 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEAR: Towards Beam-Search-Aware Optimization for Recommendation with Large Language Models
Jan 30, 2026Recent years have witnessed a rapid surge in research leveraging Large Language Models (LLMs) for recommendation. These methods typically employ supervised fine-tuning (SFT) to adapt LLMs to recommendation scenarios, and utilize beam search during inference to efficiently retrieve $B$ top-ranked recommended items. However, we identify a critical training-inference inconsistency: while SFT optimizes the overall probability of positive items, it does not guarantee that such items will be retrieved by beam search even if they possess high overall probabilities. Due to the greedy pruning mechanism, beam search can prematurely discard a positive item once its prefix probability is insufficient. To address this inconsistency, we propose BEAR (Beam-SEarch-Aware Regularization), a novel fine-tuning objective that explicitly accounts for beam search behavior during training. Rather than directly simulating beam search for each instance during training, which is computationally prohibitive, BEAR enforces a relaxed necessary condition: each token in a positive item must rank within the top-$B$ candidate tokens at each decoding step. This objective effectively mitigates the risk of incorrect pruning while incurring negligible computational overhead compared to standard SFT. Extensive experiments across four real-world datasets demonstrate that BEAR significantly outperforms strong baselines. Code will be released upon acceptance.
SpecTran: Spectral-Aware Transformer-based Adapter for LLM-Enhanced Sequential Recommendation
Jan 29, 2026Traditional sequential recommendation (SR) models learn low-dimensional item ID embeddings from user-item interactions, often overlooking textual information such as item titles or descriptions. Recent advances in Large Language Models (LLMs) have inspired a surge of research that encodes item textual information with high-dimensional semantic embeddings, and designs transformation methods to inject such embeddings into SR models. These embedding transformation strategies can be categorized into two types, both of which exhibits notable drawbacks: 1) adapter-based methods suffer from pronounced dimension collapse, concentrating information into a few dominant dimensions; 2) SVD-based methods are rigid and manual, considering only a few principal spectral components while discarding rich information in the remaining spectrum. To address these limitations, we propose SpecTran, a spectral-aware transformer-based adapter that operates in the spectral domain, attending to the full spectrum to select and aggregates informative components. A learnable spectral-position encoding injects singular-value cues as an inductive bias, guiding attention toward salient spectral components and promoting diversity across embedding dimensions. Across four real-world datasets and three SR backbones, it consistently outperforms strong baselines, achieving an average improvement of 9.17%.
Talos: Optimizing Top-$K$ Accuracy in Recommender Systems
Jan 27, 2026Recommender systems (RS) aim to retrieve a small set of items that best match individual user preferences. Naturally, RS place primary emphasis on the quality of the Top-$K$ results rather than performance across the entire item set. However, estimating Top-$K$ accuracy (e.g., Precision@$K$, Recall@$K$) requires determining the ranking positions of items, which imposes substantial computational overhead and poses significant challenges for optimization. In addition, RS often suffer from distribution shifts due to evolving user preferences or data biases, further complicating the task. To address these issues, we propose Talos, a loss function that is specifically designed to optimize the Talos recommendation accuracy. Talos leverages a quantile technique that replaces the complex ranking-dependent operations into simpler comparisons between predicted scores and learned score thresholds. We further develop a sampling-based regression algorithm for efficient and accurate threshold estimation, and introduce a constraint term to maintain optimization stability by preventing score inflation. Additionally, we incorporate a tailored surrogate function to address discontinuity and enhance robustness against distribution shifts. Comprehensive theoretical analyzes and empirical experiments are conducted to demonstrate the effectiveness, efficiency, convergence, and distributional robustness of Talos. The code is available at https://github.com/cynthia-shengjia/WWW-2026-Talos.
