 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFPC: Towards Efficient and Flexible Prompt Compression
Mar 11, 2025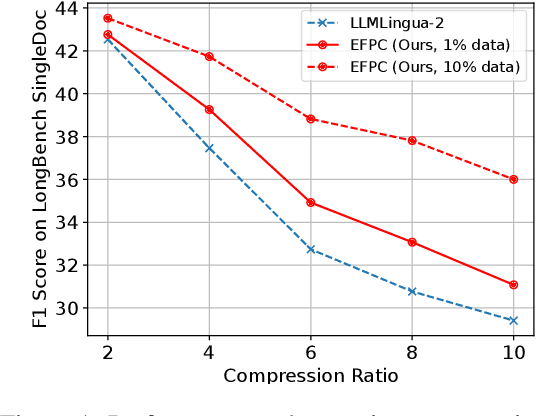
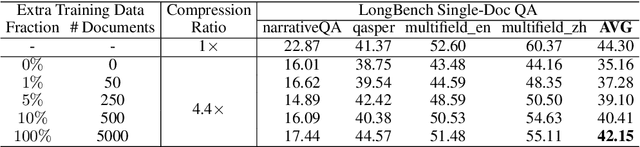

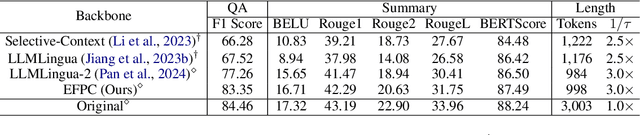
The emergence of large language models (LLMs) like GPT-4 has revolutionized natural language processing (NLP), enabling diverse, complex tasks. However, extensive token counts lead to high computational and financial burdens. To address this, we propose Efficient and Flexible Prompt Compression (EFPC), a novel method unifying task-aware and task-agnostic compression for a favorable accuracy-efficiency trade-off. EFPC uses GPT-4 to generate compressed prompts and integrates them with original prompts for training. During training and inference, we selectively prepend user instructions and compress prompts based on predicted probabilities. EFPC is highly data-efficient, achieving significant performance with minimal data. Compared to the state-of-the-art method LLMLingua-2, EFPC achieves a 4.8% relative improvement in F1-score with 1% additional data at a 4x compression rate, and an 11.4% gain with 10% additional data on the LongBench single-doc QA benchmark. EFPC's unified framework supports broad applicability and enhances performance across various models, tasks, and domains, offering a practical advancement in NLP.
On Improving the Algorithm-, Model-, and Data- Efficiency of Self-Supervised Learning
Apr 30, 2024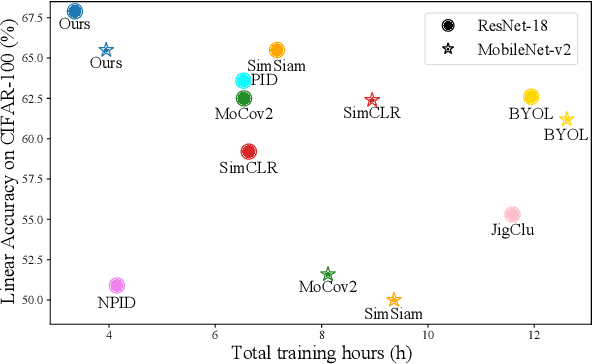
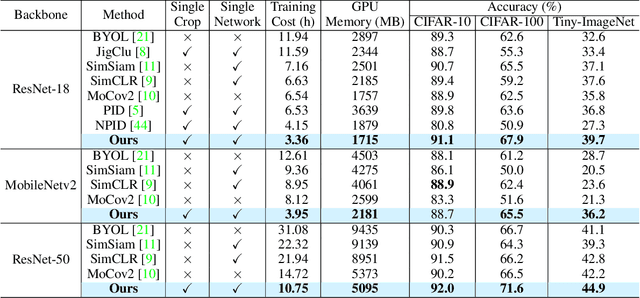
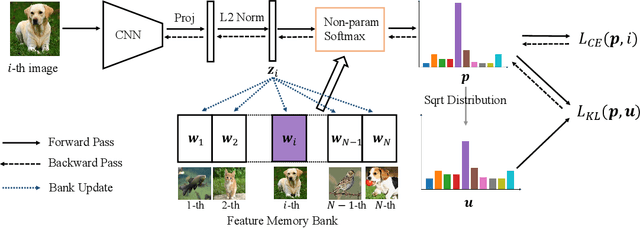
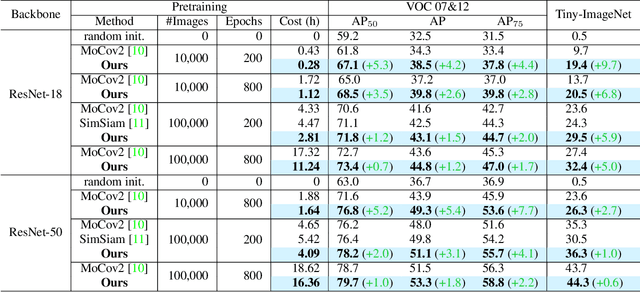
Self-supervised learning (SSL) has developed rapidly in recent years. However, most of the mainstream methods are computationally expensive and rely on two (or more) augmentations for each image to construct positive pairs. Moreover, they mainly focus on large models and large-scale datasets, which lack flexibility and feasibility in many practical applications. In this paper, we propose an efficient single-branch SSL method based on non-parametric instance discrimination, aiming to improve the