 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization of Layer Skipping and Frequency Scaling for Convolutional Neural Networks under Latency Constraint
Mar 31, 2025



The energy consumption of Convolutional Neural Networks (CNNs) is a critical factor in deploying deep learning models on resource-limited equipment such as mobile devices and autonomous vehicles. We propose an approach involving Proportional Layer Skipping (PLS) and Frequency Scaling (FS). Layer skipping reduces computational complexity by selectively bypassing network layers, whereas frequency scaling adjusts the frequency of the processor to optimize energy use under latency constraints. Experiments of PLS and FS on ResNet-152 with the CIFAR-10 dataset demonstrated significant reductions in computational demands and energy consumption with minimal accuracy loss. This study offers practical solutions for improving real-time processing in resource-limited settings and provides insights into balancing computational efficiency and model performance.
Textualize Visual Prompt for Image Editing via Diffusion Bridge
Jan 07, 2025



Visual prompt, a pair of before-and-after edited images, can convey indescribable imagery transformations and prosper in image editing. However, current visual prompt methods rely on a pretrained text-guided image-to-image generative model that requires a triplet of text, before, and after images for retraining over a text-to-image model. Such crafting triplets and retraining processes limit the scalability and generalization of editing. In this paper, we present a framework based on any single text-to-image model without reliance on the explicit image-to-image model thus enhancing the generalizability and scalability. Specifically, by leveraging the probability-flow ordinary equation, we construct a diffusion bridge to transfer the distribution between before-and-after images under the text guidance. By optimizing the text via the bridge, the framework adaptively textualizes the editing transformation conveyed by visual prompts into text embeddings without other models. Meanwhile, we introduce differential attention control during text optimization, which disentangles the text embedding from the invariance of the before-and-after images and makes it solely capture the delicate transformation and generalize to edit various images. Experiments on real images validate competitive results on the generalization, contextual coherence, and high fidelity for delicate editing with just one image pair as the visual prompt.
Diff-2-in-1: Bridging Generation and Dense Perception with Diffusion Models
Nov 07, 2024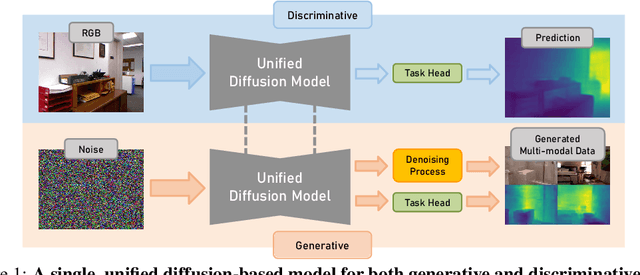
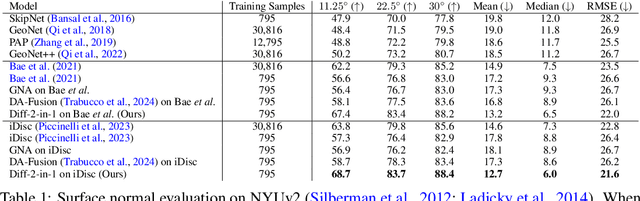
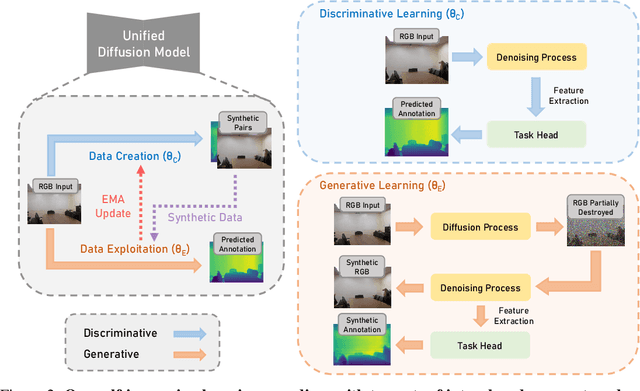
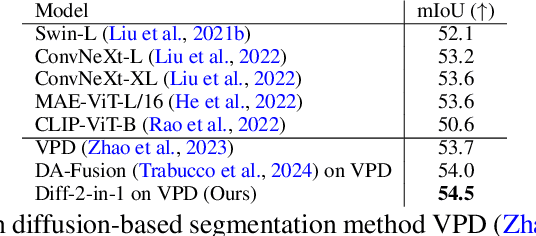
Beyond high-fidelity image synthesis, diffusion models have recently exhibited promising results in dense visual perception tasks. However, most existing work treats diffusion models as a standalone component for perception tasks, employing them either solely for off-the-shelf data augmentation or as mere feature extractors. In contrast to these isolated and thus sub-optimal efforts, we introduce a unified, versatile, diffusion-based framework, Diff-2-in-1, that can simultaneously handle both multi-modal data generation and dense visual perception, through a unique exploitation of the diffusion-denoising process. Within this framework, we further enhance discriminative visual perception via multi-modal generation, by utilizing the denoising network to create multi-modal data that mirror the distribution of the original training set. Importantly, Diff-2-in-1 optimizes the utilization of the created diverse and faithful data by leveraging a novel self-improving learning mechanism. Comprehensive experimental evaluations validate the effectiveness of our framework, showcasing consistent performance improvements across various discriminative backbones and high-quality multi-modal data generation characterized by both realism and usefulness.