LoD-Structured 3D Gaussian Splatting for Streaming Video Reconstruction
Jan 26, 2026Free-Viewpoint Video (FVV) reconstruction enables photorealistic and interactive 3D scene visualization; however, real-time streaming is often bottlenecked by sparse-view inputs, prohibitive training costs, and bandwidth constraints. While recent 3D Gaussian Splatting (3DGS) has advanced FVV due to its superior rendering speed, Streaming Free-Viewpoint Video (SFVV) introduces additional demands for rapid optimization, high-fidelity reconstruction under sparse constraints, and minimal storage footprints. To bridge this gap, we propose StreamLoD-GS, an LoD-based Gaussian Splatting framework designed specifically for SFVV. Our approach integrates three core innovations: 1) an Anchor- and Octree-based LoD-structured 3DGS with a hierarchical Gaussian dropout technique to ensure efficient and stable optimization while maintaining high-quality rendering; 2) a GMM-based motion partitioning mechanism that separates dynamic and static content, refining dynamic regions while preserving background stability; and 3) a quantized residual refinement framework that significantly reduces storage requirements without compromising visual fidelity. Extensive experiments demonstrate that StreamLoD-GS achieves competitive or state-of-the-art performance in terms of quality, efficiency, and storage.
TopKGAT: A Top-K Objective-Driven Architecture for Recommendation
Jan 26, 2026Recommendation systems (RS) aim to retrieve the top-K items most relevant to users, with metrics such as Precision@K and Recall@K commonly used to assess effectiveness. The architecture of an RS model acts as an inductive bias, shaping the patterns the model is inclined to learn. In recent years, numerous recommendation architectures have emerged, spanning traditional matrix factorization, deep neural networks, and graph neural networks. However, their designs are often not explicitly aligned with the top-K objective, thereby limiting their effectiveness. To address this limitation, we propose TopKGAT, a novel recommendation architecture directly derived from a differentiable approximation of top-K metrics. The forward computation of a single TopKGAT layer is intrinsically aligned with the gradient ascent dynamics of the Precision@K metric, enabling the model to naturally improve top-K recommendation accuracy. Structurally, TopKGAT resembles a graph attention network and can be implemented efficiently. Extensive experiments on four benchmark datasets demonstrate that TopKGAT consistently outperforms state-of-the-art baselines. The code is available at https://github.com/StupidThree/TopKGAT.
ReCreate: Reasoning and Creating Domain Agents Driven by Experience
Jan 16, 2026Large Language Model agents are reshaping the industrial landscape. However, most practical agents remain human-designed because tasks differ widely, making them labor-intensive to build. This situation poses a central question: can we automatically create and adapt domain agents in the wild? While several recent approaches have sought to automate agent creation, they typically treat agent generation as a black-box procedure and rely solely on final performance metrics to guide the process. Such strategies overlook critical evidence explaining why an agent succeeds or fails, and often require high computational costs. To address these limitations, we propose ReCreate, an experience-driven framework for the automatic creation of domain agents. ReCreate systematically leverages agent interaction histories, which provide rich concrete signals on both the causes of success or failure and the avenues for improvement. Specifically, we introduce an agent-as-optimizer paradigm that effectively learns from experience via three key components: (i) an experience storage and retrieval mechanism for on-demand inspection; (ii) a reasoning-creating synergy pipeline that maps execution experience into scaffold edits; and (iii) hierarchical updates that abstract instance-level details into reusable domain patterns. In experiments across diverse domains, ReCreate consistently outperforms human-designed agents and existing automated agent generation methods, even when starting from minimal seed scaffolds.
Towards Ancient Plant Seed Classification: A Benchmark Dataset and Baseline Model
Dec 20, 2025Understanding the dietary preferences of ancient societies and their evolution across periods and regions is crucial for revealing human-environment interactions. Seeds, as important archaeological artifacts, represent a fundamental subject of archaeobotanical research. However, traditional studies rely heavily on expert knowledge, which is often time-consuming and inefficient. Intelligent analysis methods have made progress in various fields of archaeology, but there remains a research gap in data and methods in archaeobotany, especially in the classification task of ancient plant seeds. To address this, we construct the first Ancient Plant Seed Image Classification (APS) dataset. It contains 8,340 images from 17 genus- or species-level seed categories excavated from 18 archaeological sites across China. In addition, we design a framework specifically for the ancient plant seed classification task (APSNet), which introduces the scale feature (size) of seeds based on learning fine-grained information to guide the network in discovering key "evidence" for sufficient classification. Specifically, we design a Size Perception and Embedding (SPE) module in the encoder part to explicitly extract size information for the purpose of complementing fine-grained information. We propose an Asynchronous Decoupled Decoding (ADD) architecture based on traditional progressive learning to decode features from both channel and spatial perspectives, enabling efficient learning of discriminative features. In both quantitative and qualitative analyses, our approach surpasses existing state-of-the-art image classification methods, achieving an accuracy of 90.5%. This demonstrates that our work provides an effective tool for large-scale, systematic archaeological research.
