 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPLQ: A General, Practical, and Lightning QAT Method for Vision Transformers
Jun 13, 2025Vision Transformers (ViTs) are essential in computer vision but are computationally intensive, too. Model quantization, particularly to low bit-widths like 4-bit, aims to alleviate this difficulty, yet existing Post-Training Quantization (PTQ) and Quantization-Aware Training (QAT) methods exhibit significant limitations. PTQ often incurs substantial accuracy drop, while QAT achieves high accuracy but suffers from prohibitive computational costs, limited generalization to downstream tasks, training instability, and lacking of open-source codebase. To address these challenges, this paper introduces General, Practical, and Lightning Quantization (GPLQ), a novel framework designed for efficient and effective ViT quantization. GPLQ is founded on two key empirical insights: the paramount importance of activation quantization and the necessity of preserving the model's original optimization ``basin'' to maintain generalization. Consequently, GPLQ employs a sequential ``activation-first, weights-later'' strategy. Stage 1 keeps weights in FP32 while quantizing activations with a feature mimicking loss in only 1 epoch to keep it stay in the same ``basin'', thereby preserving generalization. Stage 2 quantizes weights using a PTQ method. As a result, GPLQ is 100x faster than existing QAT methods, lowers memory footprint to levels even below FP32 training, and achieves 4-bit model performance that is highly competitive with FP32 models in terms of both accuracy on ImageNet and generalization to diverse downstream tasks, including fine-grained visual classification and object detection. We will release an easy-to-use open-source toolkit supporting multiple vision tasks.
QwT-v2: Practical, Effective and Efficient Post-Training Quantization
May 27, 2025Network quantization is arguably one of the most practical network compression approaches for reducing the enormous resource consumption of modern deep neural networks. They usually require diverse and subtle design choices for specific architecture and tasks. Instead, the QwT method is a simple and general approach which introduces lightweight additional structures to improve quantization. But QwT incurs extra parameters and latency. More importantly, QwT is not compatible with many hardware platforms. In this paper, we propose QwT-v2, which not only enjoys all advantages of but also resolves major defects of QwT. By adopting a very lightweight channel-wise affine compensation (CWAC) module, QwT-v2 introduces significantly less extra parameters and computations compared to QwT, and at the same time matches or even outperforms QwT in accuracy. The compensation module of QwT-v2 can be integrated into quantization inference engines with little effort, which not only effectively removes the extra costs but also makes it compatible with most existing hardware platforms.
Who Reasons in the Large Language Models?
May 27, 2025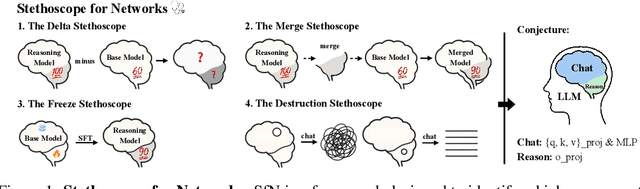

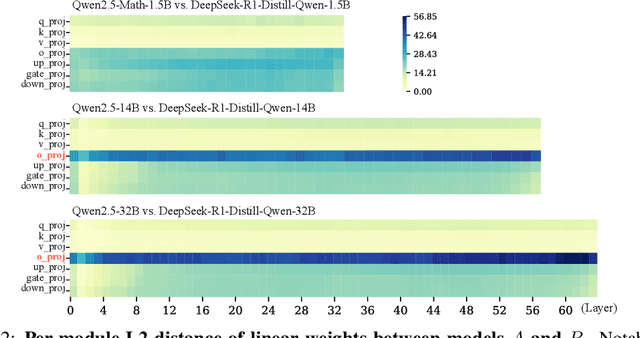

Despite the impressive performance of large language models (LLMs), the process of endowing them with new capabilities--such as mathematical reasoning--remains largely empirical and opaque. A critical open question is whether reasoning abilities stem from the entire model, specific modules, or are merely artifacts of overfitting. In this work, we hypothesize that the reasoning capabilities in well-trained LLMs are primarily attributed to the output projection module (oproj) in the Transformer's multi-head self-attention (MHSA) mechanism. To support this hypothesis, we introduce Stethoscope for Networks (SfN), a suite of diagnostic tools designed to probe and analyze the internal behaviors of LLMs. Using SfN, we provide both circumstantial and empirical evidence suggesting that oproj plays a central role in enabling reasoning, whereas other modules contribute more to fluent dialogue. These findings offer a new perspective on LLM interpretability and open avenues for more targeted training strategies, potentially enabling more efficient and specialized LLMs.