FreeDiff: Progressive Frequency Truncation for Image Editing with Diffusion Models
Apr 18, 2024



Precise image editing with text-to-image models has attracted increasing interest due to their remarkable generative capabilities and user-friendly nature. However, such attempts face the pivotal challenge of misalignment between the intended precise editing target regions and the broader area impacted by the guidance in practice. Despite excellent methods leveraging attention mechanisms that have been developed to refine the editing guidance, these approaches necessitate modifications through complex network architecture and are limited to specific editing tasks. In this work, we re-examine the diffusion process and misalignment problem from a frequency perspective, revealing that, due to the power law of natural images and the decaying noise schedule, the denoising network primarily recovers low-frequency image components during the earlier timesteps and thus brings excessive low-frequency signals for editing. Leveraging this insight, we introduce a novel fine-tuning free approach that employs progressive $\textbf{Fre}$qu$\textbf{e}$ncy truncation to refine the guidance of $\textbf{Diff}$usion models for universal editing tasks ($\textbf{FreeDiff}$). Our method achieves comparable results with state-of-the-art methods across a variety of editing tasks and on a diverse set of images, highlighting its potential as a versatile tool in image editing applications.
InstructBrush: Learning Attention-based Instruction Optimization for Image Editing
Mar 27, 2024



In recent years, instruction-based image editing methods have garnered significant attention in image editing. However, despite encompassing a wide range of editing priors, these methods are helpless when handling editing tasks that are challenging to accurately describe through language. We propose InstructBrush, an inversion method for instruction-based image editing methods to bridge this gap. It extracts editing effects from exemplar image pairs as editing instructions, which are further applied for image editing. Two key techniques are introduced into InstructBrush, Attention-based Instruction Optimization and Transformation-oriented Instruction Initialization, to address the limitations of the previous method in terms of inversion effects and instruction generalization. To explore the ability of instruction inversion methods to guide image editing in open scenarios, we establish a TransformationOriented Paired Benchmark (TOP-Bench), which contains a rich set of scenes and editing types. The creation of this benchmark paves the way for further exploration of instruction inversion. Quantitatively and qualitatively, our approach achieves superior performance in editing and is more semantically consistent with the target editing effects.
CatVersion: Concatenating Embeddings for Diffusion-Based Text-to-Image Personalization
Nov 30, 2023
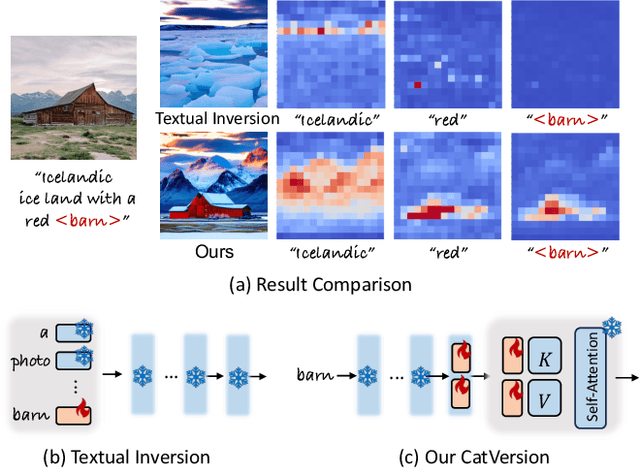
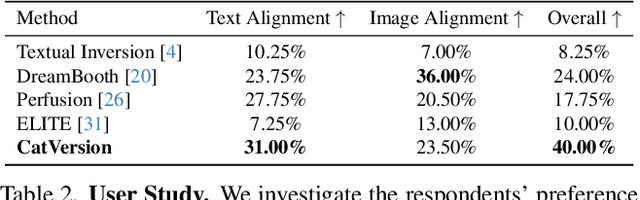
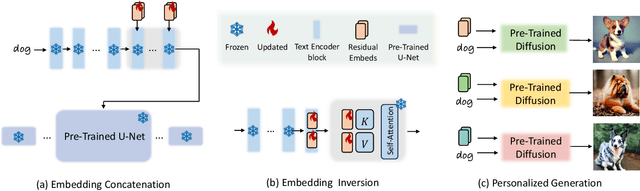
We propose CatVersion, an inversion-based method that learns the personalized concept through a handful of examples. Subsequently, users can utilize text prompts to generate images that embody the personalized concept, thereby achieving text-to-image personalization. In contrast to existing approaches that emphasize word embedding learning or parameter fine-tuning for the diffusion model, which potentially causes concept dilution or overfitting, our method concatenates embeddings on the feature-dense space of the text encoder in the diffusion model to learn the gap between the personalized concept and its base class, aiming to maximize the preservation of prior knowledge in diffusion models while restoring the personalized concepts. To this end, we first dissect the text encoder's integration in the image generation process to identify the feature-dense space of the encoder. Afterward, we concatenate embeddings on the Keys and Values in this space to learn the gap between the personalized concept and its base class. In this way, the concatenated embeddings ultimately manifest as a residual on the original attention output. To more accurately and unbiasedly quantify the results of personalized image generation, we improve the CLIP image alignment score based on masks. Qualitatively and quantitatively, CatVersion helps to restore personalization concepts more faithfully and enables more robust editing.
