 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
YOLOv8-SMOT: An Efficient and Robust Framework for Real-Time Small Object Tracking via Slice-Assisted Training and Adaptive Association
Jul 16, 2025



Tracking small, agile multi-objects (SMOT), such as birds, from an Unmanned Aerial Vehicle (UAV) perspective is a highly challenging computer vision task. The difficulty stems from three main sources: the extreme scarcity of target appearance features, the complex motion entanglement caused by the combined dynamics of the camera and the targets themselves, and the frequent occlusions and identity ambiguity arising from dense flocking behavior. This paper details our championship-winning solution in the MVA 2025 "Finding Birds" Small Multi-Object Tracking Challenge (SMOT4SB), which adopts the tracking-by-detection paradigm with targeted innovations at both the detection and association levels. On the detection side, we propose a systematic training enhancement framework named \textbf{SliceTrain}. This framework, through the synergy of 'deterministic full-coverage slicing' and 'slice-level stochastic augmentation, effectively addresses the problem of insufficient learning for small objects in high-resolution image training. On the tracking side, we designed a robust tracker that is completely independent of appearance information. By integrating a \textbf{motion direction maintenance (EMA)} mechanism and an \textbf{adaptive similarity metric} combining \textbf{bounding box expansion and distance penalty} into the OC-SORT framework, our tracker can stably handle irregular motion and maintain target identities. Our method achieves state-of-the-art performance on the SMOT4SB public test set, reaching an SO-HOTA score of \textbf{55.205}, which fully validates the effectiveness and advancement of our framework in solving complex real-world SMOT problems. The source code will be made available at https://github.com/Salvatore-Love/YOLOv8-SMOT.
GPLQ: A General, Practical, and Lightning QAT Method for Vision Transformers
Jun 13, 2025Vision Transformers (ViTs) are essential in computer vision but are computationally intensive, too. Model quantization, particularly to low bit-widths like 4-bit, aims to alleviate this difficulty, yet existing Post-Training Quantization (PTQ) and Quantization-Aware Training (QAT) methods exhibit significant limitations. PTQ often incurs substantial accuracy drop, while QAT achieves high accuracy but suffers from prohibitive computational costs, limited generalization to downstream tasks, training instability, and lacking of open-source codebase. To address these challenges, this paper introduces General, Practical, and Lightning Quantization (GPLQ), a novel framework designed for efficient and effective ViT quantization. GPLQ is founded on two key empirical insights: the paramount importance of activation quantization and the necessity of preserving the model's original optimization ``basin'' to maintain generalization. Consequently, GPLQ employs a sequential ``activation-first, weights-later'' strategy. Stage 1 keeps weights in FP32 while quantizing activations with a feature mimicking loss in only 1 epoch to keep it stay in the same ``basin'', thereby preserving generalization. Stage 2 quantizes weights using a PTQ method. As a result, GPLQ is 100x faster than existing QAT methods, lowers memory footprint to levels even below FP32 training, and achieves 4-bit model performance that is highly competitive with FP32 models in terms of both accuracy on ImageNet and generalization to diverse downstream tasks, including fine-grained visual classification and object detection. We will release an easy-to-use open-source toolkit supporting multiple vision tasks.
MVA2023 Small Object Detection Challenge for Spotting Birds: Dataset, Methods, and Results
Jul 18, 2023

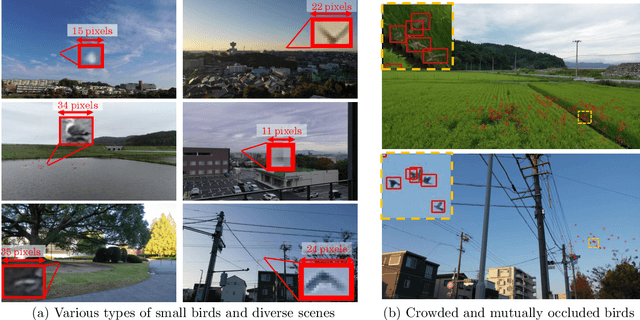
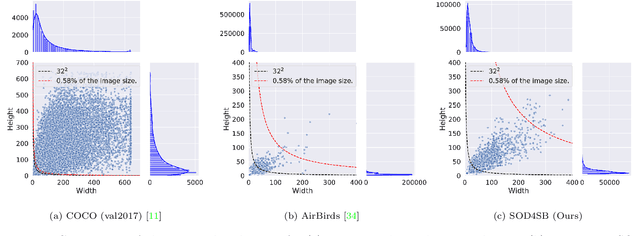
Small Object Detection (SOD) is an important machine vision topic because (i) a variety of real-world applications require object detection for distant objects and (ii) SOD is a challenging task due to the noisy, blurred, and less-informative image appearances of small objects. This paper proposes a new SOD dataset consisting of 39,070 images including 137,121 bird instances, which is called the Small Object Detection for Spotting Birds (SOD4SB) dataset. The detail of the challenge with the SOD4SB dataset is introduced in this paper. In total, 223 participants joined this challenge. This paper briefly introduces the award-winning methods. The dataset, the baseline code, and the website for evaluation on the public testset are publicly available.