algorithm, model, and data efficiency of SSL. By analyzing the gradient formula, we correct the update rule of the memory bank with improved performance. We further propose a novel self-distillation loss that minimizes the KL divergence between the probability distribution and its square root version. We show that this alleviates the infrequent updating problem in instance discrimination and greatly accelerates convergence. We systematically compare the training overhead and performance of different methods in different scales of data, and under different backbones. Experimental results show that our method outperforms various baselines with significantly less overhead, and is especially effective for limited amounts of data and small models.
Three Guidelines You Should Know for Universally Slimmable Self-Supervised Learning
Mar 13, 2023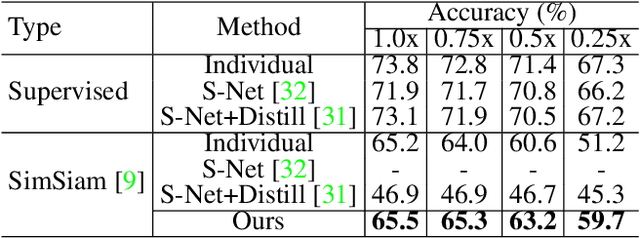
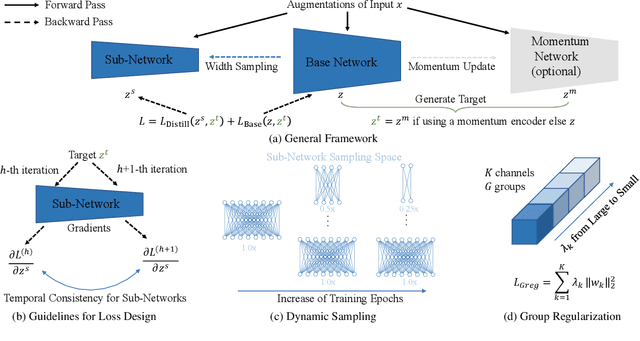
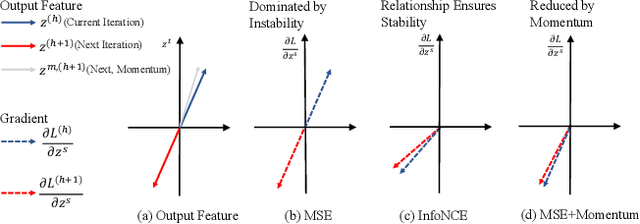
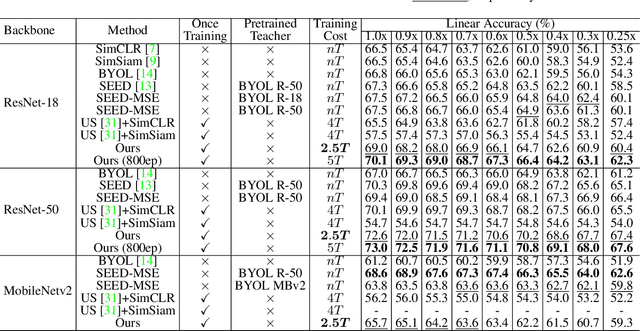
We propose universally slimmable self-supervised learning (dubbed as US3L) to achieve better accuracy-efficiency trade-offs for deploying self-supervised models across different devices. We observe that direct adaptation of self-supervised learning (SSL) to universally slimmable networks misbehaves as the training process frequently collapses. We then discover that temporal consistent guidance is the key to the success of SSL for universally slimmable networks, and we propose three guidelines for the loss design to ensure this temporal consistency from a unified gradient perspective. Moreover, we propose dynamic sampling and group regularization strategies to simultaneously improve training efficiency and accuracy. Our US3L method has been empirically validated on both convolutional neural networks and vision transformers. With only once training and one copy of weights, our method outperforms various state-of-the-art methods (individually trained or not) on benchmarks including recognition, object detection and instance segmentation. Our code is available at https://github.com/megvii-research/US3L-CVPR2023.