All You Need in Knowledge Distillation Is a Tailored Coordinate System
Dec 12, 2024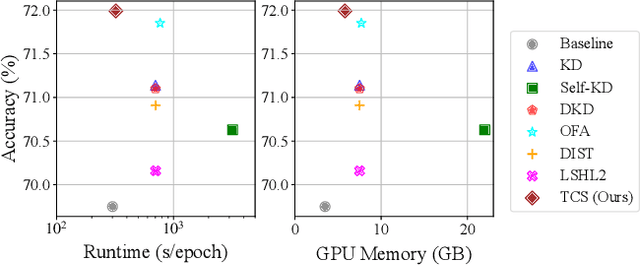
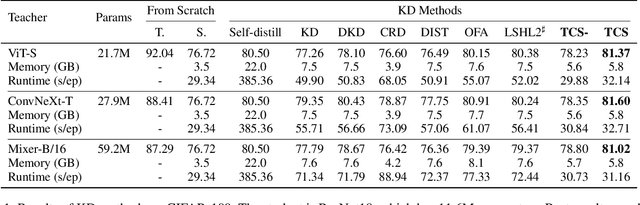
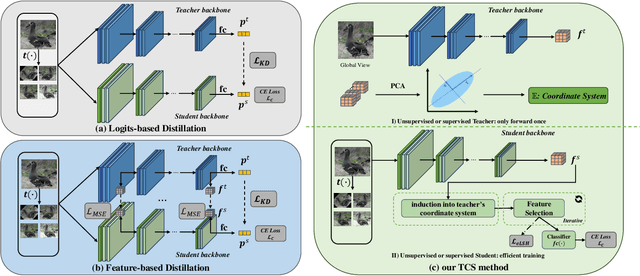
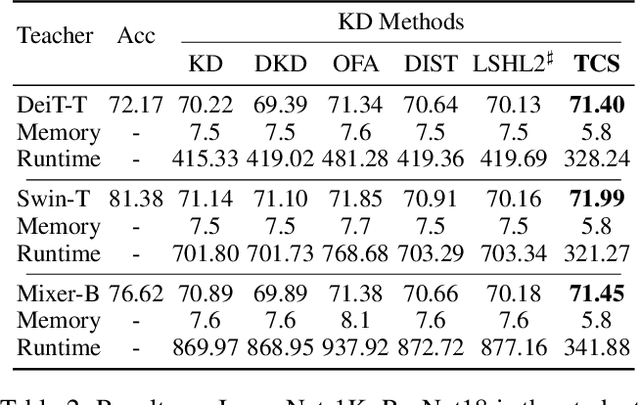
Knowledge Distillation (KD) is essential in transferring dark knowledge from a large teacher to a small student network, such that the student can be much more efficient than the teacher but with comparable accuracy. Existing KD methods, however, rely on a large teacher trained specifically for the target task, which is both very inflexible and inefficient. In this paper, we argue that a SSL-pretrained model can effectively act as the teacher and its dark knowledge can be captured by the coordinate system or linear subspace where the features lie in. We then need only one forward pass of the teacher, and then tailor the coordinate system (TCS) for the student network. Our TCS method is teacher-free and applies to diverse architectures, works well for KD and practical few-shot learning, and allows cross-architecture distillation with large capacity gap. Experiments show that TCS achieves significantly higher accuracy than state-of-the-art KD methods, while only requiring roughly half of their training time and GPU memory costs.
Quantization without Tears
Nov 22, 2024



Deep neural networks, while achieving remarkable success across diverse tasks, demand significant resources, including computation, GPU memory, bandwidth, storage, and energy. Network quantization, as a standard compression and acceleration technique, reduces storage costs and enables potential inference acceleration by discretizing network weights and activations into a finite set of integer values. However, current quantization methods are often complex and sensitive, requiring extensive task-specific hyperparameters, where even a single misconfiguration can impair model performance, limiting generality across different models and tasks. In this paper, we propose Quantization without Tears (QwT), a method that simultaneously achieves quantization speed, accuracy, simplicity, and generality. The key insight of QwT is to incorporate a lightweight additional structure into the quantized network to mitigate information loss during quantization. This structure consists solely of a small set of linear layers, keeping the method simple and efficient. More importantly, it provides a closed-form solution, allowing us to improve accuracy effortlessly under 2 minutes. Extensive experiments across various vision, language, and multimodal tasks demonstrate that QwT is both highly effective and versatile. In fact, our approach offers a robust solution for network quantization that combines simplicity, accuracy, and adaptability, which provides new insights for the design of novel quantization paradigms.