Animus3D: Text-driven 3D Animation via Motion Score Distillation
Dec 14, 2025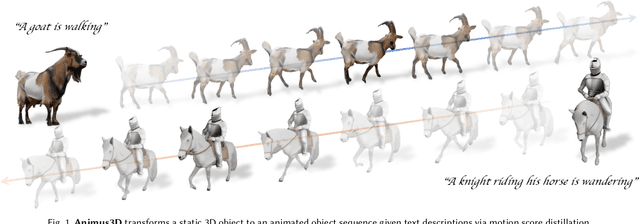
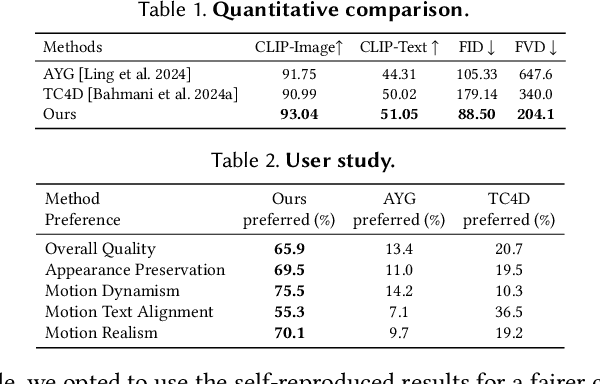
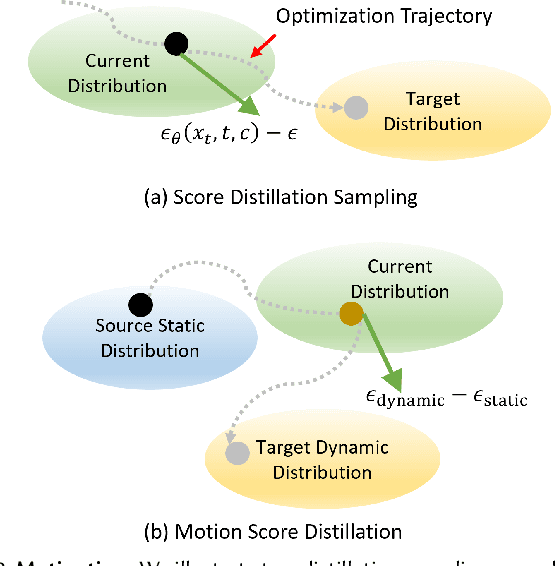
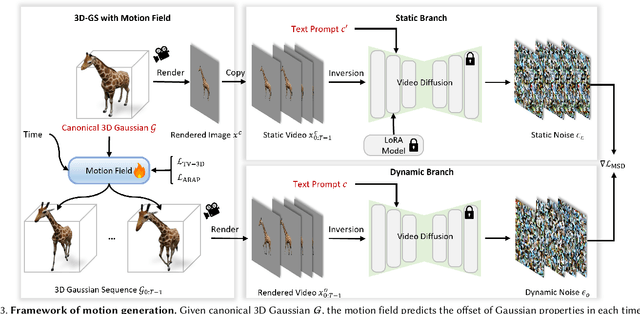
We present Animus3D, a text-driven 3D animation framework that generates motion field given a static 3D asset and text prompt. Previous methods mostly leverage the vanilla Score Distillation Sampling (SDS) objective to distill motion from pretrained text-to-video diffusion, leading to animations with minimal movement or noticeable jitter. To address this, our approach introduces a novel SDS alternative, Motion Score Distillation (MSD). Specifically, we introduce a LoRA-enhanced video diffusion model that defines a static source distribution rather than pure noise as in SDS, while another inversion-based noise estimation technique ensures appearance preservation when guiding motion. To further improve motion fidelity, we incorporate explicit temporal and spatial regularization terms that mitigate geometric distortions across time and space. Additionally, we propose a motion refinement module to upscale the temporal resolution and enhance fine-grained details, overcoming the fixed-resolution constraints of the underlying video model. Extensive experiments demonstrate that Animus3D successfully animates static 3D assets from diverse text prompts, generating significantly more substantial and detailed motion than state-of-the-art baselines while maintaining high visual integrity. Code will be released at https://qiisun.github.io/animus3d_page.