Pose-aware Adversarial Domain Adaptation for Personalized Facial Expression Recognition
Jul 12, 2020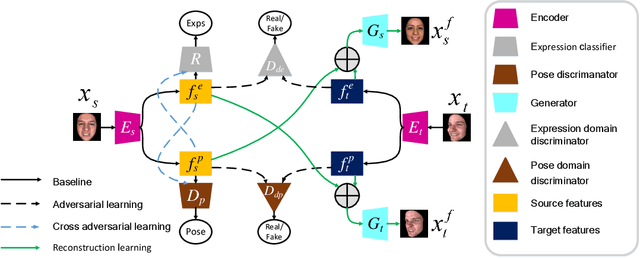
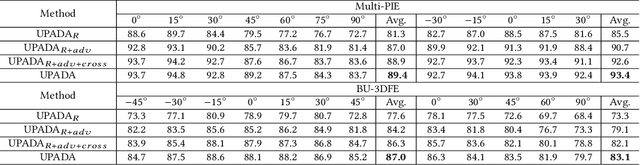
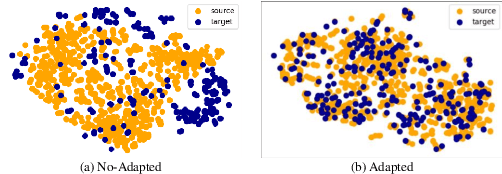
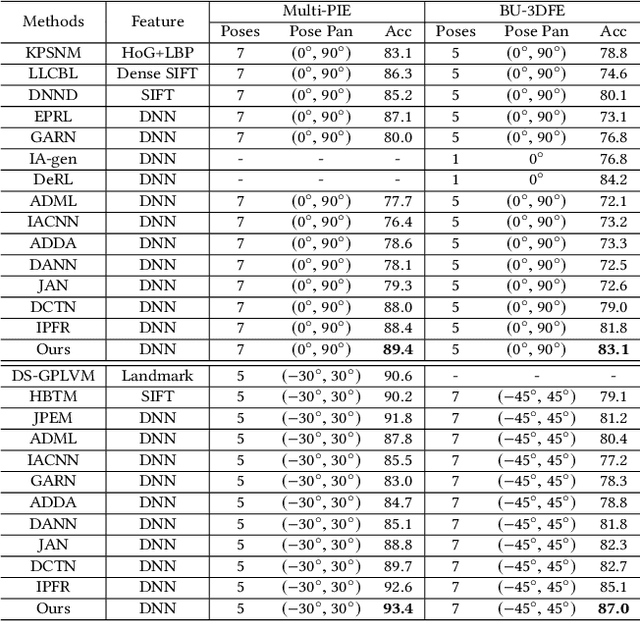
Current facial expression recognition methods fail to simultaneously cope with pose and subject variations. In this paper, we propose a novel unsupervised adversarial domain adaptation method which can alleviate both variations at the same time. Specially, our method consists of three learning strategies: adversarial domain adaptation learning, cross adversarial feature learning, and reconstruction learning. The first aims to learn pose- and expression-related feature representations in the source domain and adapt both feature distributions to that of the target domain by imposing adversarial learning. By using personalized adversarial domain adaptation, this learning strategy can alleviate subject variations and exploit information from the source domain to help learning in the target domain. The second serves to perform feature disentanglement between pose- and expression-related feature representations by impulsing pose-related feature representations expression-undistinguished and the expression-related feature representations pose-undistinguished. The last can further boost feature learning by applying face image reconstructions so that the learned expression-related feature representations are more pose- and identity-robust. Experimental results on four benchmark datasets demonstrate the effectiveness of the proposed method.