Synergistic Self-supervised and Quantization Learning
Jul 12, 2022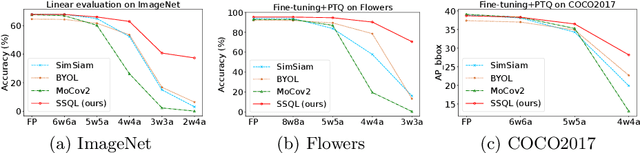
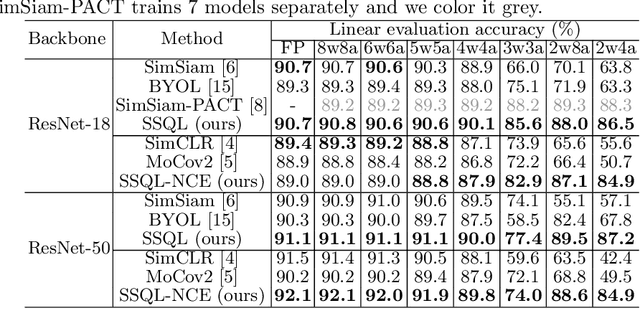
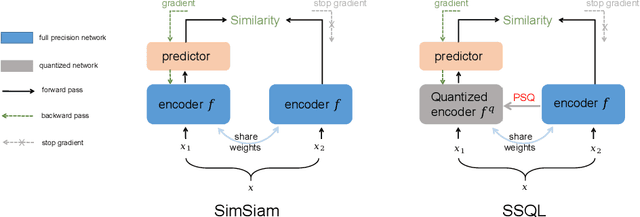
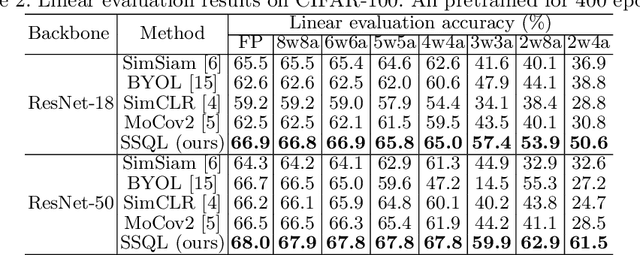
With the success of self-supervised learning (SSL), it has become a mainstream paradigm to fine-tune from self-supervised pretrained models to boost the performance on downstream tasks. However, we find that current SSL models suffer severe accuracy drops when performing low-bit quantization, prohibiting their deployment in resource-constrained applications. In this paper, we propose a method called synergistic self-supervised and quantization learning (SSQL) to pretrain quantization-friendly self-supervised models facilitating downstream deployment. SSQL contrasts the features of the quantized and full precision models in a self-supervised fashion, where the bit-width for the quantized model is randomly selected in each step. SSQL not only significantly improves the accuracy when quantized to lower bit-widths, but also boosts the accuracy of full precision models in most cases. By only training once, SSQL can then benefit various downstream tasks at different bit-widths simultaneously. Moreover, the bit-width flexibility is achieved without additional storage overhead, requiring only one copy of weights during training and inference. We theoretically analyze the optimization process of SSQL, and conduct exhaustive experiments on various benchmarks to further demonstrate the effectiveness of our method. Our code is available at https://github.com/megvii-research/SSQL-ECCV2022.
