 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFPC: Towards Efficient and Flexible Prompt Compression
Mar 11, 2025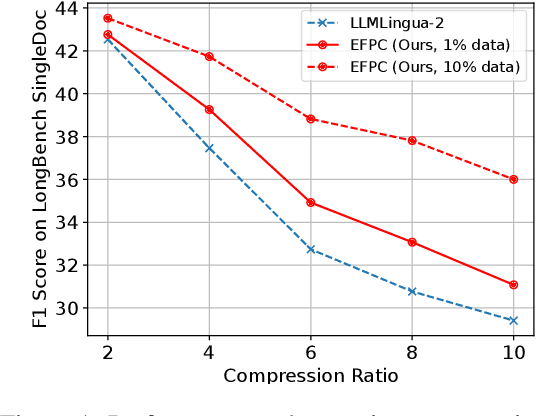
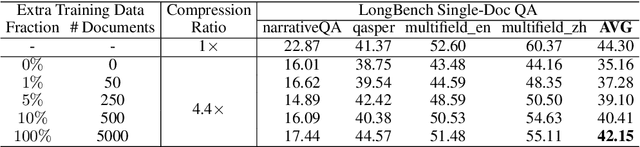

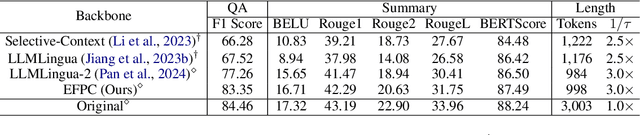
The emergence of large language models (LLMs) like GPT-4 has revolutionized natural language processing (NLP), enabling diverse, complex tasks. However, extensive token counts lead to high computational and financial burdens. To address this, we propose Efficient and Flexible Prompt Compression (EFPC), a novel method unifying task-aware and task-agnostic compression for a favorable accuracy-efficiency trade-off. EFPC uses GPT-4 to generate compressed prompts and integrates them with original prompts for training. During training and inference, we selectively prepend user instructions and compress prompts based on predicted probabilities. EFPC is highly data-efficient, achieving significant performance with minimal data. Compared to the state-of-the-art method LLMLingua-2, EFPC achieves a 4.8% relative improvement in F1-score with 1% additional data at a 4x compression rate, and an 11.4% gain with 10% additional data on the LongBench single-doc QA benchmark. EFPC's unified framework supports broad applicability and enhances performance across various models, tasks, and domains, offering a practical advancement in NLP.
Rethinking Optimization and Architecture for Tiny Language Models
Feb 06, 2024



The power of large language models (LLMs) has been demonstrated through numerous data and computing resources. However, the application of language models on mobile devices is facing huge challenge on the computation and memory costs, that is, tiny language models with high performance are urgently required. Limited by the highly complex training process, there are many details for optimizing language models that are seldom studied carefully. In this study, based on a tiny language model with 1B parameters, we carefully design a series of empirical study to analyze the effect of each component. Three perspectives are mainly discussed, \ie, neural architecture, parameter initialization, and optimization strategy. Several design formulas are empirically proved especially effective for tiny language models, including tokenizer compression, architecture tweaking, parameter inheritance and multiple-round training. Then we train PanGu-$\pi$-1B Pro and PanGu-$\pi$-1.5B Pro on 1.6T multilingual corpora, following the established formulas. Experimental results demonstrate the improved optimization and architecture yield a notable average improvement of 8.87 on benchmark evaluation sets for PanGu-$\pi$-1B Pro. Besides, PanGu-$\pi$-1.5B Pro surpasses a range of SOTA models with larger model sizes, validating its superior performance. The code is available at https://github.com/YuchuanTian/RethinkTinyLM.
Cascaded Algorithm-Selection and Hyper-Parameter Optimization with Extreme-Region Upper Confidence Bound Bandit
May 31, 2019

