 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop 10 Open Challenges Steering the Future of Diffusion Language Model and Its Variants
Jan 20, 2026The paradigm of Large Language Models (LLMs) is currently defined by auto-regressive (AR) architectures, which generate text through a sequential ``brick-by-brick'' process. Despite their success, AR models are inherently constrained by a causal bottleneck that limits global structural foresight and iterative refinement. Diffusion Language Models (DLMs) offer a transformative alternative, conceptualizing text generation as a holistic, bidirectional denoising process akin to a sculptor refining a masterpiece. However, the potential of DLMs remains largely untapped as they are frequently confined within AR-legacy infrastructures and optimization frameworks. In this Perspective, we identify ten fundamental challenges ranging from architectural inertia and gradient sparsity to the limitations of linear reasoning that prevent DLMs from reaching their ``GPT-4 moment''. We propose a strategic roadmap organized into four pillars: foundational infrastructure, algorithmic optimization, cognitive reasoning, and unified multimodal intelligence. By shifting toward a diffusion-native ecosystem characterized by multi-scale tokenization, active remasking, and latent thinking, we can move beyond the constraints of the causal horizon. We argue that this transition is essential for developing next-generation AI capable of complex structural reasoning, dynamic self-correction, and seamless multimodal integration.
Deferred Commitment Decoding for Diffusion Language Models with Confidence-Aware Sliding Windows
Jan 05, 2026Diffusion language models (DLMs) have recently emerged as a strong alternative to autoregressive models by enabling parallel text generation. To improve inference efficiency and KV-cache compatibility, prior work commonly adopts block-based diffusion, decoding tokens block by block. However, this paradigm suffers from a structural limitation that we term Boundary-Induced Context Truncation (BICT): undecoded tokens near block boundaries are forced to commit without access to nearby future context, even when such context could substantially reduce uncertainty. This limitation degrades decoding confidence and generation quality, especially for tasks requiring precise reasoning, such as mathematical problem solving and code generation. We propose Deferred Commitment Decoding (DCD), a novel, training-free decoding strategy that mitigates this issue. DCD maintains a confidence-aware sliding window over masked tokens, resolving low-uncertainty tokens early while deferring high-uncertainty tokens until sufficient contextual evidence becomes available. This design enables effective bidirectional information flow within the decoding window without sacrificing efficiency. Extensive experiments across multiple diffusion language models, benchmarks, and caching configurations show that DCD improves generation accuracy by 1.39% with comparable time on average compared to fixed block-based diffusion methods, with the most significant improvement reaching 9.0%. These results demonstrate that deferring token commitment based on uncertainty is a simple yet effective principle for improving both the quality and efficiency of diffusion language model decoding.
Circle-RoPE: Cone-like Decoupled Rotary Positional Embedding for Large Vision-Language Models
May 22, 2025Rotary Position Embedding (RoPE) is a widely adopted technique for encoding relative positional information in large language models (LLMs). However, when extended to large vision-language models (LVLMs), its variants introduce unintended cross-modal positional biases. Specifically, they enforce relative positional dependencies between text token indices and image tokens, causing spurious alignments. This issue arises because image tokens representing the same content but located at different spatial positions are assigned distinct positional biases, leading to inconsistent cross-modal associations. To address this, we propose Per-Token Distance (PTD) - a simple yet effective metric for quantifying the independence of positional encodings across modalities. Informed by this analysis, we introduce Circle-RoPE, a novel encoding scheme that maps image token indices onto a circular trajectory orthogonal to the linear path of text token indices, forming a cone-like structure. This configuration ensures that each text token maintains an equal distance to all image tokens, reducing artificial cross-modal biases while preserving intra-image spatial information. To further enhance performance, we propose a staggered layer strategy that applies different RoPE variants across layers. This design leverages the complementary strengths of each RoPE variant, thereby enhancing the model's overall performance. Our experimental results demonstrate that our method effectively preserves spatial information from images while reducing relative positional bias, offering a more robust and flexible positional encoding framework for LVLMs. The code is available at [https://github.com/lose4578/CircleRoPE](https://github.com/lose4578/CircleRoPE).
Post-Training Quantization for Diffusion Transformer via Hierarchical Timestep Grouping
Mar 10, 2025