Worst Case Matters for Few-Shot Recognition
Mar 13, 2022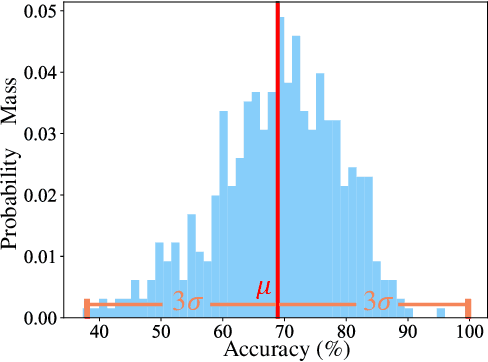
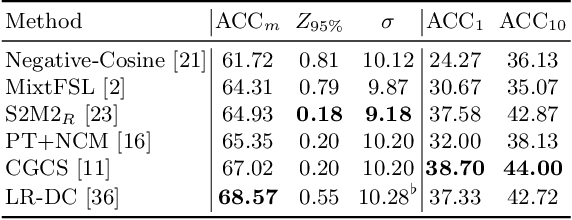
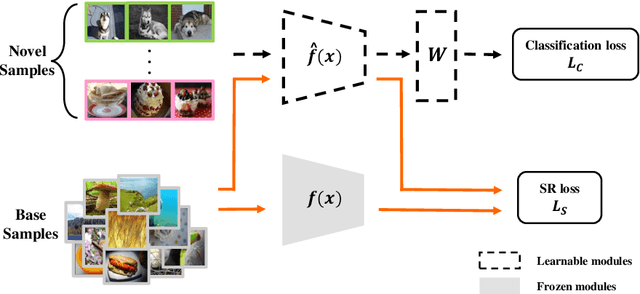
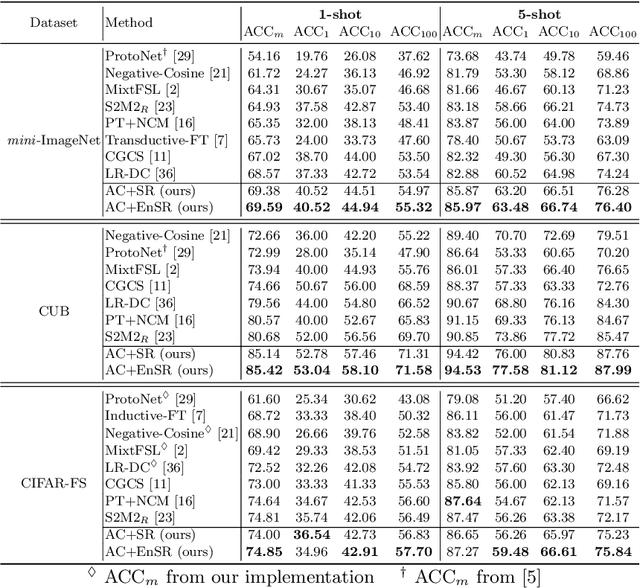
Few-shot recognition learns a recognition model with very few (e.g., 1 or 5) images per category, and current few-shot learning methods focus on improving the average accuracy over many episodes. We argue that in real-world applications we may often only try one episode instead of many, and hence maximizing the worst-case accuracy is more important than maximizing the average accuracy. We empirically show that a high average accuracy not necessarily means a high worst-case accuracy. Since this objective is not accessible, we propose to reduce the standard deviation and increase the average accuracy simultaneously. In turn, we devise two strategies from the bias-variance tradeoff perspective to implicitly reach this goal: a simple yet effective stability regularization (SR) loss together with model ensemble to reduce variance during fine-tuning, and an adaptability calibration mechanism to reduce the bias. Extensive experiments on benchmark datasets demonstrate the effectiveness of the proposed strategies, which outperforms current state-of-the-art methods with a significant margin in terms of not only average, but also worst-case accuracy.
