 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Diffusion Transformer Architecture for Image Super-Resolution
Paper and Code
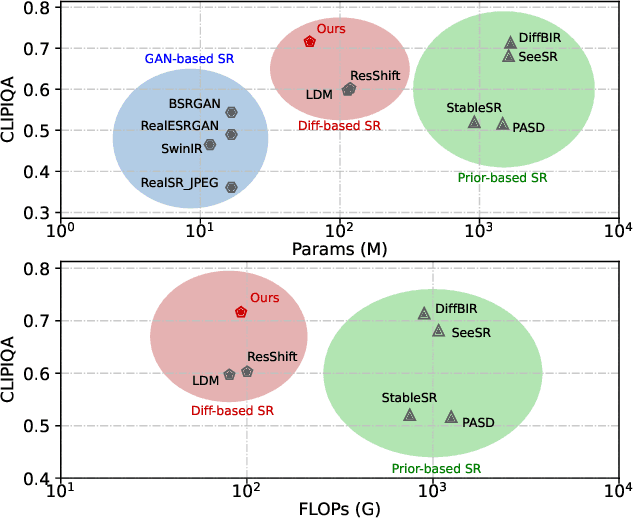
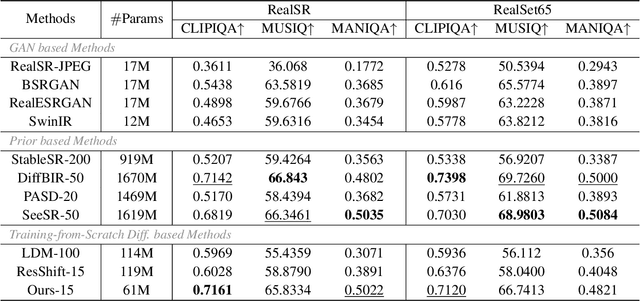


Recent advances indicate that diffusion models hold great promise in image super-resolution. While the latest methods are primarily based on latent diffusion models with convolutional neural networks, there are few attempts to explore transformers, which have demonstrated remarkable performance in image generation. In this work, we design an effective diffusion transformer for image super-resolution (DiT-SR) that achieves the visual quality of prior-based methods, but through a training-from-scratch manner. In practice, DiT-SR leverages an overall U-shaped architecture, and adopts a uniform isotropic design for all the transformer blocks across different stages. The former facilitates multi-scale hierarchical feature extraction, while the latter reallocates the computational resources to critical layers to further enhance performance. Moreover, we thoroughly analyze the limitation of the widely used AdaLN, and present a frequency-adaptive time-step conditioning module, enhancing the model's capacity to process distinct frequency information at different time steps. Extensive experiments demonstrate that DiT-SR outperforms the existing training-from-scratch diffusion-based SR methods significantly, and even beats some of the prior-based methods on pretrained Stable Diffusion, proving the superiority of diffusion transformer in image super-resolution.