 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Quality: Unlocking Diversity in Ad Headline Generation with Large Language Models
Aug 26, 2025
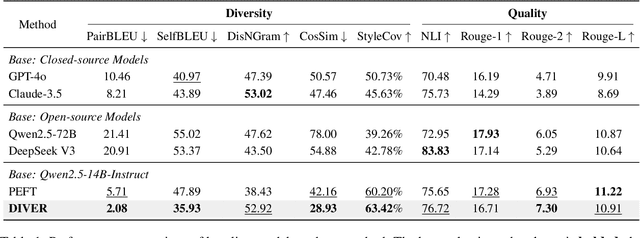
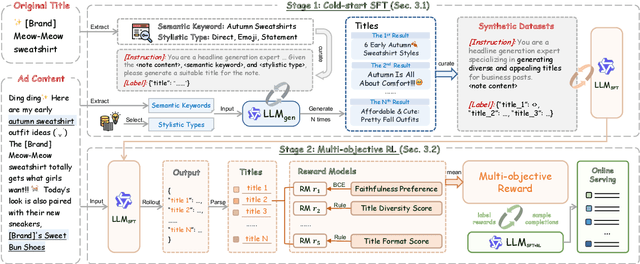
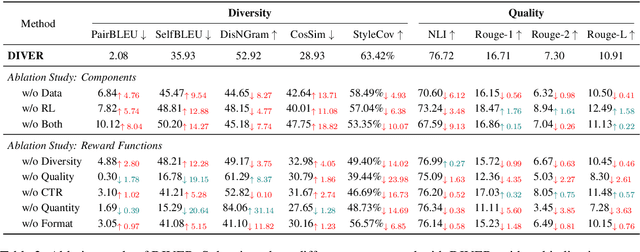
The generation of ad headlines plays a vital role in modern advertising, where both quality and diversity are essential to engage a broad range of audience segments. Current approaches primarily optimize language models for headline quality or click-through rates (CTR), often overlooking the need for diversity and resulting in homogeneous outputs. To address this limitation, we propose DIVER, a novel framework based on large language models (LLMs) that are jointly optimized for both diversity and quality. We first design a semantic- and stylistic-aware data generation pipeline that automatically produces high-quality training pairs with ad content and multiple diverse headlines. To achieve the goal of generating high-quality and diversified ad headlines within a single forward pass, we propose a multi-stage multi-objective optimization framework with supervised fine-tuning (SFT) and reinforcement learning (RL). Experiments on real-world industrial datasets demonstrate that DIVER effectively balances quality and diversity. Deployed on a large-scale content-sharing platform serving hundreds of millions of users, our framework improves advertiser value (ADVV) and CTR by 4.0% and 1.4%.
Effective Diffusion Transformer Architecture for Image Super-Resolution
Sep 29, 2024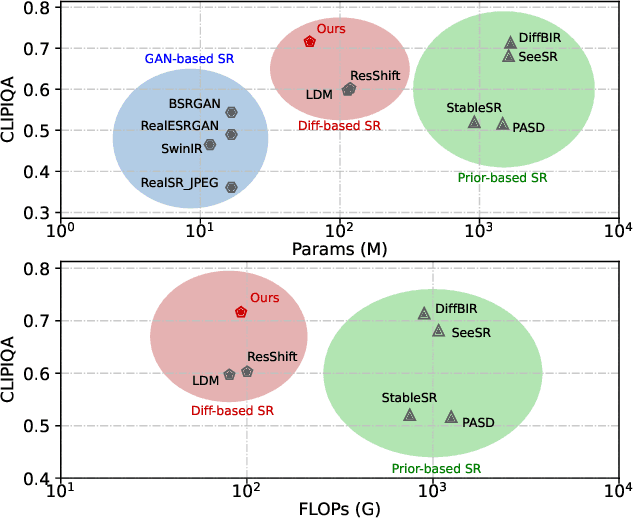
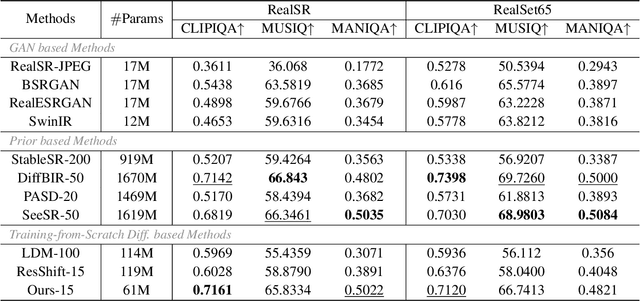


Recent advances indicate that diffusion models hold great promise in image super-resolution. While the latest methods are primarily based on latent diffusion models with convolutional neural networks, there are few attempts to explore transformers, which have demonstrated remarkable performance in image generation. In this work, we design an effective diffusion transformer for image super-resolution (DiT-SR) that achieves the visual quality of prior-based methods, but through a training-from-scratch manner. In practice, DiT-SR leverages an overall U-shaped architecture, and adopts a uniform isotropic design for all the transformer blocks