Diffusion Transformer (DiT) has now become the preferred choice for building image generation models due to its great generation capability. Unlike previous convolution-based UNet models, DiT is purely composed of a stack of transformer blocks, which renders DiT excellent in scalability like large language models. However, the growing model size and multi-step sampling paradigm bring about considerable pressure on deployment and inference. In this work, we propose a post-training quantization framework tailored for Diffusion Transforms to tackle these challenges. We firstly locate that the quantization difficulty of DiT mainly originates from the time-dependent channel-specific outliers. We propose a timestep-aware shift-and-scale strategy to smooth the activation distribution to reduce the quantization error. Secondly, based on the observation that activations of adjacent timesteps have similar distributions, we utilize a hierarchical clustering scheme to divide the denoising timesteps into multiple groups. We further design a re-parameterization scheme which absorbs the quantization parameters into nearby module to avoid redundant computations. Comprehensive experiments demonstrate that out PTQ method successfully quantize the Diffusion Transformer into 8-bit weight and 8-bit activation (W8A8) with state-of-the-art FiD score. And our method can further quantize DiT model into 4-bit weight and 8-bit activation (W4A8) without sacrificing generation quality.
DiC: Rethinking Conv3x3 Designs in Diffusion Models
Dec 31, 2024



Diffusion models have shown exceptional performance in visual generation tasks. Recently, these models have shifted from traditional U-Shaped CNN-Attention hybrid structures to fully transformer-based isotropic architectures. While these transformers exhibit strong scalability and performance, their reliance on complicated self-attention operation results in slow inference speeds. Contrary to these works, we rethink one of the simplest yet fastest module in deep learning, 3x3 Convolution, to construct a scaled-up purely convolutional diffusion model. We first discover that an Encoder-Decoder Hourglass design outperforms scalable isotropic architectures for Conv3x3, but still under-performing our expectation. Further improving the architecture, we introduce sparse skip connections to reduce redundancy and improve scalability. Based on the architecture, we introduce conditioning improvements including stage-specific embeddings, mid-block condition injection, and conditional gating. These improvements lead to our proposed Diffusion CNN (DiC), which serves as a swift yet competitive diffusion architecture baseline. Experiments on various scales and settings show that DiC surpasses existing diffusion transformers by considerable margins in terms of performance while keeping a good speed advantage. Project page: https://github.com/YuchuanTian/DiC
Learning Quantized Adaptive Conditions for Diffusion Models
Sep 26, 2024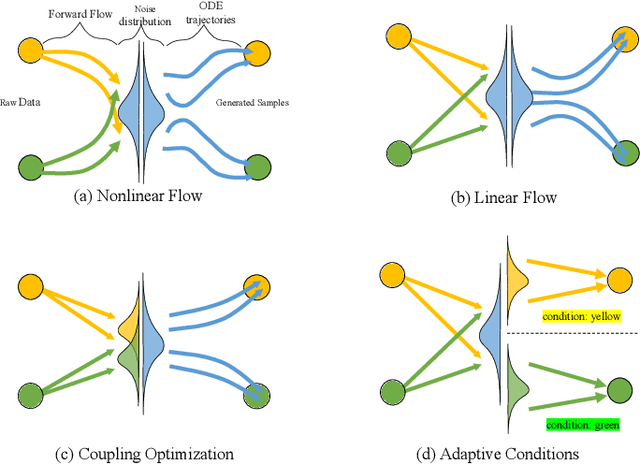