Multiple Face Analyses through Adversarial Learning
Nov 18, 2019
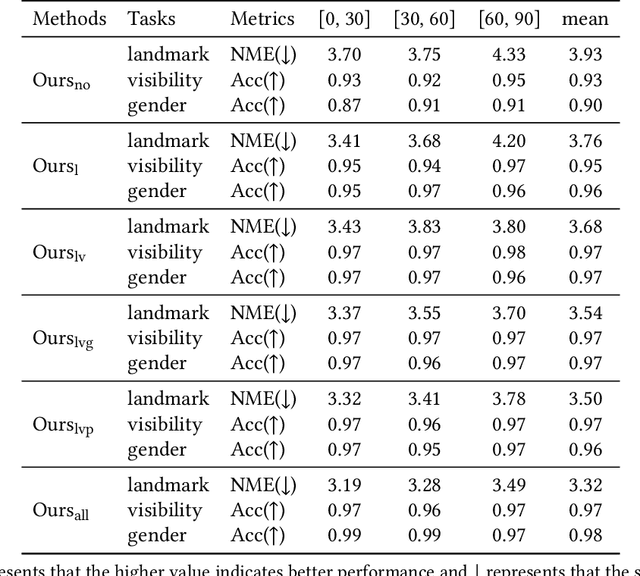
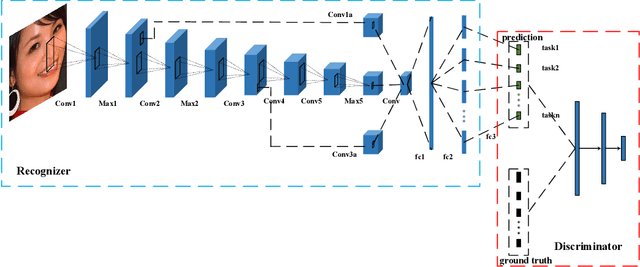
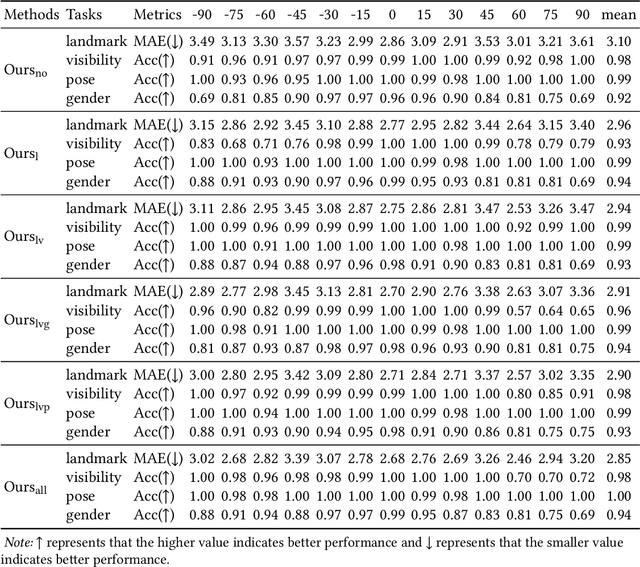
This inherent relations among multiple face analysis tasks, such as landmark detection, head pose estimation, gender recognition and face attribute estimation are crucial to boost the performance of each task, but have not been thoroughly explored since typically these multiple face analysis tasks are handled as separate tasks. In this paper, we propose a novel deep multi-task adversarial learning method to localize facial landmark, estimate head pose and recognize gender jointly or estimate multiple face attributes simultaneously through exploring their dependencies from both image representation-level and label-level. Specifically, the proposed method consists of a deep recognition network R and a discriminator D. The deep recognition network is used to learn the shared middle-level image representation and conducts multiple face analysis tasks simultaneously. Through multi-task learning mechanism, the recognition network explores the dependencies among multiple face analysis tasks, such as facial landmark localization, head pose estimation, gender recognition and face attribute estimation from image representation-level. The discriminator is introduced to enforce the distribution of the multiple face analysis tasks to converge to that inherent in the ground-truth labels. During training, the recognizer tries to confuse the discriminator, while the discriminator competes with the recognizer through distinguishing the predicted label combination from the ground-truth one. Though adversarial learning, we explore the dependencies among multiple face analysis tasks from label-level. Experimental results on four benchmark databases, i.e., the AFLW database, the Multi-PIE database, the CelebA database and the LFWA database, demonstrate the effectiveness of the proposed method for multiple face analyses.