across different stages. The former facilitates multi-scale hierarchical feature extraction, while the latter reallocates the computational resources to critical layers to further enhance performance. Moreover, we thoroughly analyze the limitation of the widely used AdaLN, and present a frequency-adaptive time-step conditioning module, enhancing the model's capacity to process distinct frequency information at different time steps. Extensive experiments demonstrate that DiT-SR outperforms the existing training-from-scratch diffusion-based SR methods significantly, and even beats some of the prior-based methods on pretrained Stable Diffusion, proving the superiority of diffusion transformer in image super-resolution.
Foodfusion: A Novel Approach for Food Image Composition via Diffusion Models
Aug 26, 2024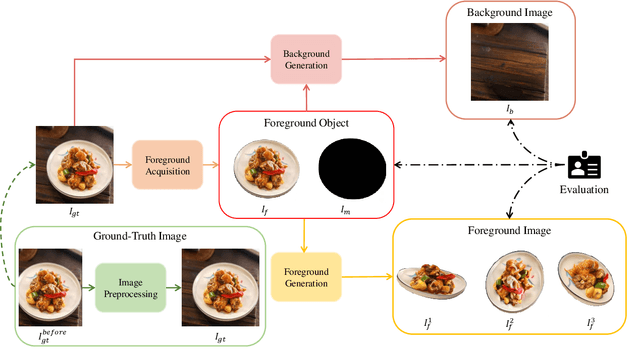
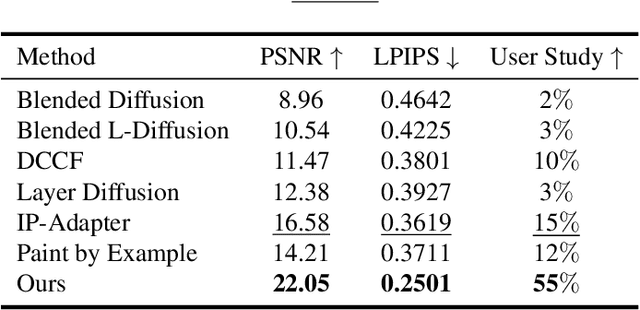

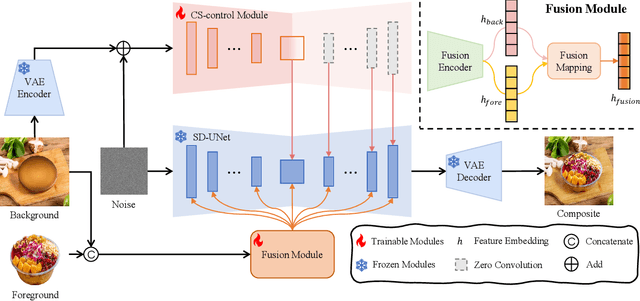
Food image composition requires the use of existing dish images and background images to synthesize a natural new image, while diffusion models have made significant advancements in image generation, enabling the construction of end-to-end architectures that yield promising results. However, existing diffusion models face challenges in processing and fusing information from multiple images and lack access to high-quality publicly available datasets, which prevents the application of diffusion models in food image composition. In this paper, we introduce a large-scale, high-quality food image composite dataset, FC22k, which comprises 22,000 foreground, background, and ground truth ternary image pairs. Additionally, we propose a novel food image composition method, Foodfusion, which leverages the capabilities of the pre-trained diffusion models and incorporates a Fusion Module for processing and integrating foreground and background information. This fused information aligns the foreground features with the background structure by merging the global structural information at the cross-attention layer of the denoising UNet. To further enhance the content and structure of the background, we also integrate a Content-Structure Control Module. Extensive experiments demonstrate the effectiveness and scalability of our proposed method.