Few-shot Face Image Translation via GAN Prior Distillation
Jan 28, 2023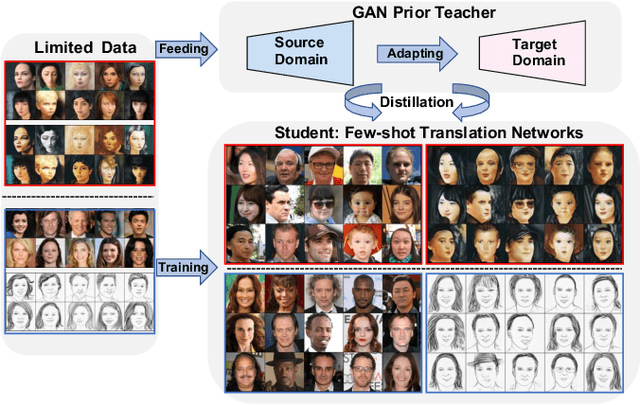
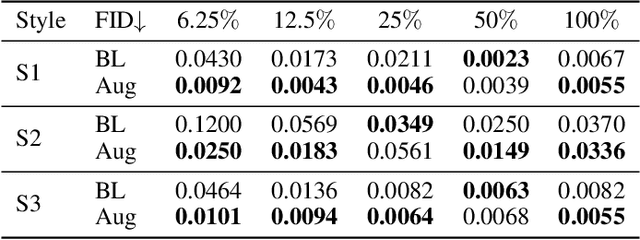
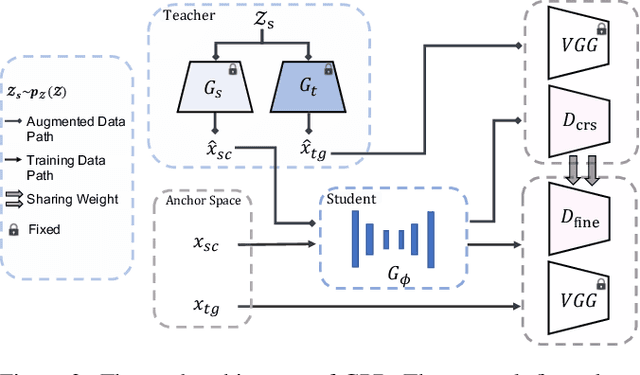
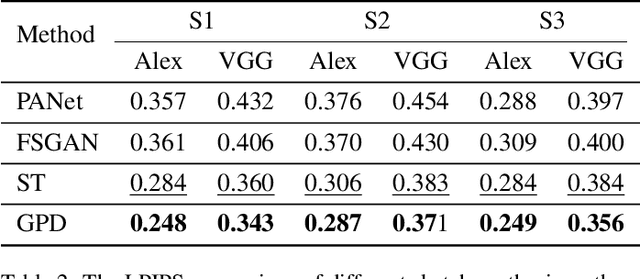
Face image translation has made notable progress in recent years. However, when training on limited data, the performance of existing approaches significantly declines. Although some studies have attempted to tackle this problem, they either failed to achieve the few-shot setting (less than 10) or can only get suboptimal results. In this paper, we propose GAN Prior Distillation (GPD) to enable effective few-shot face image translation. GPD contains two models: a teacher network with GAN Prior and a student network that fulfills end-to-end translation. Specifically, we adapt the teacher network trained on large-scale data in the source domain to the target domain with only a few samples, where it can learn the target domain's knowledge. Then, we can achieve few-shot augmentation by generating source domain and target domain images simultaneously with the same latent codes. We propose an anchor-based knowledge distillation module that can fully use the difference between the training and the augmented data to distill the knowledge of the teacher network into the student network. The trained student network achieves excellent generalization performance with the absorption of additional knowledge. Qualitative and quantitative experiments demonstrate that our method achieves superior results than state-of-the-art approaches in a few-shot setting.