Training Vision Transformers with Only 2040 Images
Jan 26, 2022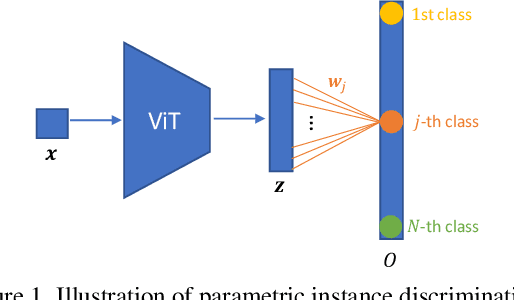
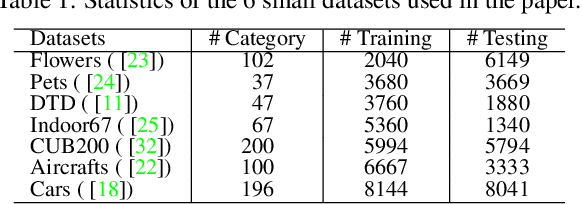
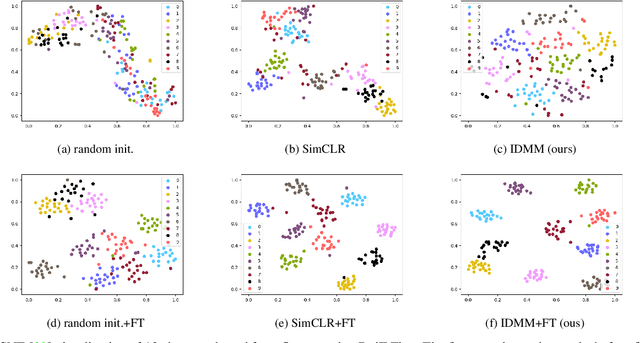
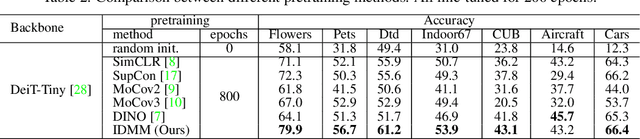
Vision Transformers (ViTs) is emerging as an alternative to convolutional neural networks (CNNs) for visual recognition. They achieve competitive results with CNNs but the lack of the typical convolutional inductive bias makes them more data-hungry than common CNNs. They are often pretrained on JFT-300M or at least ImageNet and few works study training ViTs with limited data. In this paper, we investigate how to train ViTs with limited data (e.g., 2040 images). We give theoretical analyses that our method (based on parametric instance discrimination) is superior to other methods in that it can capture both feature alignment and instance similarities. We achieve state-of-the-art results when training from scratch on 7 small datasets under various ViT backbones. We also investigate the transferring ability of small datasets and find that representations learned from small datasets can even improve large-scale ImageNet training.
A Random CNN Sees Objects: One Inductive Bias of CNN and Its Applications
Jun 17, 2021
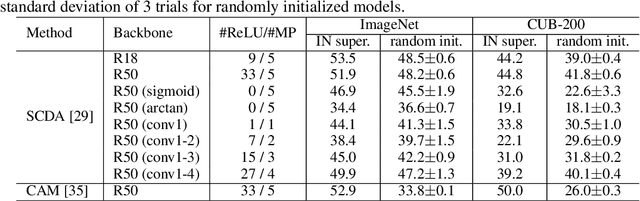
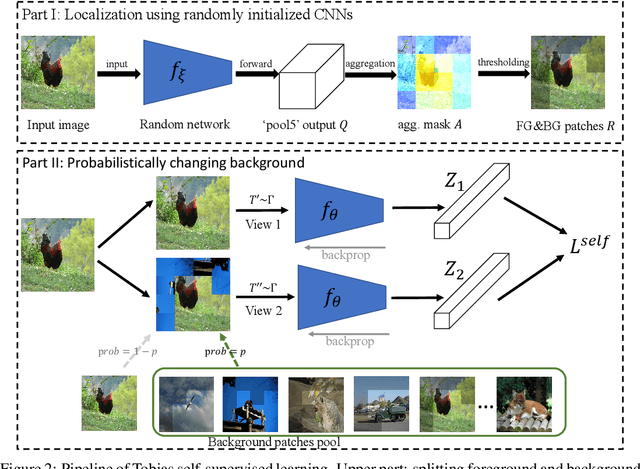
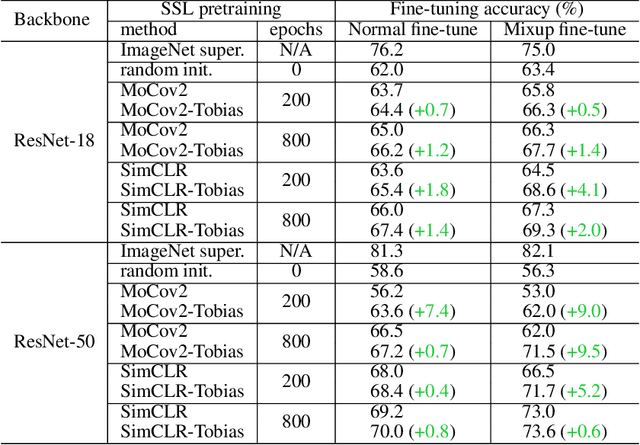
This paper starts by revealing a surprising finding: without any learning, a randomly initialized CNN can localize objects surprisingly well. That is, a CNN has an inductive bias to naturally focus on objects, named as Tobias (``The object is at sight'') in this paper. This empirical inductive bias is further analyzed and successfully applied to self-supervised learning. A CNN is encouraged to learn representations that focus on the foreground object, by transforming every image into various versions with different backgrounds, where the foreground and background separation is guided by Tobias. Experimental results show that the proposed Tobias significantly improves downstream tasks, especially for object detection. This paper also shows that Tobias has consistent improvements on training sets of different sizes, and is more resilient to changes in image augmentations. Our codes will be available at https://github.com/CupidJay/Tobias.