4DGS-Craft: Consistent and Interactive 4D Gaussian Splatting Editing
Oct 02, 2025
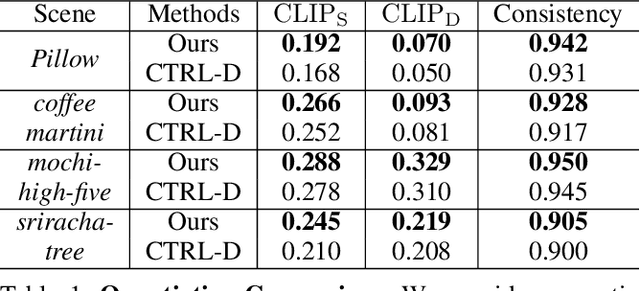

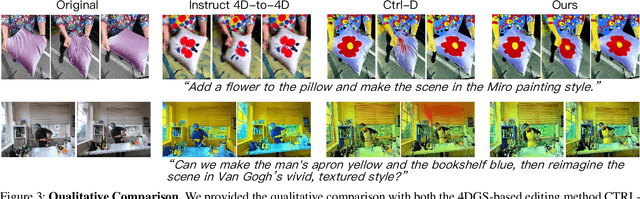
Recent advances in 4D Gaussian Splatting (4DGS) editing still face challenges with view, temporal, and non-editing region consistency, as well as with handling complex text instructions. To address these issues, we propose 4DGS-Craft, a consistent and interactive 4DGS editing framework. We first introduce a 4D-aware InstructPix2Pix model to ensure both view and temporal consistency. This model incorporates 4D VGGT geometry features extracted from the initial scene, enabling it to capture underlying 4D geometric structures during editing. We further enhance this model with a multi-view grid module that enforces consistency by iteratively refining multi-view input images while jointly optimizing the underlying 4D scene. Furthermore, we preserve the consistency of non-edited regions through a novel Gaussian selection mechanism, which identifies and optimizes only the Gaussians within the edited regions. Beyond consistency, facilitating user interaction is also crucial for effective 4DGS editing. Therefore, we design an LLM-based module for user intent understanding. This module employs a user instruction template to define atomic editing operations and leverages an LLM for reasoning. As a result, our framework can interpret user intent and decompose complex instructions into a logical sequence of atomic operations, enabling it to handle intricate user commands and further enhance editing performance. Compared to related works, our approach enables more consistent and controllable 4D scene editing. Our code will be made available upon acceptance.
OASIS: Harnessing Diffusion Adversarial Network for Ocean Salinity Imputation using Sparse Drifter Trajectories
Aug 29, 2025Ocean salinity plays a vital role in circulation, climate, and marine ecosystems, yet its measurement is often sparse, irregular, and noisy, especially in drifter-based datasets. Traditional approaches, such as remote sensing and optimal interpolation, rely on linearity and stationarity, and are limited by cloud cover, sensor drift, and low satellite revisit rates. While machine learning models offer flexibility, they often fail under severe sparsity and lack principled ways to incorporate physical covariates without specialized sensors. In this paper, we introduce the OceAn Salinity Imputation System (OASIS), a novel diffusion adversarial framework designed to address these challenges.