One Step Diffusion-based Super-Resolution with Time-Aware Distillation
Aug 14, 2024Diffusion-based image super-resolution (SR) methods have shown promise in reconstructing high-resolution images with fine details from low-resolution counterparts. However, these approaches typically require tens or even hundreds of iterative samplings, resulting in significant latency. Recently, techniques have been devised to enhance the sampling efficiency of diffusion-based SR models via knowledge distillation. Nonetheless, when aligning the knowledge of student and teacher models, these solutions either solely rely on pixel-level loss constraints or neglect the fact that diffusion models prioritize varying levels of information at different time steps. To accomplish effective and efficient image super-resolution, we propose a time-aware diffusion distillation method, named TAD-SR. Specifically, we introduce a novel score distillation strategy to align the data distribution between the outputs of the student and teacher models after minor noise perturbation. This distillation strategy enables the student network to concentrate more on the high-frequency details. Furthermore, to mitigate performance limitations stemming from distillation, we integrate a latent adversarial loss and devise a time-aware discriminator that leverages diffusion priors to effectively distinguish between real images and generated images. Extensive experiments conducted on synthetic and real-world datasets demonstrate that the proposed method achieves comparable or even superior performance compared to both previous state-of-the-art (SOTA) methods and the teacher model in just one sampling step. Codes are available at https://github.com/LearningHx/TAD-SR.
InstructBrush: Learning Attention-based Instruction Optimization for Image Editing
Mar 27, 2024



In recent years, instruction-based image editing methods have garnered significant attention in image editing. However, despite encompassing a wide range of editing priors, these methods are helpless when handling editing tasks that are challenging to accurately describe through language. We propose InstructBrush, an inversion method for instruction-based image editing methods to bridge this gap. It extracts editing effects from exemplar image pairs as editing instructions, which are further applied for image editing. Two key techniques are introduced into InstructBrush, Attention-based Instruction Optimization and Transformation-oriented Instruction Initialization, to address the limitations of the previous method in terms of inversion effects and instruction generalization. To explore the ability of instruction inversion methods to guide image editing in open scenarios, we establish a TransformationOriented Paired Benchmark (TOP-Bench), which contains a rich set of scenes and editing types. The creation of this benchmark paves the way for further exploration of instruction inversion. Quantitatively and qualitatively, our approach achieves superior performance in editing and is more semantically consistent with the target editing effects.
Bridging Generative and Discriminative Models for Unified Visual Perception with Diffusion Priors
Jan 29, 2024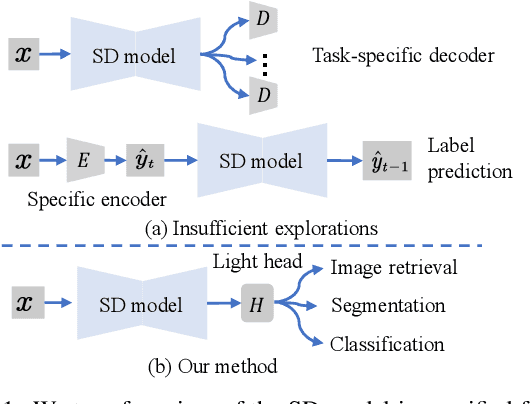