Rethinking Self-Supervised Learning: Small is Beautiful
Mar 25, 2021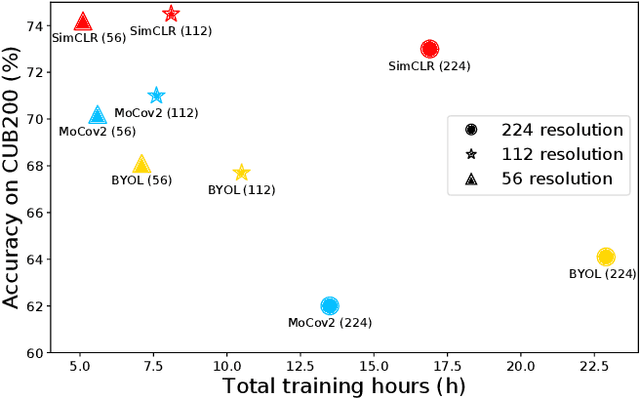
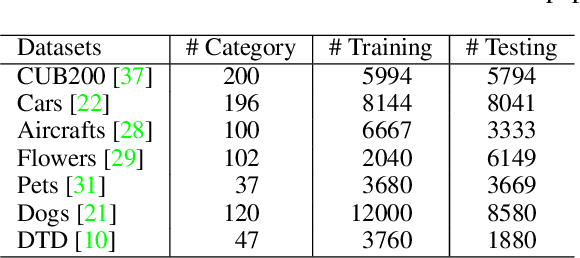
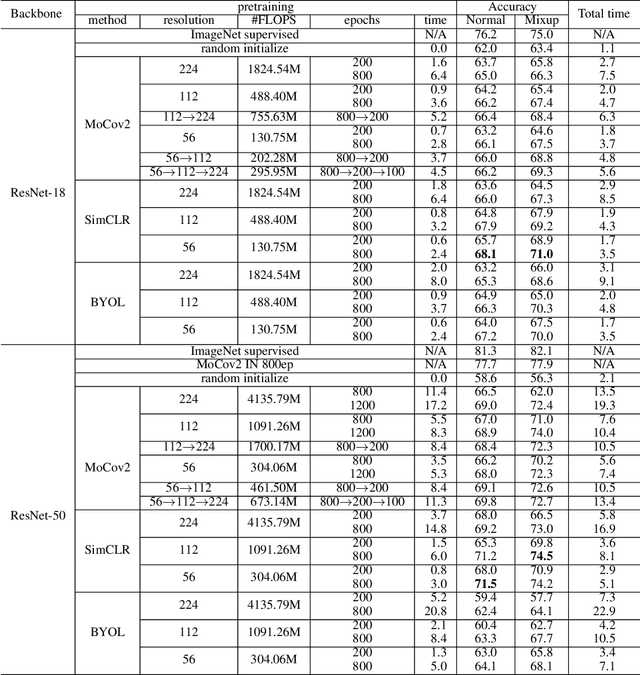
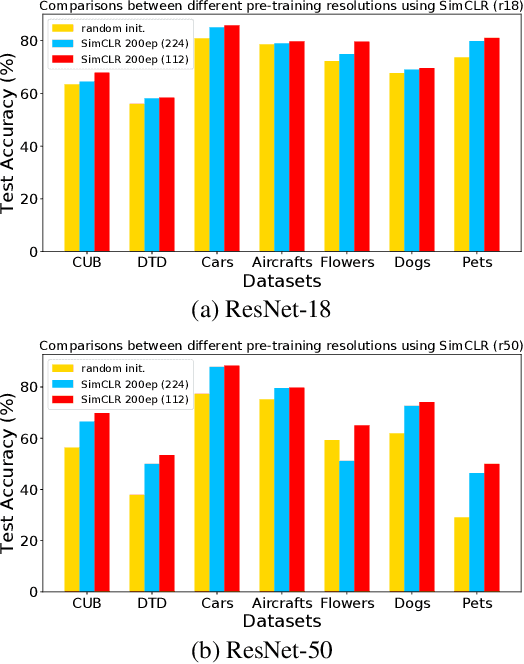
Self-supervised learning (SSL), in particular contrastive learning, has made great progress in recent years. However, a common theme in these methods is that they inherit the learning paradigm from the supervised deep learning scenario. Current SSL methods are often pretrained for many epochs on large-scale datasets using high resolution images, which brings heavy computational cost and lacks flexibility. In this paper, we demonstrate that the learning paradigm for SSL should be different from supervised learning and the information encoded by the contrastive loss is expected to be much less than that encoded in the labels in supervised learning via the cross entropy loss. Hence, we propose scaled-down self-supervised learning (S3L), which include 3 parts: small resolution, small architecture and small data. On a diverse set of datasets, SSL methods and backbone architectures, S3L achieves higher accuracy consistently with much less training cost when compared to previous SSL learning paradigm. Furthermore, we show that even without a large pretraining dataset, S3L can achieve impressive results on small data alone. Our code has been made publically available at https://github.com/CupidJay/Scaled-down-self-supervised-learning.