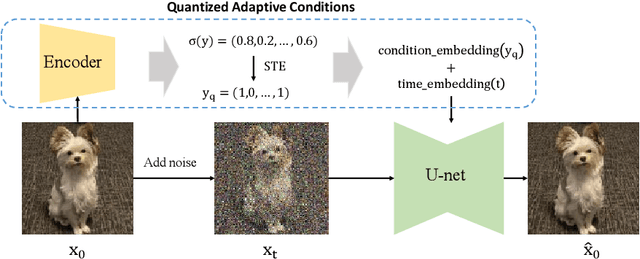

The curvature of ODE trajectories in diffusion models hinders their ability to generate high-quality images in a few number of function evaluations (NFE). In this paper, we propose a novel and effective approach to reduce trajectory curvature by utilizing adaptive conditions. By employing a extremely light-weight quantized encoder, our method incurs only an additional 1% of training parameters, eliminates the need for extra regularization terms, yet achieves significantly better sample quality. Our approach accelerates ODE sampling while preserving the downstream task image editing capabilities of SDE techniques. Extensive experiments verify that our method can generate high quality results under extremely limited sampling costs. With only 6 NFE, we achieve 5.14 FID on CIFAR-10, 6.91 FID on FFHQ 64x64 and 3.10 FID on AFHQv2.
Instruct-IPT: All-in-One Image Processing Transformer via Weight Modulation
Jun 30, 2024



Due to the unaffordable size and intensive computation costs of low-level vision models, All-in-One models that are designed to address a handful of low-level vision tasks simultaneously have been popular. However, existing All-in-One models are limited in terms of the range of tasks and performance. To overcome these limitations, we propose Instruct-IPT -- an All-in-One Image Processing Transformer that could effectively address manifold image restoration tasks with large inter-task gaps, such as denoising, deblurring, deraining, dehazing, and desnowing. Rather than popular feature adaptation methods, we propose weight modulation that adapts weights to specific tasks. Firstly, we figure out task-sensitive weights via a toy experiment and introduce task-specific biases on top of them. Secondly, we conduct rank analysis for a good compression strategy and perform low-rank decomposition on the biases. Thirdly, we propose synchronous training that updates the task-general backbone model and the task-specific biases simultaneously. In this way, the model is instructed to learn general and task-specific knowledge. Via our simple yet effective method that instructs the IPT to be task experts, Instruct-IPT could better cooperate between tasks with distinct characteristics at humble costs. Further, we propose to maneuver Instruct-IPT with text instructions for better user interfaces. We have conducted experiments on Instruct-IPT to demonstrate the effectiveness of our method on manifold tasks, and we have effectively extended our method to diffusion denoisers as well. The code is available at https://github.com/huawei-noah/Pretrained-IPT.
U-DiTs: Downsample Tokens in U-Shaped Diffusion Transformers
May 04, 2024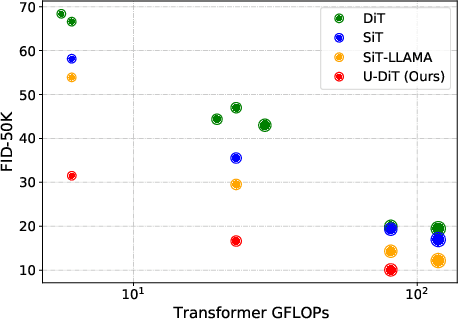
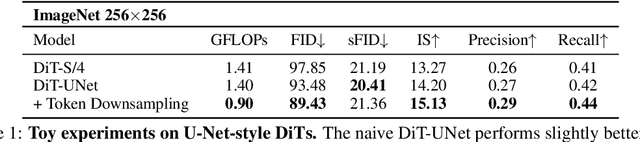
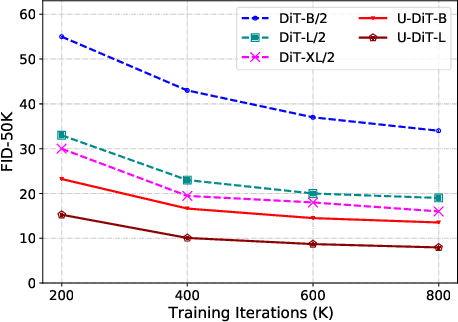
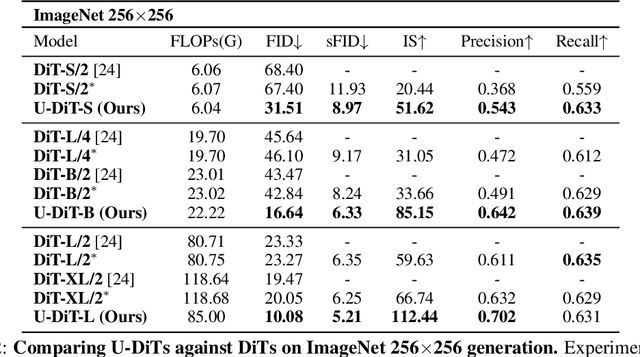
Diffusion Transformers (DiTs) introduce the transformer architecture to diffusion tasks for latent-space image generation. With an isotropic architecture that chains a series of transformer blocks, DiTs demonstrate competitive performance and good scalability; but meanwhile, the abandonment of U-Net by DiTs and their following improvements is worth rethinking. To this end, we conduct a simple toy experiment by comparing a U-Net architectured DiT with an isotropic one. It turns out that the U-Net architecture only gain a slight advantage amid the U-Net inductive bias, indicating potential redundancies within the U-Net-style DiT. Inspired by the discovery that U-Net backbone features are low-frequency-dominated, we perform token downsampling on the query-key-value tuple for self-attention and bring further improvements despite a considerable amount of reduction in computation. Based on self-attention with downsampled tokens, we propose a series of U-shaped DiTs (U-DiTs) in the paper and conduct extensive experiments to demonstrate the extraordinary performance of U-DiT models. The proposed U-DiT could outperform DiT-XL/2 with only 1/6 of its computation cost. Codes are available at https://github.com/YuchuanTian/U-DiT.
DiJiang: Efficient Large Language Models through Compact Kernelization
Apr 01, 2024