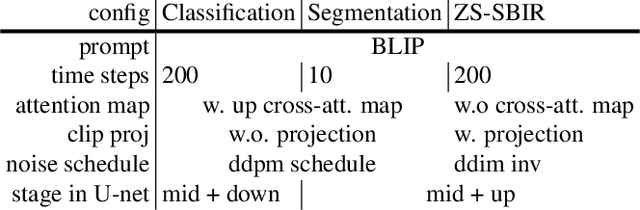
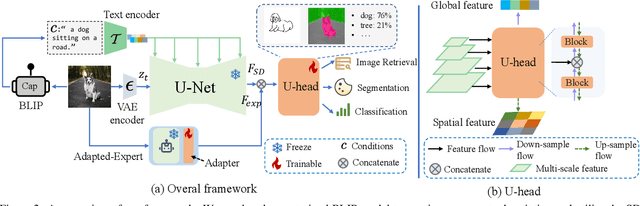
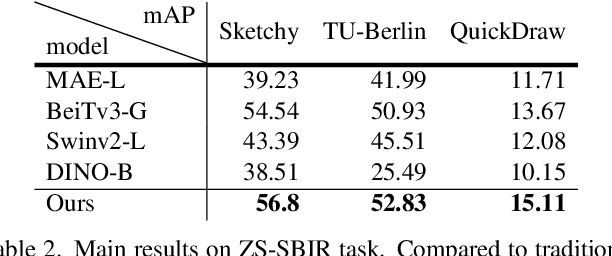
The remarkable prowess of diffusion models in image generation has spurred efforts to extend their application beyond generative tasks. However, a persistent challenge exists in lacking a unified approach to apply diffusion models to visual perception tasks with diverse semantic granularity requirements. Our purpose is to establish a unified visual perception framework, capitalizing on the potential synergies between generative and discriminative models. In this paper, we propose Vermouth, a simple yet effective framework comprising a pre-trained Stable Diffusion (SD) model containing rich generative priors, a unified head (U-head) capable of integrating hierarchical representations, and an adapted expert providing discriminative priors. Comprehensive investigations unveil potential characteristics of Vermouth, such as varying granularity of perception concealed in latent variables at distinct time steps and various U-net stages. We emphasize that there is no necessity for incorporating a heavyweight or intricate decoder to transform diffusion models into potent representation learners. Extensive comparative evaluations against tailored discriminative models showcase the efficacy of our approach on zero-shot sketch-based image retrieval (ZS-SBIR), few-shot classification, and open-vocabulary semantic segmentation tasks. The promising results demonstrate the potential of diffusion models as formidable learners, establishing their significance in furnishing informative and robust visual representations.
CatVersion: Concatenating Embeddings for Diffusion-Based Text-to-Image Personalization
Nov 30, 2023
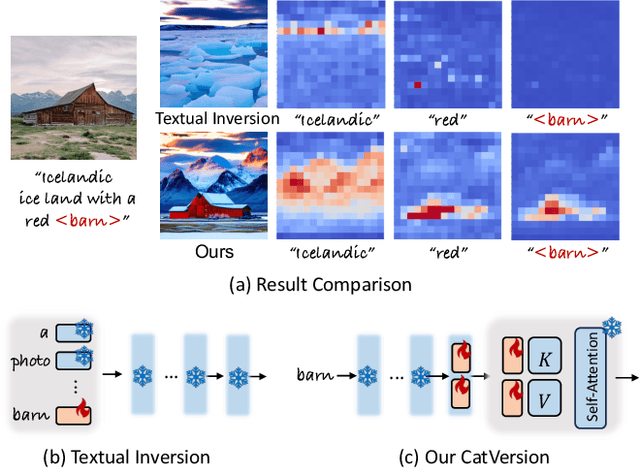
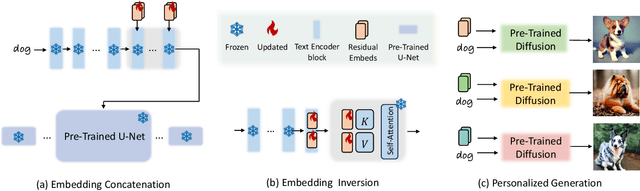
We propose CatVersion, an inversion-based method that learns the personalized concept through a handful of examples. Subsequently, users can utilize text prompts to generate images that embody the personalized concept, thereby achieving text-to-image personalization. In contrast to existing approaches that emphasize word embedding learning or parameter fine-tuning for the diffusion model, which potentially causes concept dilution or overfitting, our method concatenates embeddings on the feature-dense space of the text encoder in the diffusion model to learn the gap between the personalized concept and its base class, aiming to maximize the preservation of prior knowledge in diffusion models while restoring the personalized concepts. To this end, we first dissect the text encoder's integration in the image generation process to identify the feature-dense space of the encoder. Afterward, we concatenate embeddings on the Keys and Values in this space to learn the gap between the personalized concept and its base class. In this way, the concatenated embeddings ultimately manifest as a residual on the original attention output. To more accurately and unbiasedly quantify the results of personalized image generation, we improve the CLIP image alignment score based on masks. Qualitatively and quantitatively, CatVersion helps to restore personalization concepts more faithfully and enables more robust editing.
