 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking 1-bit Optimization Leveraging Pre-trained Large Language Models
Aug 09, 2025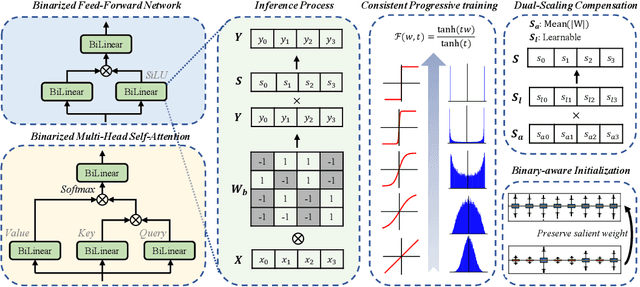

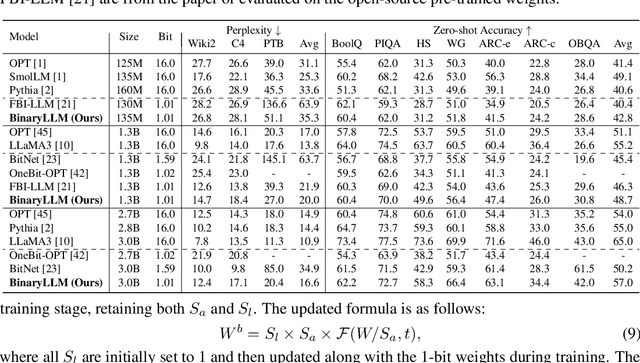
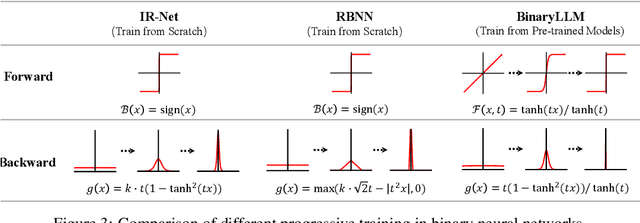
1-bit LLM quantization offers significant advantages in reducing storage and computational costs. However, existing methods typically train 1-bit LLMs from scratch, failing to fully leverage pre-trained models. This results in high training costs and notable accuracy degradation. We identify that the large gap between full precision and 1-bit representations makes direct adaptation difficult. In this paper, we introduce a consistent progressive training for both forward and backward, smoothly converting the floating-point weights into the binarized ones. Additionally, we incorporate binary-aware initialization and dual-scaling compensation to reduce the difficulty of progressive training and improve the performance. Experimental results on LLMs of various sizes demonstrate that our method outperforms existing approaches. Our results show that high-performance 1-bit LLMs can be achieved using pre-trained models, eliminating the need for expensive training from scratch.
Autoregressive Image Generation Guided by Chains of Thought
Feb 26, 2025In the field of autoregressive (AR) image generation, models based on the 'next-token prediction' paradigm of LLMs have shown comparable performance to diffusion models by reducing inductive biases. However, directly applying LLMs to complex image generation can struggle with reconstructing the structure and details of the image, impacting the accuracy and stability of generation. Additionally, the 'next-token prediction' paradigm in the AR model does not align with the contextual scanning and logical reasoning processes involved in human visual perception, limiting effective image generation. Chain-of-Thought (CoT), as a key reasoning capability of LLMs, utilizes reasoning prompts to guide the model, improving reasoning performance on complex natural language process (NLP) tasks, enhancing accuracy and stability of generation, and helping the model maintain contextual coherence and logical consistency, similar to human reasoning. Inspired by CoT from the field of NLP, we propose autoregressive Image Generation with Thoughtful Reasoning (IGTR) to enhance autoregressive image generation. IGTR adds reasoning prompts without modifying the model structure or raster generation order. Specifically, we design specialized image-related reasoning prompts for AR image generation to simulate the human reasoning process, which enhances contextual reasoning by allowing the model to first perceive overall distribution information before generating the image, and improve generation stability by increasing the inference steps. Compared to the AR method without prompts, our method shows outstanding performance and achieves an approximate improvement of 20%.