In an effort to reduce the computational load of Transformers, research on linear attention has gained significant momentum. However, the improvement strategies for attention mechanisms typically necessitate extensive retraining, which is impractical for large language models with a vast array of parameters. In this paper, we present DiJiang, a novel Frequency Domain Kernelization approach that enables the transformation of a pre-trained vanilla Transformer into a linear complexity model with little training costs. By employing a weighted Quasi-Monte Carlo method for sampling, the proposed approach theoretically offers superior approximation efficiency. To further reduce the training computational complexity, our kernelization is based on Discrete Cosine Transform (DCT) operations. Extensive experiments demonstrate that the proposed method achieves comparable performance to the original Transformer, but with significantly reduced training costs and much faster inference speeds. Our DiJiang-7B achieves comparable performance with LLaMA2-7B on various benchmark while requires only about 1/50 training cost. Code is available at https://github.com/YuchuanTian/DiJiang.
Rethinking Optimization and Architecture for Tiny Language Models
Feb 06, 2024



The power of large language models (LLMs) has been demonstrated through numerous data and computing resources. However, the application of language models on mobile devices is facing huge challenge on the computation and memory costs, that is, tiny language models with high performance are urgently required. Limited by the highly complex training process, there are many details for optimizing language models that are seldom studied carefully. In this study, based on a tiny language model with 1B parameters, we carefully design a series of empirical study to analyze the effect of each component. Three perspectives are mainly discussed, \ie, neural architecture, parameter initialization, and optimization strategy. Several design formulas are empirically proved especially effective for tiny language models, including tokenizer compression, architecture tweaking, parameter inheritance and multiple-round training. Then we train PanGu-$\pi$-1B Pro and PanGu-$\pi$-1.5B Pro on 1.6T multilingual corpora, following the established formulas. Experimental results demonstrate the improved optimization and architecture yield a notable average improvement of 8.87 on benchmark evaluation sets for PanGu-$\pi$-1B Pro. Besides, PanGu-$\pi$-1.5B Pro surpasses a range of SOTA models with larger model sizes, validating its superior performance. The code is available at https://github.com/YuchuanTian/RethinkTinyLM.