Diffusion Product Quantization
Nov 19, 2024In this work, we explore the quantization of diffusion models in extreme compression regimes to reduce model size while maintaining performance. We begin by investigating classical vector quantization but find that diffusion models are particularly susceptible to quantization error, with the codebook size limiting generation quality. To address this, we introduce product quantization, which offers improved reconstruction precision and larger capacity -- crucial for preserving the generative capabilities of diffusion models. Furthermore, we propose a method to compress the codebook by evaluating the importance of each vector and removing redundancy, ensuring the model size remaining within the desired range. We also introduce an end-to-end calibration approach that adjusts assignments during the forward pass and optimizes the codebook using the DDPM loss. By compressing the model to as low as 1 bit (resulting in over 24 times reduction in model size), we achieve a balance between compression and quality. We apply our compression method to the DiT model on ImageNet and consistently outperform other quantization approaches, demonstrating competitive generative performance.
Minimal Interaction Edge Tuning: A New Paradigm for Visual Adaptation
Jun 26, 2024The rapid scaling of large vision pretrained models makes fine-tuning tasks more and more difficult on edge devices with low computational resources. We explore a new visual adaptation paradigm called edge tuning, which treats large pretrained models as standalone feature extractors that run on powerful cloud servers. The fine-tuning carries out on edge devices with small networks which require low computational resources. Existing methods that are potentially suitable for our edge tuning paradigm are discussed. But, three major drawbacks hinder their application in edge tuning: low adaptation capability, large adapter network, and high information transfer overhead. To address these issues, we propose Minimal Interaction Edge Tuning, or MIET, which reveals that the sum of intermediate features from pretrained models not only has minimal information transfer but also has high adaptation capability. With a lightweight attention-based adaptor network, MIET achieves information transfer efficiency, parameter efficiency, computational and memory efficiency, and at the same time demonstrates competitive results on various visual adaptation benchmarks.
Effectively Compress KV Heads for LLM
Jun 11, 2024The advent of pre-trained large language models (LLMs) has revolutionized various natural language processing tasks. These models predominantly employ an auto-regressive decoding mechanism that utilizes Key-Value (KV) caches to eliminate redundant calculations for previous tokens. Nevertheless, as context lengths and batch sizes increase, the linear expansion in memory footprint of KV caches becomes a key bottleneck of LLM deployment, which decreases generation speeds significantly. To mitigate this issue, previous techniques like multi-query attention (MQA) and grouped-query attention (GQA) have been developed, in order to reduce KV heads to accelerate inference with comparable accuracy to multi-head attention (MHA). Despite their effectiveness, existing strategies for compressing MHA often overlook the intrinsic properties of the KV caches. In this work, we explore the low-rank characteristics of the KV caches and propose a novel approach for compressing KV heads. In particular, we carefully optimize the MHA-to-GQA transformation to minimize compression error, and to remain compatible with rotary position embeddings (RoPE), we also introduce specialized strategies for key caches with RoPE. We demonstrate that our method can compress half or even three-quarters of KV heads while maintaining performance comparable to the original LLMs, which presents a promising direction for more efficient LLM deployment in resource-constrained environments.