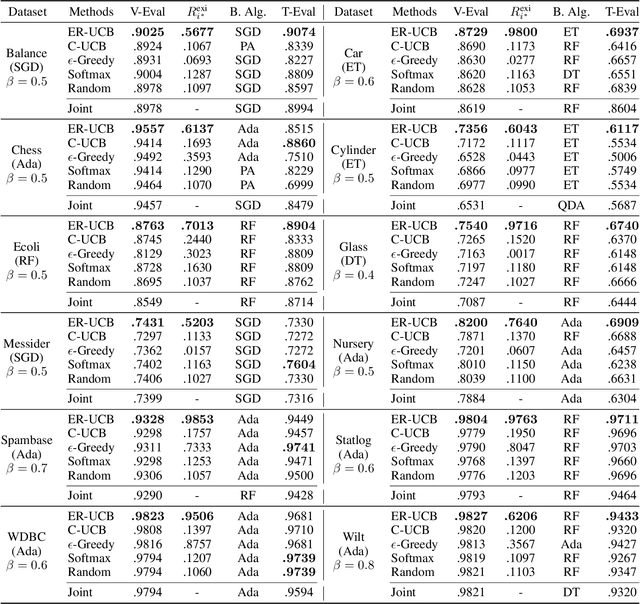
An automatic machine learning (AutoML) task is to select the best algorithm and its hyper-parameters simultaneously. Previously, the hyper-parameters of all algorithms are joint as a single search space, which is not only huge but also redundant, because many dimensions of hyper-parameters are irrelevant with the selected algorithms. In this paper, we propose a cascaded approach for algorithm selection and hyper-parameter optimization. While a search procedure is employed at the level of hyper-parameter optimization, a bandit strategy runs at the level of algorithm selection to allocate the budget based on the search feedbacks. Since the bandit is required to select the algorithm with the maximum performance, instead of the average performance, we thus propose the extreme-region upper confidence bound (ER-UCB) strategy, which focuses on the extreme region of the underlying feedback distribution. We show theoretically that the ER-UCB has a regret upper bound $O\left(K \ln n\right)$ with independent feedbacks, which is as efficient as the classical UCB bandit. We also conduct experiments on a synthetic problem as well as a set of AutoML tasks. The results verify the effectiveness of the proposed method.
ZOOpt: Toolbox for Derivative-Free Optimization
Feb 06, 2018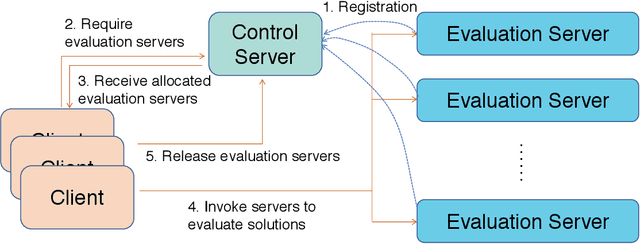
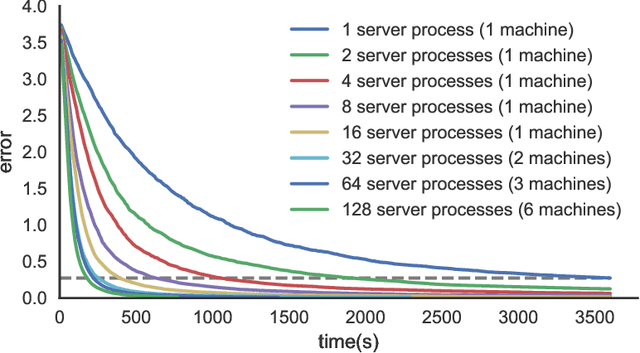
Recent advances of derivative-free optimization allow efficient approximating the global optimal solutions of sophisticated functions, such as functions with many local optima, non-differentiable and non-continuous functions. This article describes the ZOOpt (https://github.com/eyounx/ZOOpt) toolbox that provides efficient derivative-free solvers and are designed easy to use. ZOOpt provides a Python package for single-thread optimization, and a light-weighted distributed version with the help of the Julia language for Python described functions. ZOOpt toolbox particularly focuses on optimization problems in machine learning, addressing high-dimensional, noisy, and large-scale problems. The toolbox is being maintained toward ready-to-use tool in real-world machine learning tasks.