 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatVersion: Concatenating Embeddings for Diffusion-Based Text-to-Image Personalization
Paper and Code

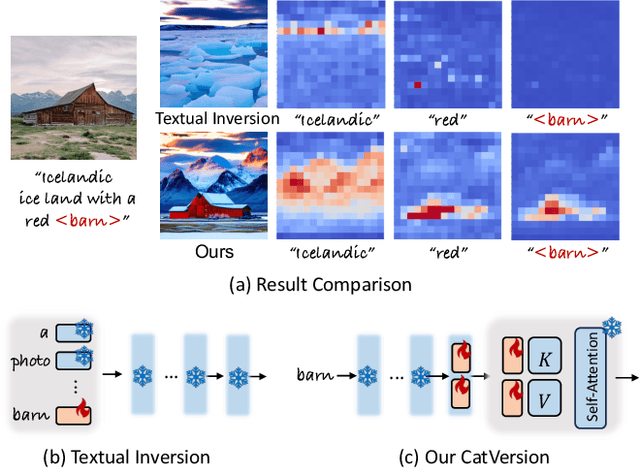
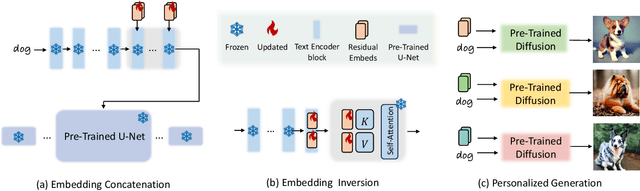
We propose CatVersion, an inversion-based method that learns the personalized concept through a handful of examples. Subsequently, users can utilize text prompts to generate images that embody the personalized concept, thereby achieving text-to-image personalization. In contrast to existing approaches that emphasize word embedding learning or parameter fine-tuning for the diffusion model, which potentially causes concept dilution or overfitting, our method concatenates embeddings on the feature-dense space of the text encoder in the diffusion model to learn the gap between the personalized concept and its base class, aiming to maximize the preservation of prior knowledge in diffusion models while restoring the personalized concepts. To this end, we first dissect the text encoder's integration in the image generation process to identify the feature-dense space of the encoder. Afterward, we concatenate embeddings on the Keys and Values in this space to learn the gap between the personalized concept and its base class. In this way, the concatenated embeddings ultimately manifest as a residual on the original attention output. To more accurately and unbiasedly quantify the results of personalized image generation, we improve the CLIP image alignment score based on masks. Qualitatively and quantitatively, CatVersion helps to restore personalization concepts more faithfully and enables more robust editing.