Effective Diffusion Transformer Architecture for Image Super-Resolution
Sep 29, 2024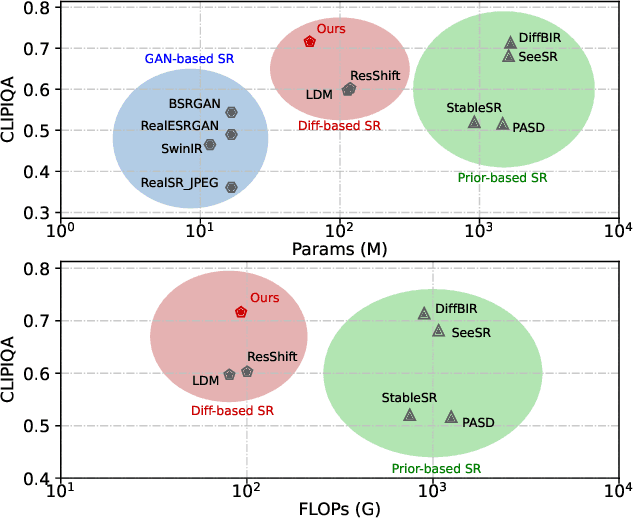
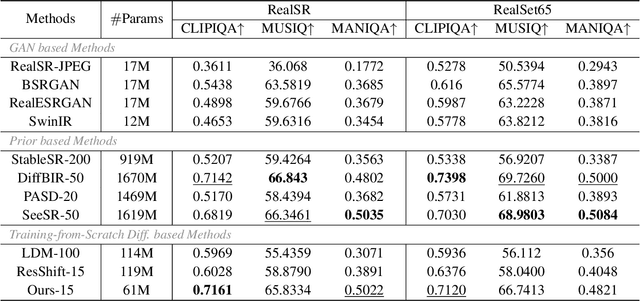


Recent advances indicate that diffusion models hold great promise in image super-resolution. While the latest methods are primarily based on latent diffusion models with convolutional neural networks, there are few attempts to explore transformers, which have demonstrated remarkable performance in image generation. In this work, we design an effective diffusion transformer for image super-resolution (DiT-SR) that achieves the visual quality of prior-based methods, but through a training-from-scratch manner. In practice, DiT-SR leverages an overall U-shaped architecture, and adopts a uniform isotropic design for all the transformer blocks across different stages. The former facilitates multi-scale hierarchical feature extraction, while the latter reallocates the computational resources to critical layers to further enhance performance. Moreover, we thoroughly analyze the limitation of the widely used AdaLN, and present a frequency-adaptive time-step conditioning module, enhancing the model's capacity to process distinct frequency information at different time steps. Extensive experiments demonstrate that DiT-SR outperforms the existing training-from-scratch diffusion-based SR methods significantly, and even beats some of the prior-based methods on pretrained Stable Diffusion, proving the superiority of diffusion transformer in image super-resolution.
One Step Diffusion-based Super-Resolution with Time-Aware Distillation
Aug 14, 2024Diffusion-based image super-resolution (SR) methods have shown promise in reconstructing high-resolution images with fine details from low-resolution counterparts. However, these approaches typically require tens or even hundreds of iterative samplings, resulting in significant latency. Recently, techniques have been devised to enhance the sampling efficiency of diffusion-based SR models via knowledge distillation. Nonetheless, when aligning the knowledge of student and teacher models, these solutions either solely rely on pixel-level loss constraints or neglect the fact that diffusion models prioritize varying levels of information at different time steps. To accomplish effective and efficient image super-resolution, we propose a time-aware diffusion distillation method, named TAD-SR. Specifically, we introduce a novel score distillation strategy to align the data distribution between the outputs of the student and teacher models after minor noise perturbation. This distillation strategy enables the student network to concentrate more on the high-frequency details. Furthermore, to mitigate performance limitations stemming from distillation, we integrate a latent adversarial loss and devise a time-aware discriminator that leverages diffusion priors to effectively distinguish between real images and generated images. Extensive experiments conducted on synthetic and real-world datasets demonstrate that the proposed method achieves comparable or even superior performance compared to both previous state-of-the-art (SOTA) methods and the teacher model in just one sampling step. Codes are available at https://github.com/LearningHx/TAD-SR.
