separately reconstructs highly homophilic and heterophilic variants of both the source and target graphs, and then performs knowledge alignment separately between corresponding graph variants. Extensive experiments conducted on five benchmark datasets demonstrate the superior performance of our approach, particularly highlighting its substantial advantages on heterophilic graphs.
Event-Driven Online Vertical Federated Learning
Jun 17, 2025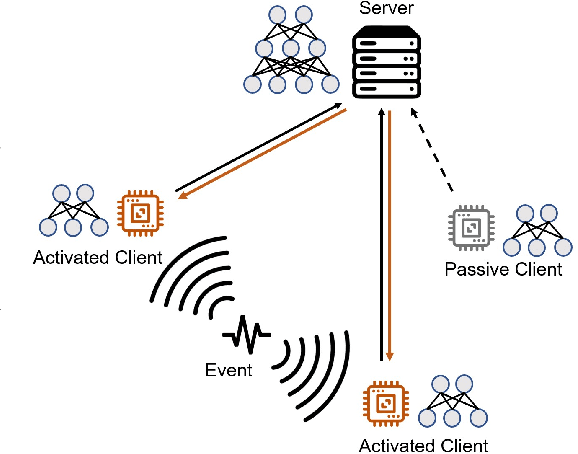



Online learning is more adaptable to real-world scenarios in Vertical Federated Learning (VFL) compared to offline learning. However, integrating online learning into VFL presents challenges due to the unique nature of VFL, where clients possess non-intersecting feature sets for the same sample. In real-world scenarios, the clients may not receive data streaming for the disjoint features for the same entity synchronously. Instead, the data are typically generated by an \emph{event} relevant to only a subset of clients. We are the first to identify these challenges in online VFL, which have been overlooked by previous research. To address these challenges, we proposed an event-driven online VFL framework. In this framework, only a subset of clients were activated during each event, while the remaining clients passively collaborated in the learning process. Furthermore, we incorporated \emph{dynamic local regret (DLR)} into VFL to address the challenges posed by online learning problems with non-convex models within a non-stationary environment. We conducted a comprehensive regret analysis of our proposed framework, specifically examining the DLR under non-convex conditions with event-driven online VFL. Extensive experiments demonstrated that our proposed framework was more stable than the existing online VFL framework under non-stationary data conditions while also significantly reducing communication and computation costs.
* Published as a conference paper at ICLR 2025
FedOne: Query-Efficient Federated Learning for Black-box Discrete Prompt Learning
Jun 17, 2025

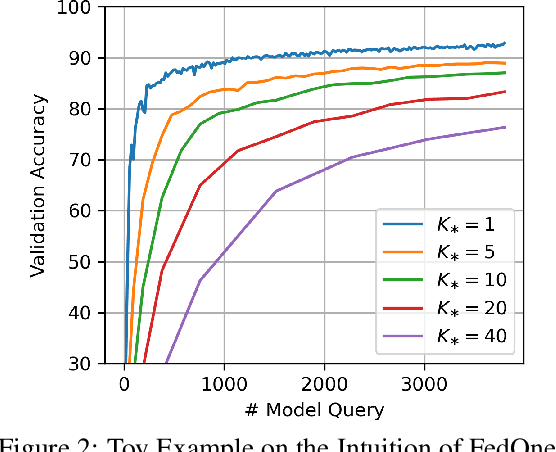

Black-Box Discrete Prompt Learning is a prompt-tuning method that optimizes discrete prompts without accessing model parameters or gradients, making the prompt tuning on a cloud-based Large Language Model (LLM) feasible. Adapting federated learning to BDPL could further enhance prompt tuning performance by leveraging data from diverse sources. However, all previous research on federated black-box prompt tuning had neglected the substantial query cost associated with the cloud-based LLM service. To address this gap, we conducted a theoretical analysis of query efficiency within the context of federated black-box prompt tuning. Our findings revealed that degrading FedAvg to activate only one client per round, a strategy we called \textit{FedOne}, enabled optimal query efficiency in federated black-box prompt learning. Building on this insight, we proposed the FedOne framework, a federated black-box discrete prompt learning method designed to maximize query efficiency when interacting with cloud-based LLMs. We conducted numerical experiments on various aspects of our framework, demonstrating a significant improvement in query efficiency, which aligns with our theoretical results.
* Published in Proceedings of the 42nd International Conference on Machine Learning
Homophily Enhanced Graph Domain Adaptation
May 26, 2025