Rethinking the Route Towards Weakly Supervised Object Localization
Mar 03, 2020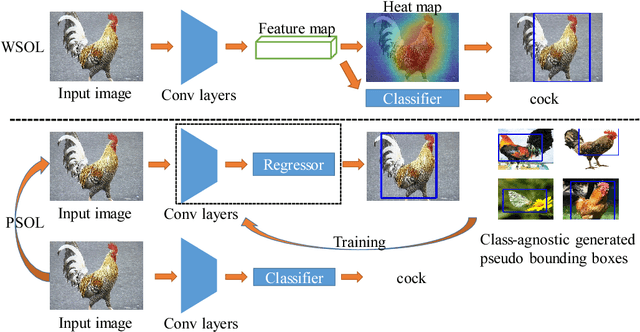
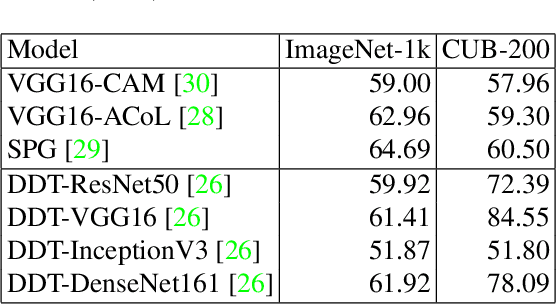
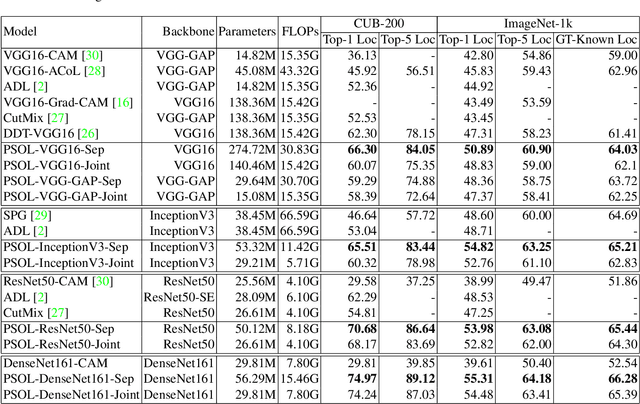

Weakly supervised object localization (WSOL) aims to localize objects with only image-level labels. Previous methods often try to utilize feature maps and classification weights to localize objects using image level annotations indirectly. In this paper, we demonstrate that weakly supervised object localization should be divided into two parts: class-agnostic object localization and object classification. For class-agnostic object localization, we should use class-agnostic methods to generate noisy pseudo annotations and then perform bounding box regression on them without class labels. We propose the pseudo supervised object localization (PSOL) method as a new way to solve WSOL. Our PSOL models have good transferability across different datasets without fine-tuning. With generated pseudo bounding boxes, we achieve 58.00% localization accuracy on ImageNet and 74.97% localization accuracy on CUB-200, which have a large edge over previous models.