Unified Low-rank Compression Framework for Click-through Rate Prediction
May 28, 2024



Deep Click-Through Rate (CTR) prediction models play an important role in modern industrial recommendation scenarios. However, high memory overhead and computational costs limit their deployment in resource-constrained environments. Low-rank approximation is an effective method for computer vision and natural language processing models, but its application in compressing CTR prediction models has been less explored. Due to the limited memory and computing resources, compression of CTR prediction models often confronts three fundamental challenges, i.e., (1). How to reduce the model sizes to adapt to edge devices? (2). How to speed up CTR prediction model inference? (3). How to retain the capabilities of original models after compression? Previous low-rank compression research mostly uses tensor decomposition, which can achieve a high parameter compression ratio, but brings in AUC degradation and additional computing overhead. To address these challenges, we propose a unified low-rank decomposition framework for compressing CTR prediction models. We find that even with the most classic matrix decomposition SVD method, our framework can achieve better performance than the original model. To further improve the effectiveness of our framework, we locally compress the output features instead of compressing the model weights. Our unified low-rank compression framework can be applied to embedding tables and MLP layers in various CTR prediction models. Extensive experiments on two academic datasets and one real industrial benchmark demonstrate that, with 3-5x model size reduction, our compressed models can achieve both faster inference and higher AUC than the uncompressed original models. Our code is at https://github.com/yuhao318/Atomic_Feature_Mimicking.
On Improving the Algorithm-, Model-, and Data- Efficiency of Self-Supervised Learning
Apr 30, 2024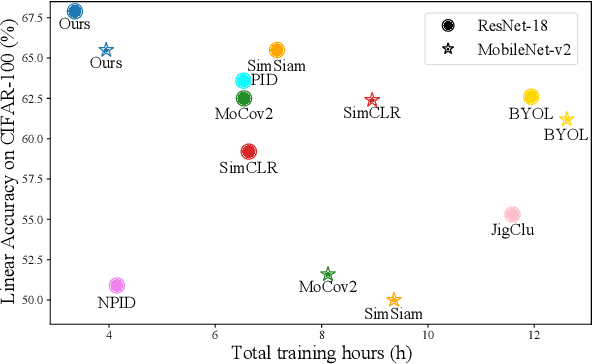
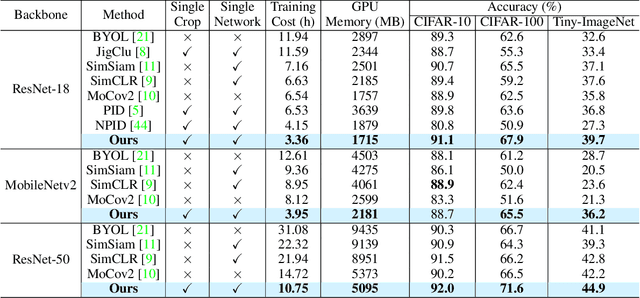
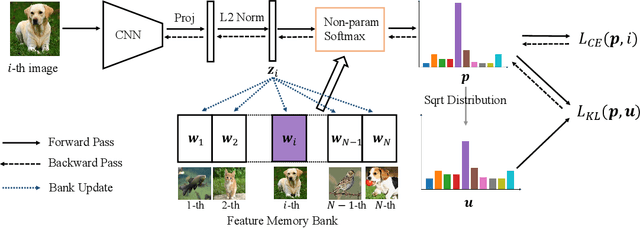
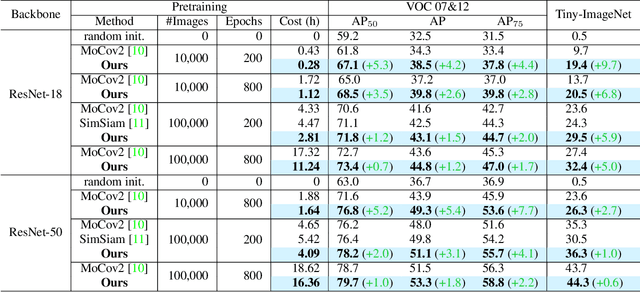
Self-supervised learning (SSL) has developed rapidly in recent years. However, most of the mainstream methods are computationally expensive and rely on two (or more) augmentations for each image to construct positive pairs. Moreover, they mainly focus on large models and large-scale datasets, which lack flexibility and feasibility in many practical applications. In this paper, we propose an efficient single-branch SSL method based on non-parametric instance discrimination, aiming to improve the algorithm, model, and data efficiency of SSL. By analyzing the gradient formula, we correct the update rule of the memory bank with improved performance. We further propose a novel self-distillation loss that minimizes the KL divergence between the probability distribution and its square root version. We show that this alleviates the infrequent updating problem in instance discrimination and greatly accelerates convergence. We systematically compare the training overhead and performance of different methods in different scales of data, and under different backbones. Experimental results show that our method outperforms various baselines with significantly less overhead, and is especially effective for limited amounts of data and small models.