U-DiTs: Downsample Tokens in U-Shaped Diffusion Transformers
May 04, 2024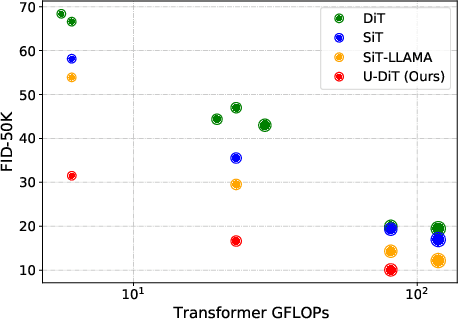
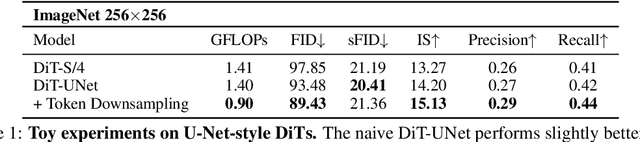
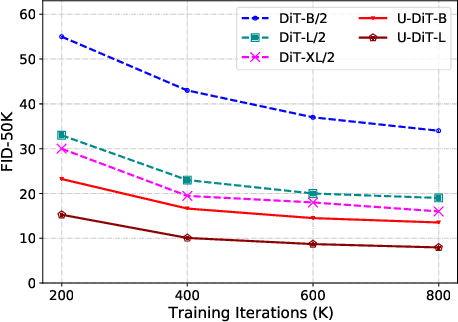
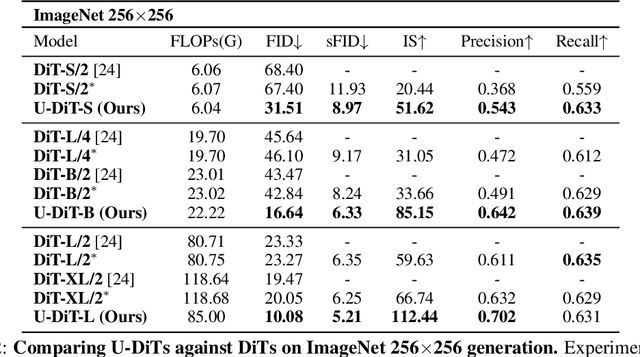
Diffusion Transformers (DiTs) introduce the transformer architecture to diffusion tasks for latent-space image generation. With an isotropic architecture that chains a series of transformer blocks, DiTs demonstrate competitive performance and good scalability; but meanwhile, the abandonment of U-Net by DiTs and their following improvements is worth rethinking. To this end, we conduct a simple toy experiment by comparing a U-Net architectured DiT with an isotropic one. It turns out that the U-Net architecture only gain a slight advantage amid the U-Net inductive bias, indicating potential redundancies within the U-Net-style DiT. Inspired by the discovery that U-Net backbone features are low-frequency-dominated, we perform token downsampling on the query-key-value tuple for self-attention and bring further improvements despite a considerable amount of reduction in computation. Based on self-attention with downsampled tokens, we propose a series of U-shaped DiTs (U-DiTs) in the paper and conduct extensive experiments to demonstrate the extraordinary performance of U-DiT models. The proposed U-DiT could outperform DiT-XL/2 with only 1/6 of its computation cost. Codes are available at https://github.com/YuchuanTian/U-DiT.
LIPT: Latency-aware Image Processing Transformer
Apr 09, 2024Transformer is leading a trend in the field of image processing. Despite the great success that existing lightweight image processing transformers have achieved, they are tailored to FLOPs or parameters reduction, rather than practical inference acceleration. In this paper, we present a latency-aware image processing transformer, termed LIPT. We devise the low-latency proportion LIPT block that substitutes memory-intensive operators with the combination of self-attention and convolutions to achieve practical speedup. Specifically, we propose a novel non-volatile sparse masking self-attention (NVSM-SA) that utilizes a pre-computing sparse mask to capture contextual information from a larger window with no extra computation overload. Besides, a high-frequency reparameterization module (HRM) is proposed to make LIPT block reparameterization friendly, which improves the model's detail reconstruction capability. Extensive experiments on multiple image processing tasks (e.g., image super-resolution (SR), JPEG artifact reduction, and image denoising) demonstrate the superiority of LIPT on both latency and PSNR. LIPT achieves real-time GPU inference with state-of-the-art performance on multiple image SR benchmarks.