Graph Domain Adaptation (GDA) transfers knowledge from labeled source graphs to unlabeled target graphs, addressing the challenge of label scarcity. In this paper, we highlight the significance of graph homophily, a pivotal factor for graph domain alignment, which, however, has long been overlooked in existing approaches. Specifically, our analysis first reveals that homophily discrepancies exist in benchmarks. Moreover, we also show that homophily discrepancies degrade GDA performance from both empirical and theoretical aspects, which further underscores the importance of homophily alignment in GDA. Inspired by this finding, we propose a novel homophily alignment algorithm that employs mixed filters to smooth graph signals, thereby effectively capturing and mitigating homophily discrepancies between graphs. Experimental results on a variety of benchmarks verify the effectiveness of our method.
ZETA: Leveraging Z-order Curves for Efficient Top-k Attention
Jan 24, 2025Over recent years, the Transformer has become a fundamental building block for sequence modeling architectures. Yet at its core is the use of self-attention, whose memory and computational cost grow quadratically with the sequence length $N$, rendering it prohibitively expensive for long sequences. A promising approach is top-$k$ attention, which selects only the $k$ most relevant tokens and achieves performance comparable to vanilla self-attention while significantly reducing space and computational demands. However, causal masks require the current query token to only attend to past tokens, preventing the existing top-$k$ attention method from efficiently searching for the most relevant tokens in parallel, thereby limiting training efficiency. In this work, we propose ZETA, leveraging \textbf{Z}-Order Curves for \textbf{E}fficient \textbf{T}op-$k$ \textbf{A}ttention, to enable parallel querying of past tokens for entire sequences. % in both space and time complexity of $\mathcal{O}(N \log N)$. We first theoretically show that the choice of key and query dimensions involves a trade-off between the curse of dimensionality and the preservation of relative distances after projection. In light of this insight, we propose reducing the dimensionality of keys and queries in contrast to values and further leverage $Z$-order curves to map low-dimensional keys and queries into \emph{one}-dimensional space, which permits parallel sorting, thereby largely improving the efficiency for top-$k$ token selection. Experimental results demonstrate that ZETA matches the performance of standard attention on the synthetic \textsc{Multi-Query Associative Recall} task and outperforms attention and its variants on \textsc{Long Range Arena} and \textsc{WikiText-103} language modeling.
Textualize Visual Prompt for Image Editing via Diffusion Bridge
Jan 07, 2025



Visual prompt, a pair of before-and-after edited images, can convey indescribable imagery transformations and prosper in image editing. However, current visual prompt methods rely on a pretrained text-guided image-to-image generative model that requires a triplet of text, before, and after images for retraining over a text-to-image model. Such crafting triplets and retraining processes limit the scalability and generalization of editing. In this paper, we present a framework based on any single text-to-image model without reliance on the explicit image-to-image model thus enhancing the generalizability and scalability. Specifically, by leveraging the probability-flow ordinary equation, we construct a diffusion bridge to transfer the distribution between before-and-after images under the text guidance. By optimizing the text via the bridge, the framework adaptively textualizes the editing transformation conveyed by visual prompts into text embeddings without other models. Meanwhile, we introduce differential attention control during text optimization, which disentangles the text embedding from the invariance of the before-and-after images and makes it solely capture the delicate transformation and generalize to edit various images. Experiments on real images validate competitive results on the generalization, contextual coherence, and high fidelity for delicate editing with just one image pair as the visual prompt.
Unveil Inversion and Invariance in Flow Transformer for Versatile Image Editing
Nov 26, 2024