Neural Forest Learning
Nov 18, 2019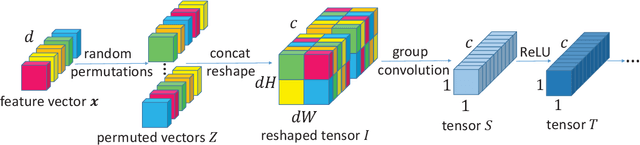
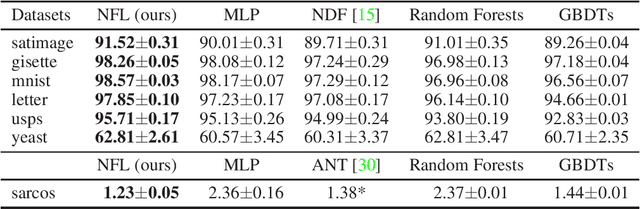
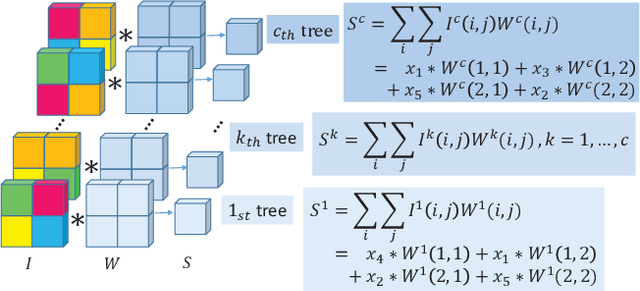
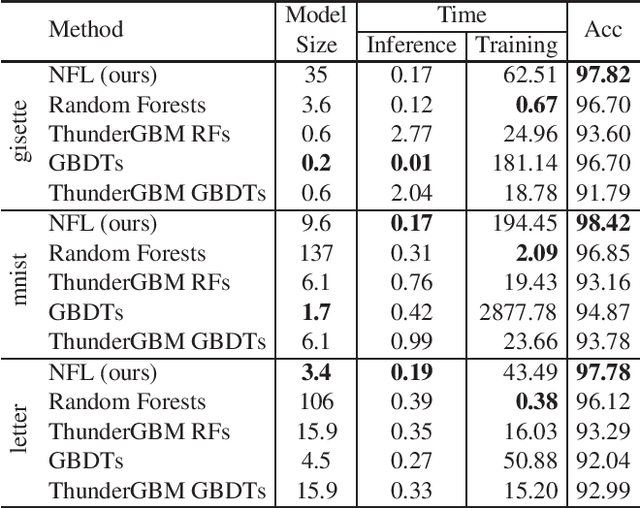
We propose Neural Forest Learning (NFL), a novel deep learning based random-forest-like method. In contrast to previous forest methods, NFL enjoys the benefits of end-to-end, data-driven representation learning, as well as pervasive support from deep learning software and hardware platforms, hence achieving faster inference speed and higher accuracy than previous forest methods. Furthermore, NFL learns non-linear feature representations in CNNs more efficiently than previous higher-order pooling methods, producing good results with negligible increase in parameters, floating point operations (FLOPs) and real running time. We achieve superior performance on 7 machine learning datasets when compared to random forests and GBDTs. On the fine-grained benchmarks CUB-200-2011, FGVC-aircraft and Stanford Cars, we achieve over 5.7%, 6.9% and 7.8% gains for VGG-16, respectively. Moreover, NFL can converge in much fewer epochs, further accelerating network training. On the large-scale ImageNet ILSVRC-12 validation set, integration of NFL into ResNet-18 achieves top-1/top-5 errors of 28.32%/9.77%, which outperforms ResNet-18 by 1.92%/1.15% with negligible extra cost and the improvement is consistent under various architectures.