IPT-V2: Efficient Image Processing Transformer using Hierarchical Attentions
Mar 31, 2024
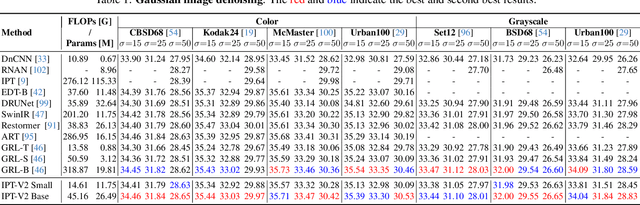
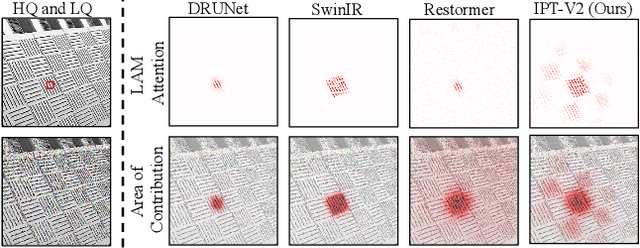

Recent advances have demonstrated the powerful capability of transformer architecture in image restoration. However, our analysis indicates that existing transformerbased methods can not establish both exact global and local dependencies simultaneously, which are much critical to restore the details and missing content of degraded images. To this end, we present an efficient image processing transformer architecture with hierarchical attentions, called IPTV2, adopting a focal context self-attention (FCSA) and a global grid self-attention (GGSA) to obtain adequate token interactions in local and global receptive fields. Specifically, FCSA applies the shifted window mechanism into the channel self-attention, helps capture the local context and mutual interaction across channels. And GGSA constructs long-range dependencies in the cross-window grid, aggregates global information in spatial dimension. Moreover, we introduce structural re-parameterization technique to feed-forward network to further improve the model capability. Extensive experiments demonstrate that our proposed IPT-V2 achieves state-of-the-art results on various image processing tasks, covering denoising, deblurring, deraining and obtains much better trade-off for performance and computational complexity than previous methods. Besides, we extend our method to image generation as latent diffusion backbone, and significantly outperforms DiTs.
A Survey on Transformer Compression
Feb 05, 2024



Large models based on the Transformer architecture play increasingly vital roles in artificial intelligence, particularly within the realms of natural language processing (NLP) and computer vision (CV). Model compression methods reduce their memory and computational cost, which is a necessary step to implement the transformer models on practical devices. Given the unique architecture of transformer, featuring alternative attention and Feedforward Neural Network (FFN) modules, specific compression techniques are required. The efficiency of these compression methods is also paramount, as it is usually impractical to retrain large models on the entire training dataset.This survey provides a comprehensive review of recent compression methods, with a specific focus on their application to transformer models. The compression methods are primarily categorized into pruning, quantization, knowledge distillation, and efficient architecture design. In each category, we discuss compression methods for both CV and NLP tasks, highlighting common underlying principles. At last, we delve into the relation between various compression methods, and discuss the further directions in this domain.
CBQ: Cross-Block Quantization for Large Language Models
Dec 13, 2023



Post-training quantization (PTQ) has driven attention to producing efficient large language models (LLMs) with ultra-low costs. Since hand-craft quantization parameters lead to low performance in low-bit quantization, recent methods optimize the quantization parameters through block-wise reconstruction between the floating-point and quantized models. However, these methods suffer from two challenges: accumulated errors from independent one-by-one block quantization and reconstruction difficulties from extreme weight and activation outliers. To address these two challenges, we propose CBQ, a cross-block reconstruction-based PTQ method for LLMs. To reduce error accumulation, we introduce a cross-block dependency with the aid of a homologous reconstruction scheme to build the long-range dependency between adjacent multi-blocks with overlapping. To reduce reconstruction difficulty, we design a coarse-to-fine pre-processing (CFP) to truncate weight outliers and dynamically scale activation outliers before optimization, and an adaptive rounding scheme, called LoRA-Rounding, with two low-rank learnable matrixes to further rectify weight quantization errors. Extensive experiments demonstrate that: (1) CBQ pushes both activation and weight quantization to low-bit settings W4A4, W4A8, and W2A16. (2) CBQ achieves better performance than the existing state-of-the-art methods on various LLMs and benchmark datasets.
Data Upcycling Knowledge Distillation for Image Super-Resolution
Sep 25, 2023Knowledge distillation (KD) emerges as a challenging yet promising technique for compressing deep learning models, characterized by the transmission of extensive learning representations from proficient and computationally intensive teacher models to compact student models. However, only a handful of studies have endeavored to compress the models for single image super-resolution (SISR) through KD, with their effects on student model enhancement remaining marginal. In this paper, we put forth an approach from the perspective of efficient data utilization, namely, the Data Upcycling Knowledge Distillation (DUKD) which facilitates the student model by the prior knowledge teacher provided via upcycled in-domain data derived from their inputs. This upcycling process is realized through two efficient image zooming operations and invertible data augmentations which introduce the label consistency regularization to the field of KD for SISR and substantially boosts student model's generalization. The DUKD, due to its versatility, can be applied across a broad spectrum of teacher-student architectures. Comprehensive experiments across diverse benchmarks demonstrate that our proposed DUKD method significantly outperforms previous art, exemplified by an increase of up to 0.5dB in PSNR over baselines methods, and a 67% parameters reduced RCAN model's performance remaining on par with that of the RCAN teacher model.