HFORD: High-Fidelity and Occlusion-Robust De-identification for Face Privacy Protection
Nov 15, 2023


With the popularity of smart devices and the development of computer vision technology, concerns about face privacy protection are growing. The face de-identification technique is a practical way to solve the identity protection problem. The existing facial de-identification methods have revealed several problems, including the impact on the realism of anonymized results when faced with occlusions and the inability to maintain identity-irrelevant details in anonymized results. We present a High-Fidelity and Occlusion-Robust De-identification (HFORD) method to deal with these issues. This approach can disentangle identities and attributes while preserving image-specific details such as background, facial features (e.g., wrinkles), and lighting, even in occluded scenes. To disentangle the latent codes in the GAN inversion space, we introduce an Identity Disentanglement Module (IDM). This module selects the latent codes that are closely related to the identity. It further separates the latent codes into identity-related codes and attribute-related codes, enabling the network to preserve attributes while only modifying the identity. To ensure the preservation of image details and enhance the network's robustness to occlusions, we propose an Attribute Retention Module (ARM). This module adaptively preserves identity-irrelevant details and facial occlusions and blends them into the generated results in a modulated manner. Extensive experiments show that our method has higher quality, better detail fidelity, and stronger occlusion robustness than other face de-identification methods.
Diff-Privacy: Diffusion-based Face Privacy Protection
Sep 11, 2023
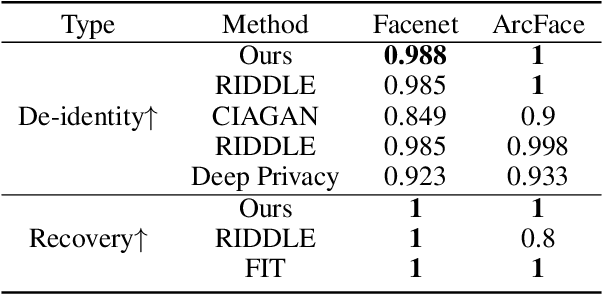
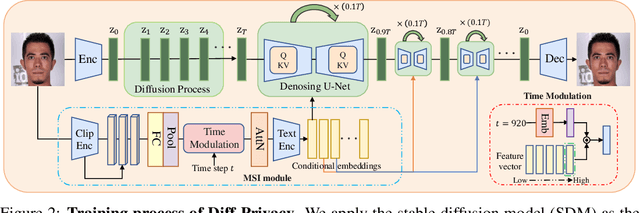
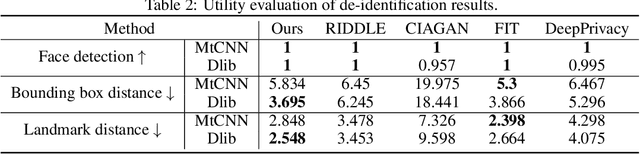
Privacy protection has become a top priority as the proliferation of AI techniques has led to widespread collection and misuse of personal data. Anonymization and visual identity information hiding are two important facial privacy protection tasks that aim to remove identification characteristics from facial images at the human perception level. However, they have a significant difference in that the former aims to prevent the machine from recognizing correctly, while the latter needs to ensure the accuracy of machine recognition. Therefore, it is difficult to train a model to complete these two tasks simultaneously. In this paper, we unify the task of anonymization and visual identity information hiding and propose a novel face privacy protection method based on diffusion models, dubbed Diff-Privacy. Specifically, we train our proposed multi-scale image inversion module (MSI) to obtain a set of SDM format conditional embeddings of the original image. Based on the conditional embeddings, we design corresponding embedding scheduling strategies and construct different energy functions during the denoising process to achieve anonymization and visual identity information hiding. Extensive experiments have been conducted to validate the effectiveness of our proposed framework in protecting facial privacy.