Leveraging the large generative prior of the flow transformer for tuning-free image editing requires authentic inversion to project the image into the model's domain and a flexible invariance control mechanism to preserve non-target contents. However, the prevailing diffusion inversion performs deficiently in flow-based models, and the invariance control cannot reconcile diverse rigid and non-rigid editing tasks. To address these, we systematically analyze the \textbf{inversion and invariance} control based on the flow transformer. Specifically, we unveil that the Euler inversion shares a similar structure to DDIM yet is more susceptible to the approximation error. Thus, we propose a two-stage inversion to first refine the velocity estimation and then compensate for the leftover error, which pivots closely to the model prior and benefits editing. Meanwhile, we propose the invariance control that manipulates the text features within the adaptive layer normalization, connecting the changes in the text prompt to image semantics. This mechanism can simultaneously preserve the non-target contents while allowing rigid and non-rigid manipulation, enabling a wide range of editing types such as visual text, quantity, facial expression, etc. Experiments on versatile scenarios validate that our framework achieves flexible and accurate editing, unlocking the potential of the flow transformer for versatile image editing.
MABR: A Multilayer Adversarial Bias Removal Approach Without Prior Bias Knowledge
Aug 10, 2024Models trained on real-world data often mirror and exacerbate existing social biases. Traditional methods for mitigating these biases typically require prior knowledge of the specific biases to be addressed, such as gender or racial biases, and the social groups associated with each instance. In this paper, we introduce a novel adversarial training strategy that operates independently of prior bias-type knowledge and protected attribute labels. Our approach proactively identifies biases during model training by utilizing auxiliary models, which are trained concurrently by predicting the performance of the main model without relying on task labels. Additionally, we implement these auxiliary models at various levels of the feature maps of the main model, enabling the detection of a broader and more nuanced range of bias features. Through experiments on racial and gender biases in sentiment and occupation classification tasks, our method effectively reduces social biases without the need for demographic annotations. Moreover, our approach not only matches but often surpasses the efficacy of methods that require detailed demographic insights, marking a significant advancement in bias mitigation techniques.
Intersectional Unfairness Discovery
May 31, 2024

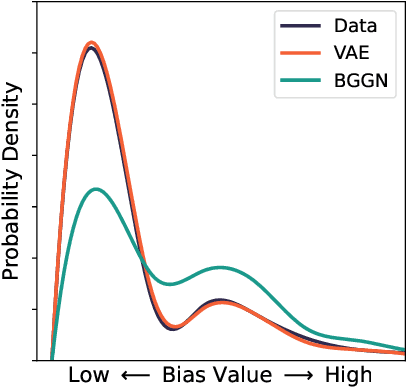
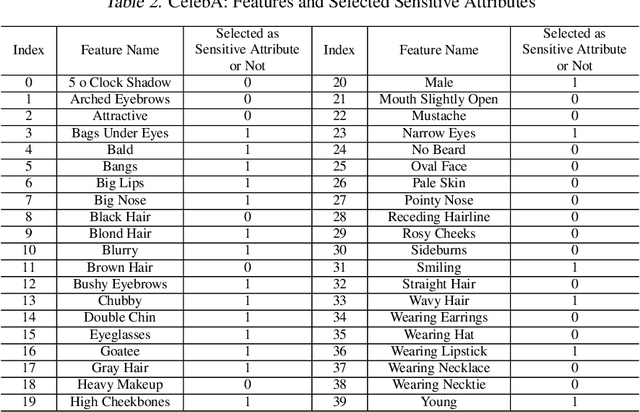
AI systems have been shown to produce unfair results for certain subgroups of population, highlighting the need to understand bias on certain sensitive attributes. Current research often falls short, primarily focusing on the subgroups characterized by a single sensitive attribute, while neglecting the nature of intersectional fairness of multiple sensitive attributes. This paper focuses on its one fundamental aspect by discovering diverse high-bias subgroups under intersectional sensitive attributes. Specifically, we propose a Bias-Guided Generative Network (BGGN). By treating each bias value as a reward, BGGN efficiently generates high-bias intersectional sensitive attributes. Experiments on real-world text and image datasets demonstrate a diverse and efficient discovery of BGGN. To further evaluate the generated unseen but possible unfair intersectional sensitive attributes, we formulate them as prompts and use modern generative AI to produce new texts and images. The results of frequently generating biased data provides new insights of discovering potential unfairness in popular modern generative AI systems. Warning: This paper contains generative examples that are offensive in nature.