Adapt and Align to Improve Zero-Shot Sketch-Based Image Retrieval
May 18, 2023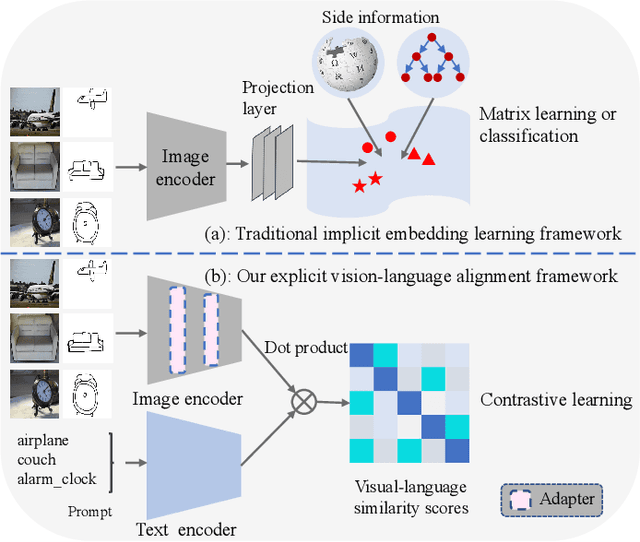
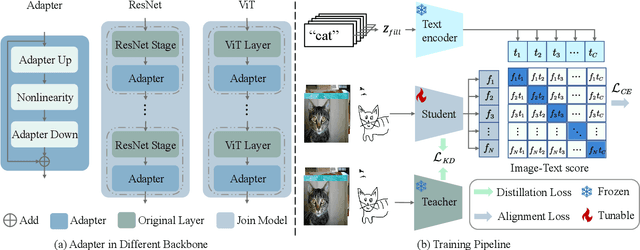
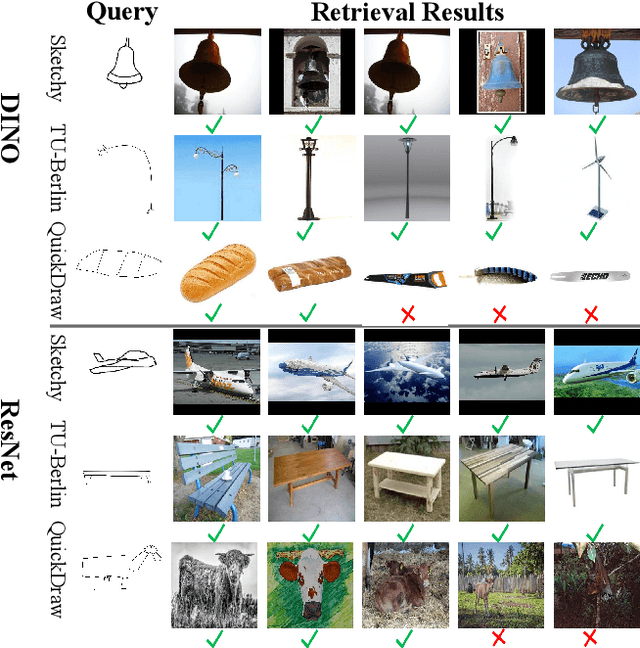
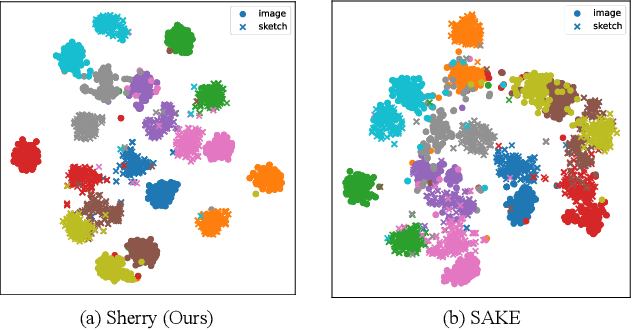
Zero-shot sketch-based image retrieval (ZS-SBIR) is challenging due to the cross-domain nature of sketches and photos, as well as the semantic gap between seen and unseen image distributions. Previous methods fine-tune pre-trained models with various side information and learning strategies to learn a compact feature space that is shared between the sketch and photo domains and bridges seen and unseen classes. However, these efforts are inadequate in adapting domains and transferring knowledge from seen to unseen classes. In this paper, we present an effective ``Adapt and Align'' approach to address the key challenges. Specifically, we insert simple and lightweight domain adapters to learn new abstract concepts of the sketch domain and improve cross-domain representation capabilities. Inspired by recent advances in image-text foundation models (e.g., CLIP) on zero-shot scenarios, we explicitly align the learned image embedding with a more semantic text embedding to achieve the desired knowledge transfer from seen to unseen classes. Extensive experiments on three benchmark datasets and two popular backbones demonstrate the superiority of our method in terms of retrieval accuracy and flexibility.